 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-MLNet: Enhanced Mutual Learning for Universal Domain Adaptation with Sample-Specific Weighting
Sep 10, 2025Universal Domain Adaptation (UniDA) seeks to transfer knowledge from a labeled source to an unlabeled target domain without assuming any relationship between their label sets, requiring models to classify known samples while rejecting unknown ones. Advanced methods like Mutual Learning Network (MLNet) use a bank of one-vs-all classifiers adapted via Open-set Entropy Minimization (OEM). However, this strategy treats all classifiers equally, diluting the learning signal. We propose the Enhanced Mutual Learning Network (E-MLNet), which integrates a dynamic weighting strategy to OEM. By leveraging the closed-set classifier's predictions, E-MLNet focuses adaptation on the most relevant class boundaries for each target sample, sharpening the distinction between known and unknown classes. We conduct extensive experiments on four challenging benchmarks: Office-31, Office-Home, VisDA-2017, and ImageCLEF. The results demonstrate that E-MLNet achieves the highest average H-scores on VisDA and ImageCLEF and exhibits superior robustness over its predecessor. E-MLNet outperforms the strong MLNet baseline in the majority of individual adaptation tasks -- 22 out of 31 in the challenging Open-Partial DA setting and 19 out of 31 in the Open-Set DA setting -- confirming the benefits of our focused adaptation strategy.
Beyond the Known: Enhancing Open Set Domain Adaptation with Unknown Exploration
Dec 24, 2024Convolutional neural networks (CNNs) can learn directly from raw data, resulting in exceptional performance across various research areas. However, factors present in non-controllable environments such as unlabeled datasets with varying levels of domain and category shift can reduce model accuracy. The Open Set Domain Adaptation (OSDA) is a challenging problem that arises when both of these issues occur together. Existing OSDA approaches in literature only align known classes or use supervised training to learn unknown classes as a single new category. In this work, we introduce a new approach to improve OSDA techniques by extracting a set of high-confidence unknown instances and using it as a hard constraint to tighten the classification boundaries. Specifically, we use a new loss constraint that is evaluated in three different ways: (1) using pristine negative instances directly; (2) using data augmentation techniques to create randomly transformed negatives; and (3) with generated synthetic negatives containing adversarial features. We analyze different strategies to improve the discriminator and the training of the Generative Adversarial Network (GAN) used to generate synthetic negatives. We conducted extensive experiments and analysis on OVANet using three widely-used public benchmarks, the Office-31, Office-Home, and VisDA datasets. We were able to achieve similar H-score to other state-of-the-art methods, while increasing the accuracy on unknown categories.
TransferAttn: Transferable-guided Attention Is All You Need for Video Domain Adaptation
Jul 01, 2024Unsupervised domain adaptation (UDA) in videos is a challenging task that remains not well explored compared to image-based UDA techniques. Although vision transformers (ViT) achieve state-of-the-art performance in many computer vision tasks, their use in video domain adaptation has still been little explored. Our key idea is to use the transformer layers as a feature encoder and incorporate spatial and temporal transferability relationships into the attention mechanism. A Transferable-guided Attention (TransferAttn) framework is then developed to exploit the capacity of the transformer to adapt cross-domain knowledge from different backbones. To improve the transferability of ViT, we introduce a novel and effective module named Domain Transferable-guided Attention Block~(DTAB). DTAB compels ViT to focus on the spatio-temporal transferability relationship among video frames by changing the self-attention mechanism to a transferability attention mechanism. Extensive experiments on UCF-HMDB, Kinetics-Gameplay, and Kinetics-NEC Drone datasets with different backbones, like ResNet101, I3D, and STAM, verify the effectiveness of TransferAttn compared with state-of-the-art approaches. Also, we demonstrate that DTAB yields performance gains when applied to other state-of-the-art transformer-based UDA methods from both video and image domains. The code will be made freely available.
CNNs for JPEGs: A Study in Computational Cost
Sep 22, 2023Convolutional neural networks (CNNs) have achieved astonishing advances over the past decade, defining state-of-the-art in several computer vision tasks. CNNs are capable of learning robust representations of the data directly from the RGB pixels. However, most image data are usually available in compressed format, from which the JPEG is the most widely used due to transmission and storage purposes demanding a preliminary decoding process that have a high computational load and memory usage. For this reason, deep learning methods capable of learning directly from the compressed domain have been gaining attention in recent years. Those methods usually extract a frequency domain representation of the image, like DCT, by a partial decoding, and then make adaptation to typical CNNs architectures to work with them. One limitation of these current works is that, in order to accommodate the frequency domain data, the modifications made to the original model increase significantly their amount of parameters and computational complexity. On one hand, the methods have faster preprocessing, since the cost of fully decoding the images is avoided, but on the other hand, the cost of passing the images though the model is increased, mitigating the possible upside of accelerating the method. In this paper, we propose a further study of the computational cost of deep models designed for the frequency domain, evaluating the cost of decoding and passing the images through the network. We also propose handcrafted and data-driven techniques for reducing the computational complexity and the number of parameters for these models in order to keep them similar to their RGB baselines, leading to efficient models with a better trade off between computational cost and accuracy.
