 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Domain Object Detection Using Unsupervised Image Translation
Jan 16, 2026Unsupervised domain adaptation for object detection addresses the adaption of detectors trained in a source domain to work accurately in an unseen target domain. Recently, methods approaching the alignment of the intermediate features proven to be promising, achieving state-of-the-art results. However, these methods are laborious to implement and hard to interpret. Although promising, there is still room for improvements to close the performance gap toward the upper-bound (when training with the target data). In this work, we propose a method to generate an artificial dataset in the target domain to train an object detector. We employed two unsupervised image translators (CycleGAN and an AdaIN-based model) using only annotated data from the source domain and non-annotated data from the target domain. Our key contributions are the proposal of a less complex yet more effective method that also has an improved interpretability. Results on real-world scenarios for autonomous driving show significant improvements, outperforming state-of-the-art methods in most cases, further closing the gap toward the upper-bound.
Copycat CNN: Are Random Non-Labeled Data Enough to Steal Knowledge from Black-box Models?
Jan 21, 2021
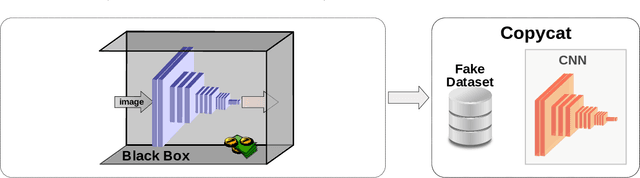

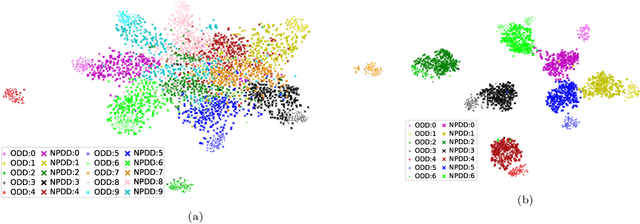
Convolutional neural networks have been successful lately enabling companies to develop neural-based products, which demand an expensive process, involving data acquisition and annotation; and model generation, usually requiring experts. With all these costs, companies are concerned about the security of their models against copies and deliver them as black-boxes accessed by APIs. Nonetheless, we argue that even black-box models still have some vulnerabilities. In a preliminary work, we presented a simple, yet powerful, method to copy black-box models by querying them with natural random images. In this work, we consolidate and extend the copycat method: (i) some constraints are waived; (ii) an extensive evaluation with several problems is performed; (iii) models are copied between different architectures; and, (iv) a deeper analysis is performed by looking at the copycat behavior. Results show that natural random images are effective to generate copycats for several problems.
* The code is available at https://github.com/jeiks/Stealing_DL_Models
Deep traffic light detection by overlaying synthetic context on arbitrary natural images
Nov 10, 2020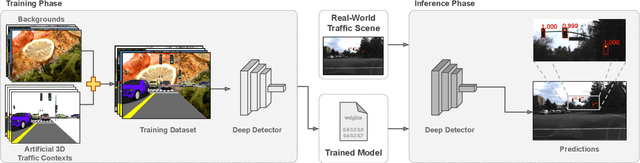
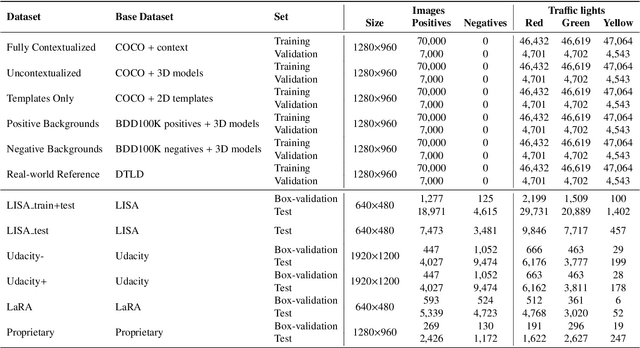

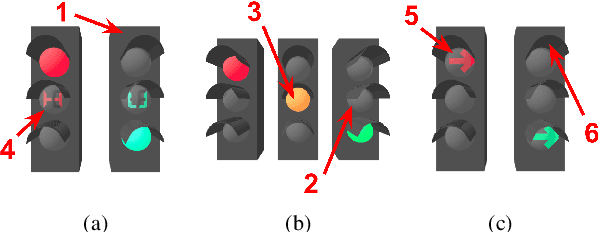
Deep neural networks come as an effective solution to many problems associated with autonomous driving. By providing real image samples with traffic context to the network, the model learns to detect and classify elements of interest, such as pedestrians, traffic signs, and traffic lights. However, acquiring and annotating real data can be extremely costly in terms of time and effort. In this context, we propose a method to generate artificial traffic-related training data for deep traffic light detectors. This data is generated using basic non-realistic computer graphics to blend fake traffic scenes on top of arbitrary image backgrounds that are not related to the traffic domain. Thus, a large amount of training data can be generated without annotation efforts. Furthermore, it also tackles the intrinsic data imbalance problem in traffic light datasets, caused mainly by the low amount of samples of the yellow state. Experiments show that it is possible to achieve results comparable to those obtained with real training data from the problem domain, yielding an average mAP and an average F1-score which are each nearly 4 p.p. higher than the respective metrics obtained with a real-world reference model.
