 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Known: Enhancing Open Set Domain Adaptation with Unknown Exploration
Dec 24, 2024Convolutional neural networks (CNNs) can learn directly from raw data, resulting in exceptional performance across various research areas. However, factors present in non-controllable environments such as unlabeled datasets with varying levels of domain and category shift can reduce model accuracy. The Open Set Domain Adaptation (OSDA) is a challenging problem that arises when both of these issues occur together. Existing OSDA approaches in literature only align known classes or use supervised training to learn unknown classes as a single new category. In this work, we introduce a new approach to improve OSDA techniques by extracting a set of high-confidence unknown instances and using it as a hard constraint to tighten the classification boundaries. Specifically, we use a new loss constraint that is evaluated in three different ways: (1) using pristine negative instances directly; (2) using data augmentation techniques to create randomly transformed negatives; and (3) with generated synthetic negatives containing adversarial features. We analyze different strategies to improve the discriminator and the training of the Generative Adversarial Network (GAN) used to generate synthetic negatives. We conducted extensive experiments and analysis on OVANet using three widely-used public benchmarks, the Office-31, Office-Home, and VisDA datasets. We were able to achieve similar H-score to other state-of-the-art methods, while increasing the accuracy on unknown categories.
Tightening Classification Boundaries in Open Set Domain Adaptation through Unknown Exploitation
Sep 16, 2023Convolutional Neural Networks (CNNs) have brought revolutionary advances to many research areas due to their capacity of learning from raw data. However, when those methods are applied to non-controllable environments, many different factors can degrade the model's expected performance, such as unlabeled datasets with different levels of domain shift and category shift. Particularly, when both issues occur at the same time, we tackle this challenging setup as Open Set Domain Adaptation (OSDA) problem. In general, existing OSDA approaches focus their efforts only on aligning known classes or, if they already extract possible negative instances, use them as a new category learned with supervision during the course of training. We propose a novel way to improve OSDA approaches by extracting a high-confidence set of unknown instances and using it as a hard constraint to tighten the classification boundaries of OSDA methods. Especially, we adopt a new loss constraint evaluated in three different means, (1) directly with the pristine negative instances; (2) with randomly transformed negatives using data augmentation techniques; and (3) with synthetically generated negatives containing adversarial features. We assessed all approaches in an extensive set of experiments based on OVANet, where we could observe consistent improvements for two public benchmarks, the Office-31 and Office-Home datasets, yielding absolute gains of up to 1.3% for both Accuracy and H-Score on Office-31 and 5.8% for Accuracy and 4.7% for H-Score on Office-Home.
Improving Transferability of Domain Adaptation Networks Through Domain Alignment Layers
Sep 06, 2021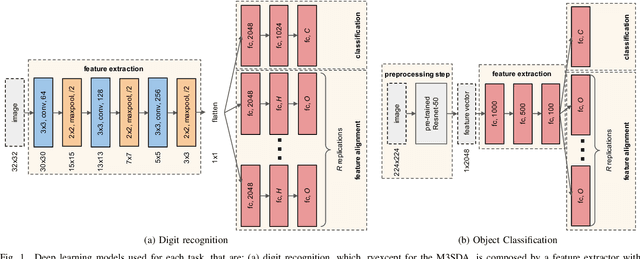
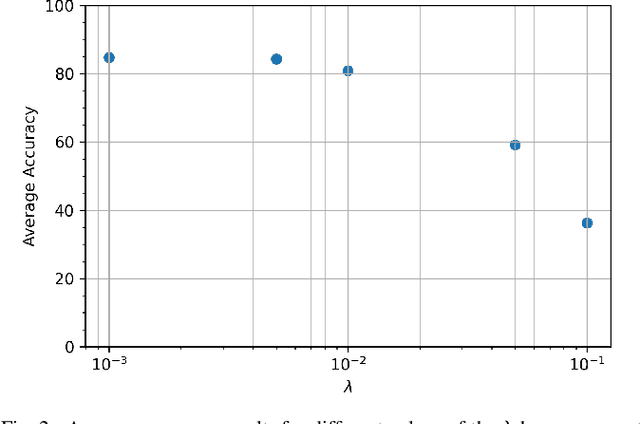

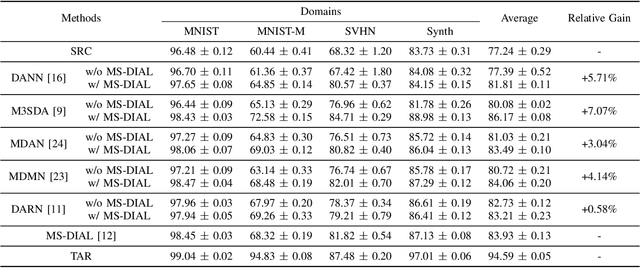
Deep learning (DL) has been the primary approach used in various computer vision tasks due to its relevant results achieved on many tasks. However, on real-world scenarios with partially or no labeled data, DL methods are also prone to the well-known domain shift problem. Multi-source unsupervised domain adaptation (MSDA) aims at learning a predictor for an unlabeled domain by assigning weak knowledge from a bag of source models. However, most works conduct domain adaptation leveraging only the extracted features and reducing their domain shift from the perspective of loss function designs. In this paper, we argue that it is not sufficient to handle domain shift only based on domain-level features, but it is also essential to align such information on the feature space. Unlike previous works, we focus on the network design and propose to embed Multi-Source version of DomaIn Alignment Layers (MS-DIAL) at different levels of the predictor. These layers are designed to match the feature distributions between different domains and can be easily applied to various MSDA methods. To show the robustness of our approach, we conducted an extensive experimental evaluation considering two challenging scenarios: digit recognition and object classification. The experimental results indicated that our approach can improve state-of-the-art MSDA methods, yielding relative gains of up to +30.64% on their classification accuracies.