 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Image-to-Image Translation via a Rectified Flow Reformulation
Mar 20, 2026In this work, we propose Image-to-Image Rectified Flow Reformulation (I2I-RFR), a practical plug-in reformulation that recasts standard I2I regression networks as continuous-time transport models. While pixel-wise I2I regression is simple, stable, and easy to adapt across tasks, it often over-smooths ill-posed and multimodal targets, whereas generative alternatives often require additional components, task-specific tuning, and more complex training and inference pipelines. Our method augments the backbone input by channel-wise concatenation with a noise-corrupted version of the ground-truth target and optimizes a simple t-reweighted pixel loss. This objective admits a rectified-flow interpretation via an induced velocity field, enabling ODE-based progressive refinement at inference time while largely preserving the standard supervised training pipeline. In most cases, adopting I2I-RFR requires only expanding the input channels, and inference can be performed with a few explicit solver steps (e.g., 3 steps) without distillation. Extensive experiments across multiple image-to-image translation and video restoration tasks show that I2I-RFR generally improves performance across a wide range of tasks and backbones, with particularly clear gains in perceptual quality and detail preservation. Overall, I2I-RFR provides a lightweight way to incorporate continuous-time refinement into conventional I2I models without requiring a heavy generative pipeline.
From Punchlines to Predictions: A Metric to Assess LLM Performance in Identifying Humor in Stand-Up Comedy
Apr 12, 2025Comedy serves as a profound reflection of the times we live in and is a staple element of human interactions. In light of the widespread adoption of Large Language Models (LLMs), the intersection of humor and AI has become no laughing matter. Advancements in the naturalness of human-computer interaction correlates with improvements in AI systems' abilities to understand humor. In this study, we assess the ability of models in accurately identifying humorous quotes from a stand-up comedy transcript. Stand-up comedy's unique comedic narratives make it an ideal dataset to improve the overall naturalness of comedic understanding. We propose a novel humor detection metric designed to evaluate LLMs amongst various prompts on their capability to extract humorous punchlines. The metric has a modular structure that offers three different scoring methods - fuzzy string matching, sentence embedding, and subspace similarity - to provide an overarching assessment of a model's performance. The model's results are compared against those of human evaluators on the same task. Our metric reveals that regardless of prompt engineering, leading models, ChatGPT, Claude, and DeepSeek, achieve scores of at most 51% in humor detection. Notably, this performance surpasses that of humans who achieve a score of 41%. The analysis of human evaluators and LLMs reveals variability in agreement, highlighting the subjectivity inherent in humor and the complexities involved in extracting humorous quotes from live performance transcripts. Code available at https://github.com/swaggirl9000/humor.
Separability Membrane: 3D Active Contour for Point Cloud Surface Reconstruction
Mar 07, 2025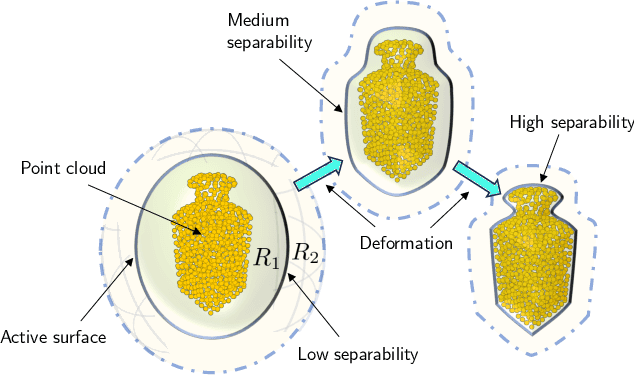
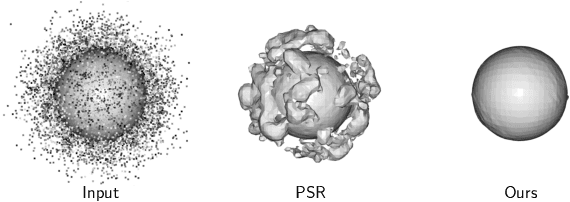
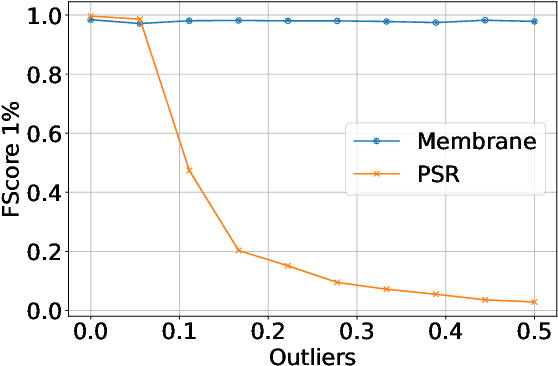
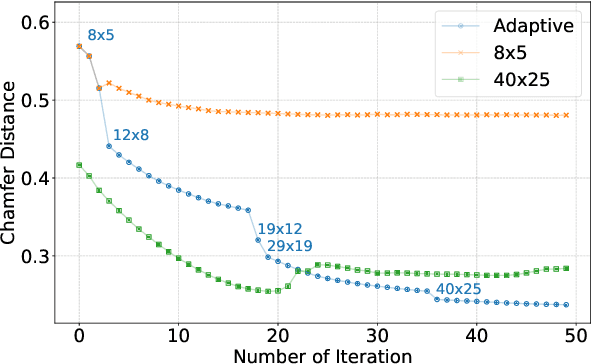