Self-supervised Deep Reconstruction of Mixed Strip-shredded Text Documents
Jul 01, 2020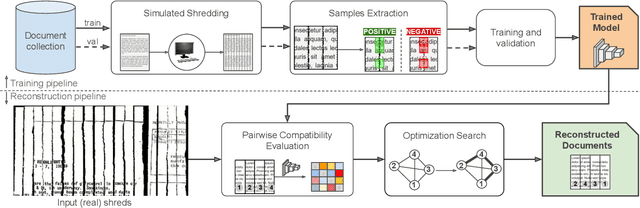

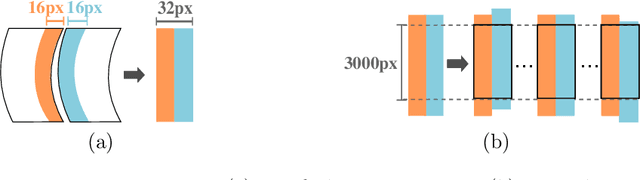
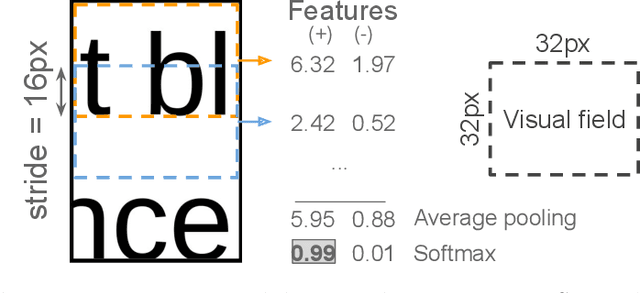
The reconstruction of shredded documents consists of coherently arranging fragments of paper (shreds) to recover the original document(s). A great challenge in computational reconstruction is to properly evaluate the compatibility between the shreds. While traditional pixel-based approaches are not robust to real shredding, more sophisticated solutions compromise significantly time performance. The solution presented in this work extends our previous deep learning method for single-page reconstruction to a more realistic/complex scenario: the reconstruction of several mixed shredded documents at once. In our approach, the compatibility evaluation is modeled as a two-class (valid or invalid) pattern recognition problem. The model is trained in a self-supervised manner on samples extracted from simulated-shredded documents, which obviates manual annotation. Experimental results on three datasets -- including a new collection of 100 strip-shredded documents produced for this work -- have shown that the proposed method outperforms the competing ones on complex scenarios, achieving accuracy superior to 90%.
