 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Brazilian Sign Language Recognition through Skeleton Image Representation
Paper and Code
Apr 29, 2024


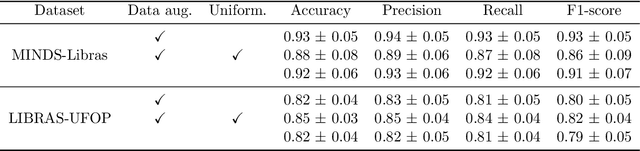
Effective communication is paramount for the inclusion of deaf individuals in society. However, persistent communication barriers due to limited Sign Language (SL) knowledge hinder their full participation. In this context, Sign Language Recognition (SLR) systems have been developed to improve communication between signing and non-signing individuals. In particular, there is the problem of recognizing isolated signs (Isolated Sign Language Recognition, ISLR) of great relevance in the development of vision-based SL search engines, learning tools, and translation systems. This work proposes an ISLR approach where body, hands, and facial landmarks are extracted throughout time and encoded as 2-D images. These images are processed by a convolutional neural network, which maps the visual-temporal information into a sign label. Experimental results demonstrate that our method surpassed the state-of-the-art in terms of performance metrics on two widely recognized datasets in Brazilian Sign Language (LIBRAS), the primary focus of this study. In addition to being more accurate, our method is more time-efficient and easier to train due to its reliance on a simpler network architecture and solely RGB data as input.