This paper proposes Separability Membrane, a robust 3D active contour for extracting a surface from 3D point cloud object. Our approach defines the surface of a 3D object as the boundary that maximizes the separability of point features, such as intensity, color, or local density, between its inner and outer regions based on Fisher's ratio. Separability Membrane identifies the exact surface of a 3D object by maximizing class separability while controlling the rigidity of the 3D surface model with an adaptive B-spline surface that adjusts its properties based on the local and global separability. A key advantage of our method is its ability to accurately reconstruct surface boundaries even when they are ambiguous due to noise or outliers, without requiring any training data or conversion to volumetric representation. Evaluations on a synthetic 3D point cloud dataset and the 3DNet dataset demonstrate the membrane's effectiveness and robustness under diverse conditions.
Frame Representation Hypothesis: Multi-Token LLM Interpretability and Concept-Guided Text Generation
Dec 10, 2024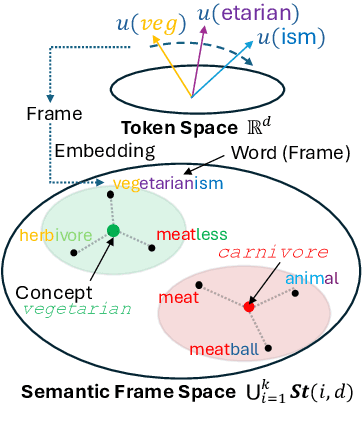

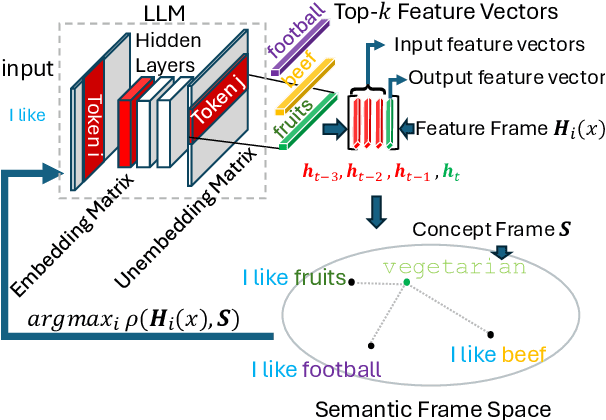
Interpretability is a key challenge in fostering trust for Large Language Models (LLMs), which stems from the complexity of extracting reasoning from model's parameters. We present the Frame Representation Hypothesis, a theoretically robust framework grounded in the Linear Representation Hypothesis (LRH) to interpret and control LLMs by modeling multi-token words. Prior research explored LRH to connect LLM representations with linguistic concepts, but was limited to single token analysis. As most words are composed of several tokens, we extend LRH to multi-token words, thereby enabling usage on any textual data with thousands of concepts. To this end, we propose words can be interpreted as frames, ordered sequences of vectors that better capture token-word relationships. Then, concepts can be represented as the average of word frames sharing a common concept. We showcase these tools through Top-k Concept-Guided Decoding, which can intuitively steer text generation using concepts of choice. We verify said ideas on Llama 3.1, Gemma 2, and Phi 3 families, demonstrating gender and language biases, exposing harmful content, but also potential to remediate them, leading to safer and more transparent LLMs. Code is available at https://github.com/phvv-me/frame-representation-hypothesis.git
Point Cloud Novelty Detection Based on Latent Representations of a General Feature Extractor
Oct 13, 2024We propose an effective unsupervised 3D point cloud novelty detection approach, leveraging a general point cloud feature extractor and a one-class classifier. The general feature extractor consists of a graph-based autoencoder and is trained once on a point cloud dataset such as a mathematically generated fractal 3D point cloud dataset that is independent of normal/abnormal categories. The input point clouds are first converted into latent vectors by the general feature extractor, and then one-class classification is performed on the latent vectors. Compared to existing methods measuring the reconstruction error in 3D coordinate space, our approach utilizes latent representations where the shape information is condensed, which allows more direct and effective novelty detection. We confirm that our general feature extractor can extract shape features of unseen categories, eliminating the need for autoencoder re-training and reducing the computational burden. We validate the performance of our method through experiments on several subsets of the ShapeNet dataset and demonstrate that our latent-based approach outperforms the existing methods.