Fast(er) Reconstruction of Shredded Text Documents via Self-Supervised Deep Asymmetric Metric Learning
Apr 29, 2020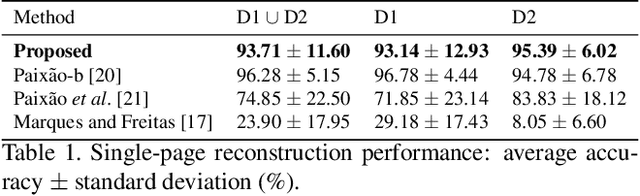
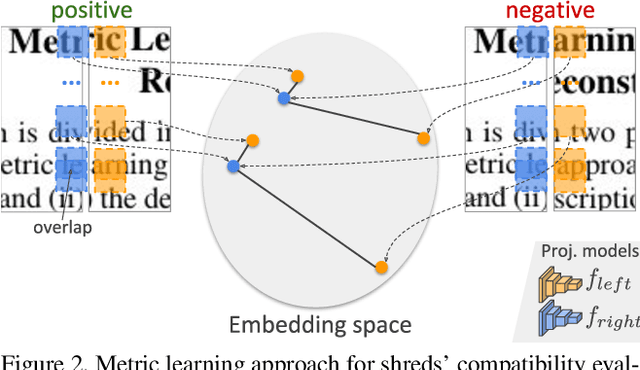
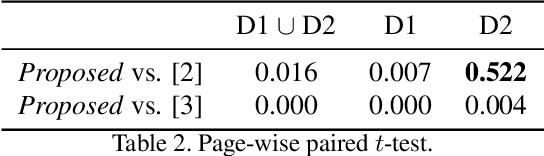
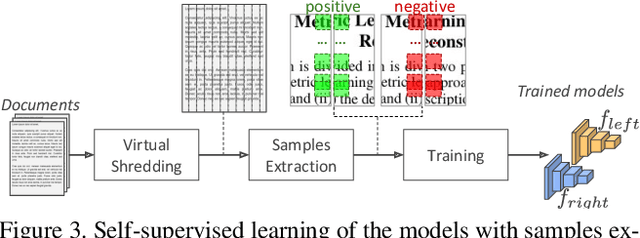
The reconstruction of shredded documents consists in arranging the pieces of paper (shreds) in order to reassemble the original aspect of such documents. This task is particularly relevant for supporting forensic investigation as documents may contain criminal evidence. As an alternative to the laborious and time-consuming manual process, several researchers have been investigating ways to perform automatic digital reconstruction. A central problem in automatic reconstruction of shredded documents is the pairwise compatibility evaluation of the shreds, notably for binary text documents. In this context, deep learning has enabled great progress for accurate reconstructions in the domain of mechanically-shredded documents. A sensitive issue, however, is that current deep model solutions require an inference whenever a pair of shreds has to be evaluated. This work proposes a scalable deep learning approach for measuring pairwise compatibility in which the number of inferences scales linearly (rather than quadratically) with the number of shreds. Instead of predicting compatibility directly, deep models are leveraged to asymmetrically project the raw shred content onto a common metric space in which distance is proportional to the compatibility. Experimental results show that our method has accuracy comparable to the state-of-the-art with a speed-up of about 22 times for a test instance with 505 shreds (20 mixed shredded-pages from different documents).
Effortless Deep Training for Traffic Sign Detection Using Templates and Arbitrary Natural Images
Jul 23, 2019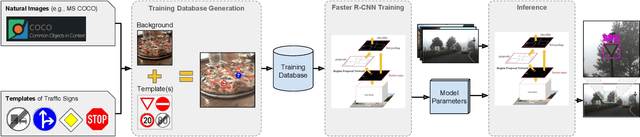



Deep learning has been successfully applied to several problems related to autonomous driving. Often, these solutions rely on large networks that require databases of real image samples of the problem (i.e., real world) for proper training. The acquisition of such real-world data sets is not always possible in the autonomous driving context, and sometimes their annotation is not feasible (e.g., takes too long or is too expensive). Moreover, in many tasks, there is an intrinsic data imbalance that most learning-based methods struggle to cope with. It turns out that traffic sign detection is a problem in which these three issues are seen altogether. In this work, we propose a novel database generation method that requires only (i) arbitrary natural images, i.e., requires no real image from the domain of interest, and (ii) templates of the traffic signs, i.e., templates synthetically created to illustrate the appearance of the category of a traffic sign. The effortlessly generated training database is shown to be effective for the training of a deep detector (such as Faster R-CNN) on German traffic signs, achieving 95.66% of mAP on average. In addition, the proposed method is able to detect traffic signs with an average precision, recall and F1-score of about 94%, 91% and 93%, respectively. The experiments surprisingly show that detectors can be trained with simple data generation methods and without problem domain data for the background, which is in the opposite direction of the common sense for deep learning.
