 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep mineralogical segmentation of thin section images based on QEMSCAN maps
May 22, 2025



Interpreting the mineralogical aspects of rock thin sections is an important task for oil and gas reservoirs evaluation. However, human analysis tend to be subjective and laborious. Technologies like QEMSCAN(R) are designed to automate the mineralogical mapping process, but also suffer from limitations like high monetary costs and time-consuming analysis. This work proposes a Convolutional Neural Network model for automatic mineralogical segmentation of thin section images of carbonate rocks. The model is able to mimic the QEMSCAN mapping itself in a low-cost, generalized and efficient manner. For this, the U-Net semantic segmentation architecture is trained on plane and cross polarized thin section images using the corresponding QEMSCAN maps as target, which is an approach not widely explored. The model was instructed to differentiate occurrences of Calcite, Dolomite, Mg-Clay Minerals, Quartz, Pores and the remaining mineral phases as an unique class named "Others", while it was validated on rock facies both seen and unseen during training, in order to address its generalization capability. Since the images and maps are provided in different resolutions, image registration was applied to align then spatially. The study reveals that the quality of the segmentation is very much dependent on these resolution differences and on the variety of learnable rock textures. However, it shows promising results, especially with regard to the proper delineation of minerals boundaries on solid textures and precise estimation of the minerals distributions, describing a nearly linear relationship between expected and predicted distributions, with coefficient of determination (R^2) superior to 0.97 for seen facies and 0.88 for unseen.
Deep learning for lithological classification of carbonate rock micro-CT images
Jul 30, 2020
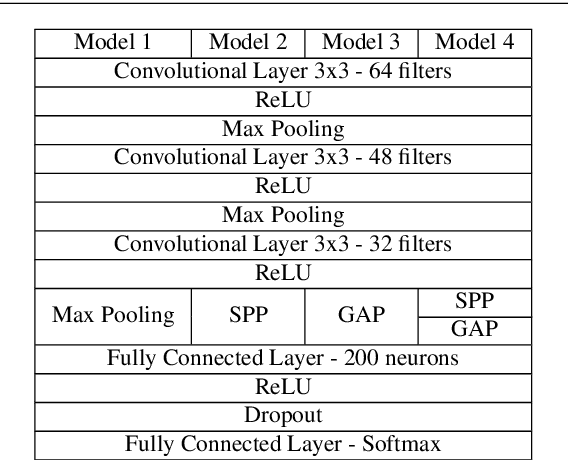

In addition to the ongoing development, pre-salt carbonate reservoir characterization remains a challenge, primarily due to inherent geological particularities. These challenges stimulate the use of well-established technologies, such as artificial intelligence algorithms, for image classification tasks. Therefore, this work intends to present an application of deep learning techniques to identify patterns in Brazilian pre-salt carbonate rock microtomographic images, thus making possible lithological classification. Four convolutional neural network models were proposed. The first model includes three convolutional layers followed by fully connected layers and is used as a base model for the following proposals. In the next two models, we replace the max pooling layer with a spatial pyramid pooling and a global average pooling layer. The last model uses a combination of spatial pyramid pooling followed by global average pooling in place of the last pooling layer. All models are compared using original images, when possible, as well as resized images. The dataset consists of 6,000 images from three different classes. The model performances were evaluated by each image individually, as well as by the most frequently predicted class for each sample. According to accuracy, Model 2 trained on resized images achieved the best results, reaching an average of 75.54% for the first evaluation approach and an average of 81.33% for the second. We developed a workflow to automate and accelerate the lithology classification of Brazilian pre-salt carbonate samples by categorizing microtomographic images using deep learning algorithms in a non-destructive way.
On a method for Rock Classification using Textural Features and Genetic Optimization
Aug 17, 2017

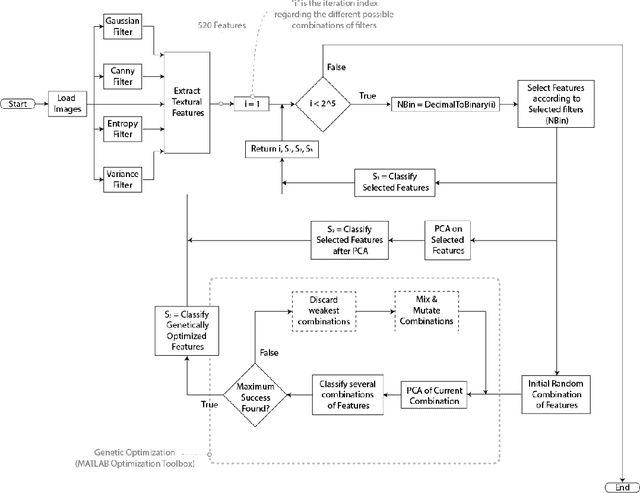

In this work we present a method to classify a set of rock textures based on a Spectral Analysis and the extraction of the texture Features of the resulted images. Up to 520 features were tested using 4 different filters and all 31 different combinations were verified. The classification process relies on a Naive Bayes classifier. We performed two kinds of optimizations: statistical optimization with covariance-based Principal Component Analysis (PCA) and a genetic optimization, for 10,000 randomly defined samples, achieving a final maximum classification success of 91% against the original 70% success ratio (without any optimization nor filters used). After the optimization 9 types of features emerged as most relevant.
* 13 pages, 3 figures, 1 appendix. Replaced to match the published version