Budget-Aware Pruning: Handling Multiple Domains with Less Parameters
Sep 20, 2023Deep learning has achieved state-of-the-art performance on several computer vision tasks and domains. Nevertheless, it still has a high computational cost and demands a significant amount of parameters. Such requirements hinder the use in resource-limited environments and demand both software and hardware optimization. Another limitation is that deep models are usually specialized into a single domain or task, requiring them to learn and store new parameters for each new one. Multi-Domain Learning (MDL) attempts to solve this problem by learning a single model that is capable of performing well in multiple domains. Nevertheless, the models are usually larger than the baseline for a single domain. This work tackles both of these problems: our objective is to prune models capable of handling multiple domains according to a user-defined budget, making them more computationally affordable while keeping a similar classification performance. We achieve this by encouraging all domains to use a similar subset of filters from the baseline model, up to the amount defined by the user's budget. Then, filters that are not used by any domain are pruned from the network. The proposed approach innovates by better adapting to resource-limited devices while, to our knowledge, being the only work that handles multiple domains at test time with fewer parameters and lower computational complexity than the baseline model for a single domain.
Parameter Sharing in Budget-Aware Adapters for Multi-Domain Learning
Oct 14, 2022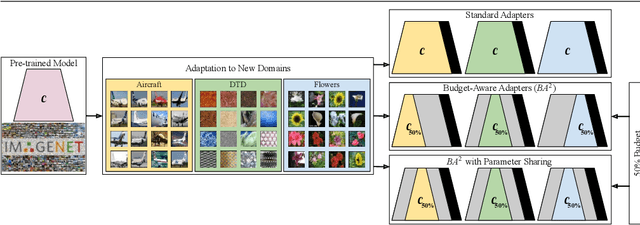
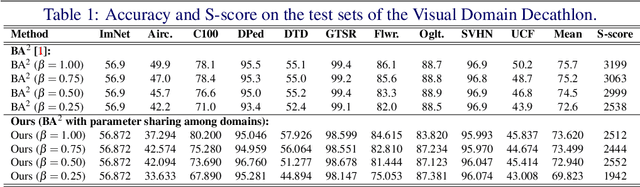
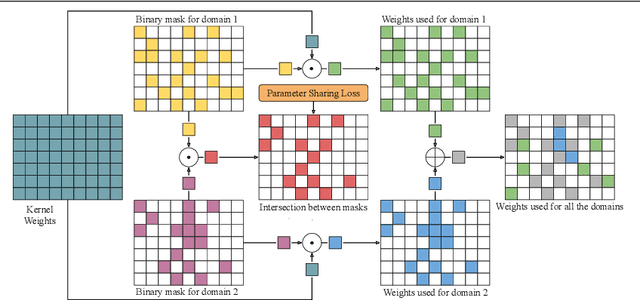
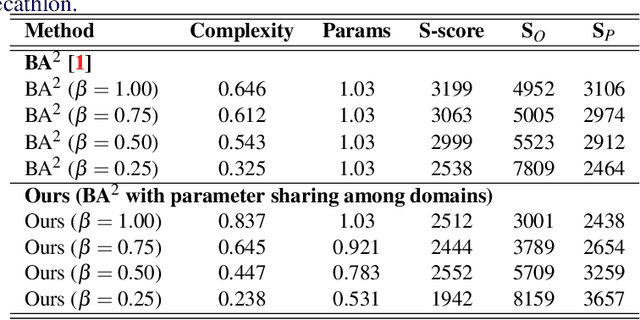
Deep learning has achieved state-of-the-art performance on several computer vision tasks and domains. Nevertheless, it still demands a high computational cost and a significant amount of parameters that need to be learned for each new domain. Such requirements hinder the use in resource-limited environments and demand both software and hardware optimization. Multi-domain learning addresses this problem by adapting to new domains while retaining the knowledge of the original domain. One limitation of most multi-domain learning approaches is that they usually are not designed for taking into account the resources available to the user. Recently, some works that can reduce computational complexity and amount of parameters to fit the user needs have been proposed, but they need the entire original model to handle all the domains together. This work proposes a method capable of adapting to a user-defined budget while encouraging parameter sharing among domains. Hence, filters that are not used by any domain can be pruned from the network at test time. The proposed approach innovates by better adapting to resource-limited devices while being able to handle multiple domains at test time with fewer parameters and lower computational complexity than the baseline model.