Cross-Domain Car Detection Using Unsupervised Image-to-Image Translation: From Day to Night
Jul 19, 2019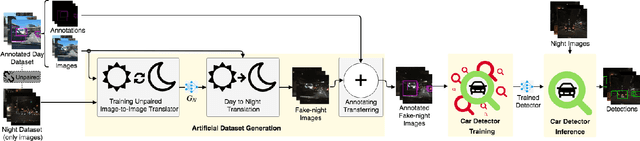
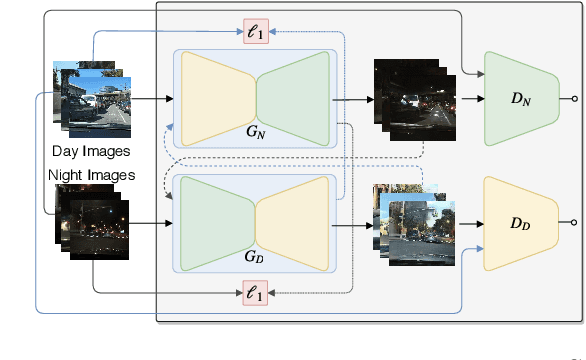


Deep learning techniques have enabled the emergence of state-of-the-art models to address object detection tasks. However, these techniques are data-driven, delegating the accuracy to the training dataset which must resemble the images in the target task. The acquisition of a dataset involves annotating images, an arduous and expensive process, generally requiring time and manual effort. Thus, a challenging scenario arises when the target domain of application has no annotated dataset available, making tasks in such situation to lean on a training dataset of a different domain. Sharing this issue, object detection is a vital task for autonomous vehicles where the large amount of driving scenarios yields several domains of application requiring annotated data for the training process. In this work, a method for training a car detection system with annotated data from a source domain (day images) without requiring the image annotations of the target domain (night images) is presented. For that, a model based on Generative Adversarial Networks (GANs) is explored to enable the generation of an artificial dataset with its respective annotations. The artificial dataset (fake dataset) is created translating images from day-time domain to night-time domain. The fake dataset, which comprises annotated images of only the target domain (night images), is then used to train the car detector model. Experimental results showed that the proposed method achieved significant and consistent improvements, including the increasing by more than 10% of the detection performance when compared to the training with only the available annotated data (i.e., day images).
Traffic Light Recognition Using Deep Learning and Prior Maps for Autonomous Cars
Jun 04, 2019
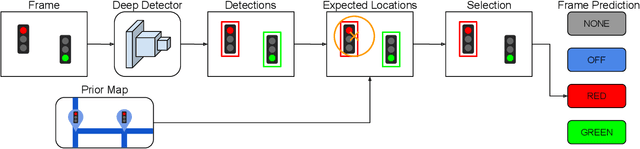

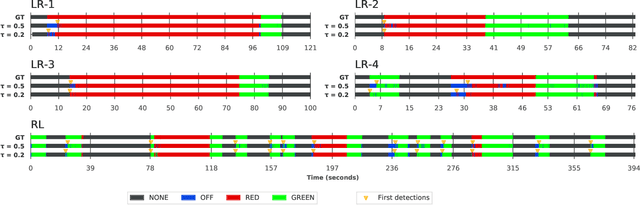
Autonomous terrestrial vehicles must be capable of perceiving traffic lights and recognizing their current states to share the streets with human drivers. Most of the time, human drivers can easily identify the relevant traffic lights. To deal with this issue, a common solution for autonomous cars is to integrate recognition with prior maps. However, additional solution is required for the detection and recognition of the traffic light. Deep learning techniques have showed great performance and power of generalization including traffic related problems. Motivated by the advances in deep learning, some recent works leveraged some state-of-the-art deep detectors to locate (and further recognize) traffic lights from 2D camera images. However, none of them combine the power of the deep learning-based detectors with prior maps to recognize the state of the relevant traffic lights. Based on that, this work proposes to integrate the power of deep learning-based detection with the prior maps used by our car platform IARA (acronym for Intelligent Autonomous Robotic Automobile) to recognize the relevant traffic lights of predefined routes. The process is divided in two phases: an offline phase for map construction and traffic lights annotation; and an online phase for traffic light recognition and identification of the relevant ones. The proposed system was evaluated on five test cases (routes) in the city of Vit\'oria, each case being composed of a video sequence and a prior map with the relevant traffic lights for the route. Results showed that the proposed technique is able to correctly identify the relevant traffic light along the trajectory.
