Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Self-taught Learning-based Representations for Facial Emotion Recognition
Apr 26, 2022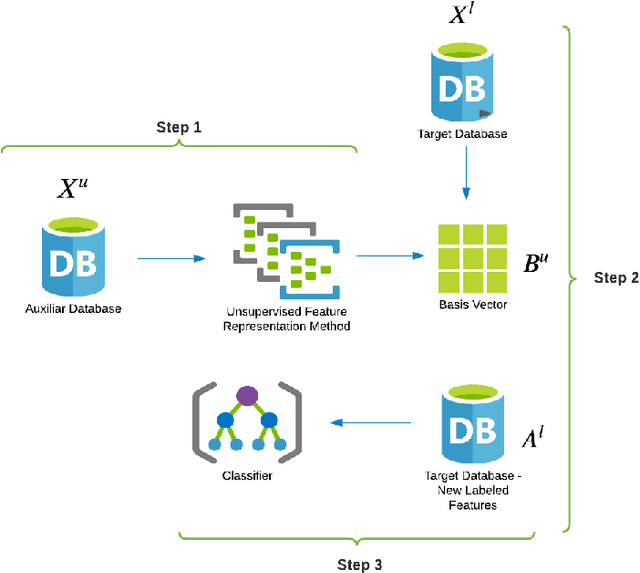
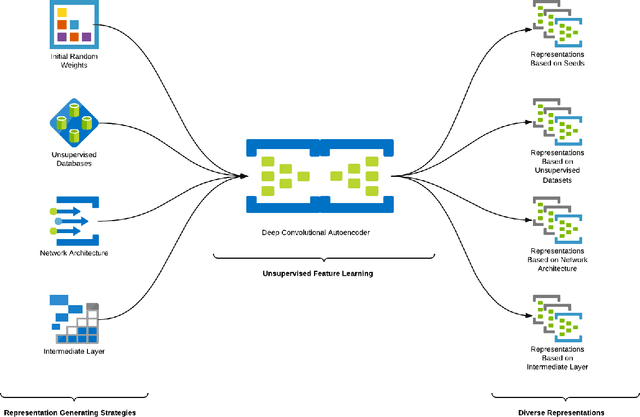


This work describes different strategies to generate unsupervised representations obtained through the concept of self-taught learning for facial emotion recognition (FER). The idea is to create complementary representations promoting diversity by varying the autoencoders' initialization, architecture, and training data. SVM, Bagging, Random Forest, and a dynamic ensemble selection method are evaluated as final classification methods. Experimental results on Jaffe and Cohn-Kanade datasets using a leave-one-subject-out protocol show that FER methods based on the proposed diverse representations compare favorably against state-of-the-art approaches that also explore unsupervised feature learning.
* 8 pages
Via