Less is More: Accelerating Faster Neural Networks Straight from JPEG
Apr 01, 2021

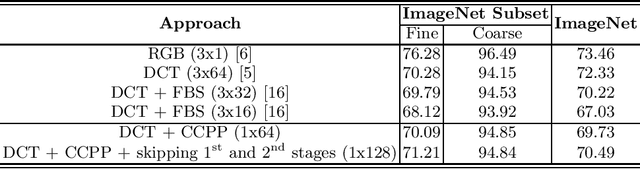
Most image data available are often stored in a compressed format, from which JPEG is the most widespread. To feed this data on a convolutional neural network (CNN), a preliminary decoding process is required to obtain RGB pixels, demanding a high computational load and memory usage. For this reason, the design of CNNs for processing JPEG compressed data has gained attention in recent years. In most existing works, typical CNN architectures are adapted to facilitate the learning with the DCT coefficients rather than RGB pixels. Although they are effective, their architectural changes either raise the computational costs or neglect relevant information from DCT inputs. In this paper, we examine different ways of speeding up CNNs designed for DCT inputs, exploiting learning strategies to reduce the computational complexity by taking full advantage of DCT inputs. Our experiments were conducted on the ImageNet dataset. Results show that learning how to combine all DCT inputs in a data-driven fashion is better than discarding them by hand, and its combination with a reduction of layers has proven to be effective for reducing the computational costs while retaining accuracy.
Deep Learning Towards Edge Computing: Neural Networks Straight from Compressed Data
Dec 26, 2020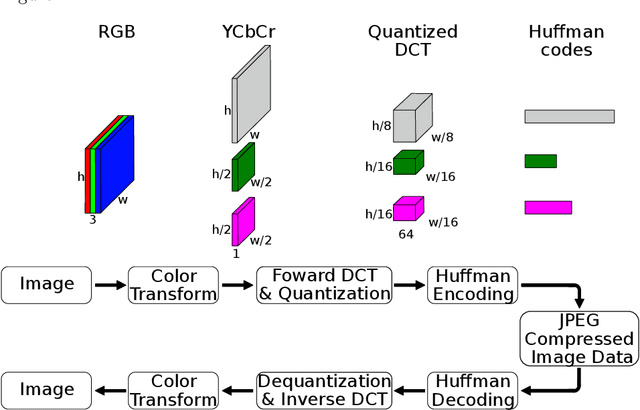



Due to the popularization and grow in computational power of mobile phones, as well as advances in artificial intelligence, many intelligent applications have been developed, meaningfully enriching people's life. For this reason, there is a growing interest in the area of edge intelligence, that aims to push the computation of data to the edges of the network, in order to make those applications more efficient and secure. Many intelligent applications rely on deep learning models, like convolutional neural networks (CNNs). Over the past decade, they have achieved state-of-the-art performance in many computer vision tasks. To increase the performance of these methods, the trend has been to use increasingly deeper architectures and with more parameters, leading to a high computational cost. Indeed, this is one of the main problems faced by deep architectures, limiting their applicability in domains with limited computational resources, like edge devices. To alleviate the computational complexity, we propose a deep neural network capable of learning straight from the relevant information pertaining to visual content readily available in the compressed representation used for image and video storage and transmission. The novelty of our approach is that it was designed to operate directly on frequency domain data, learning with DCT coefficients rather than RGB pixels. This enables to save high computational load in full decoding the data stream and therefore greatly speed up the processing time, which has become a big bottleneck of deep learning. We evaluated our network on two challenging tasks: (1) image classification on the ImageNet dataset and (2) video classification on the UCF-101 and HMDB-51 datasets. Our results demonstrate comparable effectiveness to the state-of-the-art methods in terms of accuracy, with the advantage of being more computationally efficient.
Faster and Accurate Compressed Video Action Recognition Straight from the Frequency Domain
Dec 26, 2020



Human action recognition has become one of the most active field of research in computer vision due to its wide range of applications, like surveillance, medical, industrial environments, smart homes, among others. Recently, deep learning has been successfully used to learn powerful and interpretable features for recognizing human actions in videos. Most of the existing deep learning approaches have been designed for processing video information as RGB image sequences. For this reason, a preliminary decoding process is required, since video data are often stored in a compressed format. However, a high computational load and memory usage is demanded for decoding a video. To overcome this problem, we propose a deep neural network capable of learning straight from compressed video. Our approach was evaluated on two public benchmarks, the UCF-101 and HMDB-51 datasets, demonstrating comparable recognition performance to the state-of-the-art methods, with the advantage of running up to 2 times faster in terms of inference speed.