Ego-Lane Analysis System (ELAS): Dataset and Algorithms
Jun 15, 2018
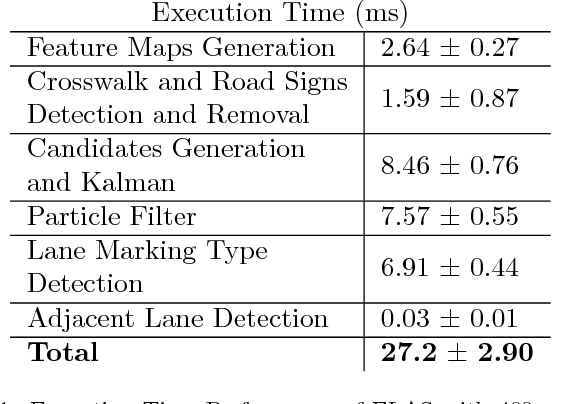
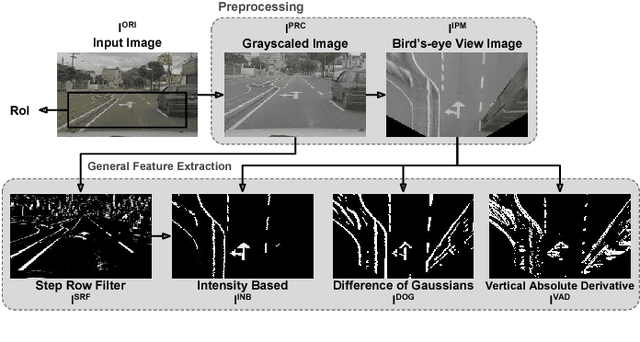
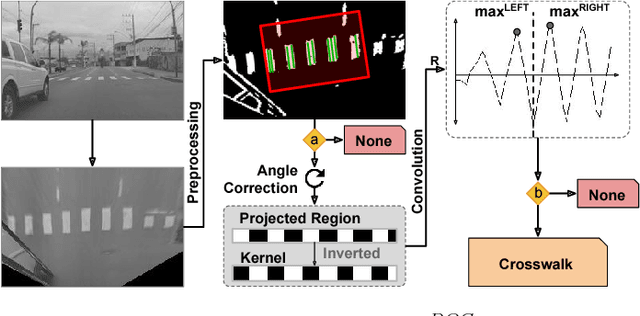
Decreasing costs of vision sensors and advances in embedded hardware boosted lane related research detection, estimation, and tracking in the past two decades. The interest in this topic has increased even more with the demand for advanced driver assistance systems (ADAS) and self-driving cars. Although extensively studied independently, there is still need for studies that propose a combined solution for the multiple problems related to the ego-lane, such as lane departure warning (LDW), lane change detection, lane marking type (LMT) classification, road markings detection and classification, and detection of adjacent lanes (i.e., immediate left and right lanes) presence. In this paper, we propose a real-time Ego-Lane Analysis System (ELAS) capable of estimating ego-lane position, classifying LMTs and road markings, performing LDW and detecting lane change events. The proposed vision-based system works on a temporal sequence of images. Lane marking features are extracted in perspective and Inverse Perspective Mapping (IPM) images that are combined to increase robustness. The final estimated lane is modeled as a spline using a combination of methods (Hough lines with Kalman filter and spline with particle filter). Based on the estimated lane, all other events are detected. To validate ELAS and cover the lack of lane datasets in the literature, a new dataset with more than 20 different scenes (in more than 15,000 frames) and considering a variety of scenarios (urban road, highways, traffic, shadows, etc.) was created. The dataset was manually annotated and made publicly available to enable evaluation of several events that are of interest for the research community (i.e., lane estimation, change, and centering; road markings; intersections; LMTs; crosswalks and adjacent lanes). ELAS achieved high detection rates in all real-world events and proved to be ready for real-time applications.
