 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep mineralogical segmentation of thin section images based on QEMSCAN maps
May 22, 2025



Interpreting the mineralogical aspects of rock thin sections is an important task for oil and gas reservoirs evaluation. However, human analysis tend to be subjective and laborious. Technologies like QEMSCAN(R) are designed to automate the mineralogical mapping process, but also suffer from limitations like high monetary costs and time-consuming analysis. This work proposes a Convolutional Neural Network model for automatic mineralogical segmentation of thin section images of carbonate rocks. The model is able to mimic the QEMSCAN mapping itself in a low-cost, generalized and efficient manner. For this, the U-Net semantic segmentation architecture is trained on plane and cross polarized thin section images using the corresponding QEMSCAN maps as target, which is an approach not widely explored. The model was instructed to differentiate occurrences of Calcite, Dolomite, Mg-Clay Minerals, Quartz, Pores and the remaining mineral phases as an unique class named "Others", while it was validated on rock facies both seen and unseen during training, in order to address its generalization capability. Since the images and maps are provided in different resolutions, image registration was applied to align then spatially. The study reveals that the quality of the segmentation is very much dependent on these resolution differences and on the variety of learnable rock textures. However, it shows promising results, especially with regard to the proper delineation of minerals boundaries on solid textures and precise estimation of the minerals distributions, describing a nearly linear relationship between expected and predicted distributions, with coefficient of determination (R^2) superior to 0.97 for seen facies and 0.88 for unseen.
Deep Learning-based Type Identification of Volumetric MRI Sequences
Jun 06, 2021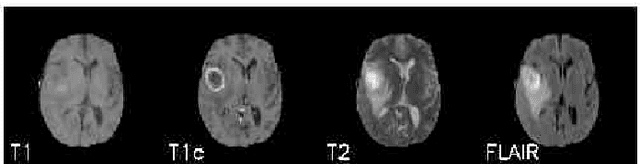
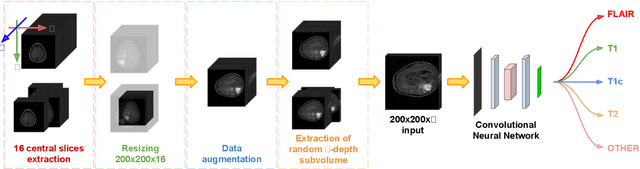
The analysis of Magnetic Resonance Imaging (MRI) sequences enables clinical professionals to monitor the progression of a brain tumor. As the interest for automatizing brain volume MRI analysis increases, it becomes convenient to have each sequence well identified. However, the unstandardized naming of MRI sequences makes their identification difficult for automated systems, as well as makes it difficult for researches to generate or use datasets for machine learning research. In the face of that, we propose a system for identifying types of brain MRI sequences based on deep learning. By training a Convolutional Neural Network (CNN) based on 18-layer ResNet architecture, our system can classify a volumetric brain MRI as a FLAIR, T1, T1c or T2 sequence, or whether it does not belong to any of these classes. The network was evaluated on publicly available datasets comprising both, pre-processed (BraTS dataset) and non-pre-processed (TCGA-GBM dataset), image types with diverse acquisition protocols, requiring only a few slices of the volume for training. Our system can classify among sequence types with an accuracy of 96.81%.
Deep traffic light detection by overlaying synthetic context on arbitrary natural images
Nov 10, 2020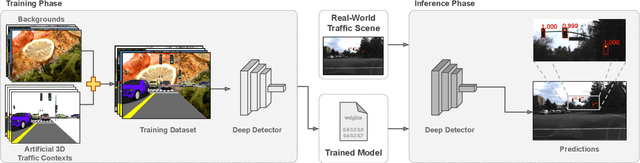
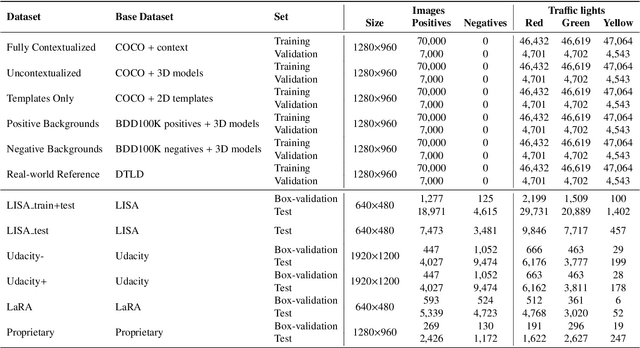

Deep neural networks come as an effective solution to many problems associated with autonomous driving. By providing real image samples with traffic context to the network, the model learns to detect and classify elements of interest, such as pedestrians, traffic signs, and traffic lights. However, acquiring and annotating real data can be extremely costly in terms of time and effort. In this context, we propose a method to generate artificial traffic-related training data for deep traffic light detectors. This data is generated using basic non-realistic computer graphics to blend fake traffic scenes on top of arbitrary image backgrounds that are not related to the traffic domain. Thus, a large amount of training data can be generated without annotation efforts. Furthermore, it also tackles the intrinsic data imbalance problem in traffic light datasets, caused mainly by the low amount of samples of the yellow state. Experiments show that it is possible to achieve results comparable to those obtained with real training data from the problem domain, yielding an average mAP and an average F1-score which are each nearly 4 p.p. higher than the respective metrics obtained with a real-world reference model.