* 13 pages, 17 figures, github.com/rodrigoberriel/ego-lane-analysis-system, and published by Image and Vision Computing (IMAVIS)
Copycat CNN: Stealing Knowledge by Persuading Confession with Random Non-Labeled Data
Jun 14, 2018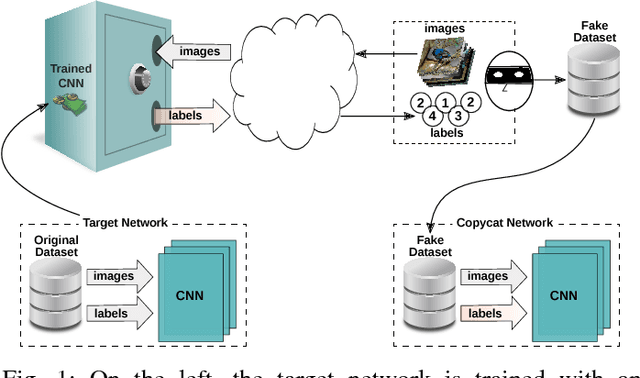
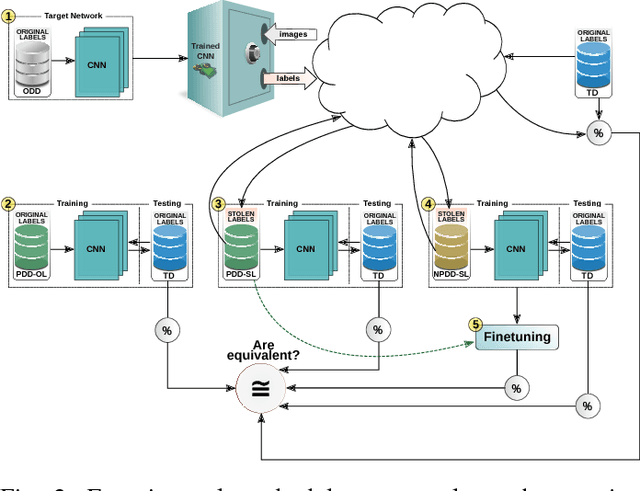
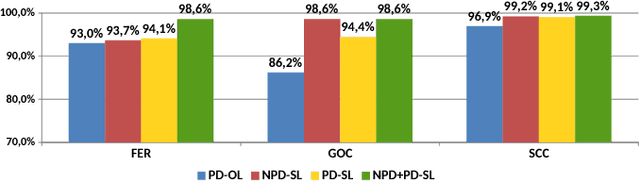
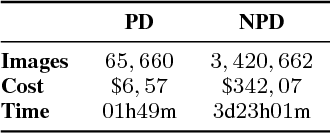
In the past few years, Convolutional Neural Networks (CNNs) have been achieving state-of-the-art performance on a variety of problems. Many companies employ resources and money to generate these models and provide them as an API, therefore it is in their best interest to protect them, i.e., to avoid that someone else copies them. Recent studies revealed that state-of-the-art CNNs are vulnerable to adversarial examples attacks, and this weakness indicates that CNNs do not need to operate in the problem domain (PD). Therefore, we hypothesize that they also do not need to be trained with examples of the PD in order to operate in it. Given these facts, in this paper, we investigate if a target black-box CNN can be copied by persuading it to confess its knowledge through random non-labeled data. The copy is two-fold: i) the target network is queried with random data and its predictions are used to create a fake dataset with the knowledge of the network; and ii) a copycat network is trained with the fake dataset and should be able to achieve similar performance as the target network. This hypothesis was evaluated locally in three problems (facial expression, object, and crosswalk classification) and against a cloud-based API. In the copy attacks, images from both non-problem domain and PD were used. All copycat networks achieved at least 93.7% of the performance of the original models with non-problem domain data, and at least 98.6% using additional data from the PD. Additionally, the copycat CNN successfully copied at least 97.3% of the performance of the Microsoft Azure Emotion API. Our results show that it is possible to create a copycat CNN by simply querying a target network as black-box with random non-labeled data.