Second-order difference subspace
Sep 13, 2024Subspace representation is a fundamental technique in various fields of machine learning. Analyzing a geometrical relationship among multiple subspaces is essential for understanding subspace series' temporal and/or spatial dynamics. This paper proposes the second-order difference subspace, a higher-order extension of the first-order difference subspace between two subspaces that can analyze the geometrical difference between them. As a preliminary for that, we extend the definition of the first-order difference subspace to the more general setting that two subspaces with different dimensions have an intersection. We then define the second-order difference subspace by combining the concept of first-order difference subspace and principal component subspace (Karcher mean) between two subspaces, motivated by the second-order central difference method. We can understand that the first/second-order difference subspaces correspond to the velocity and acceleration of subspace dynamics from the viewpoint of a geodesic on a Grassmann manifold. We demonstrate the validity and naturalness of our second-order difference subspace by showing numerical results on two applications: temporal shape analysis of a 3D object and time series analysis of a biometric signal.
Occlusion Sensitivity Analysis with Augmentation Subspace Perturbation in Deep Feature Space
Nov 25, 2023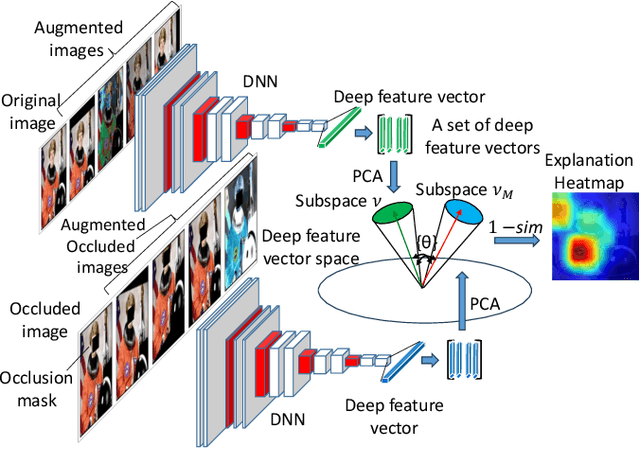

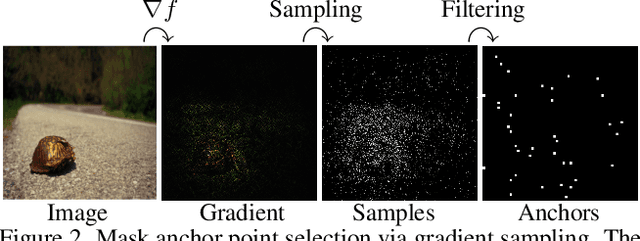
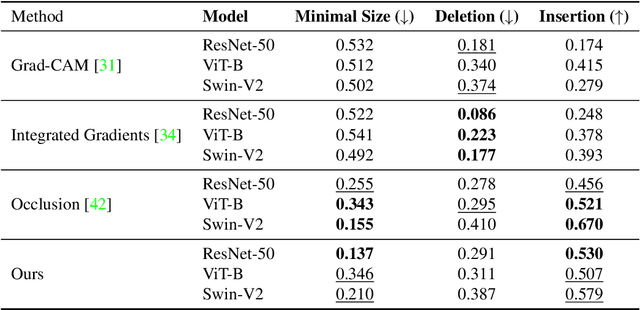
Deep Learning of neural networks has gained prominence in multiple life-critical applications like medical diagnoses and autonomous vehicle accident investigations. However, concerns about model transparency and biases persist. Explainable methods are viewed as the solution to address these challenges. In this study, we introduce the Occlusion Sensitivity Analysis with Deep Feature Augmentation Subspace (OSA-DAS), a novel perturbation-based interpretability approach for computer vision. While traditional perturbation methods make only use of occlusions to explain the model predictions, OSA-DAS extends standard occlusion sensitivity analysis by enabling the integration with diverse image augmentations. Distinctly, our method utilizes the output vector of a DNN to build low-dimensional subspaces within the deep feature vector space, offering a more precise explanation of the model prediction. The structural similarity between these subspaces encompasses the influence of diverse augmentations and occlusions. We test extensively on the ImageNet-1k, and our class- and model-agnostic approach outperforms commonly used interpreters, setting it apart in the realm of explainable AI.
Diffusion-based Holistic Texture Rectification and Synthesis
Sep 26, 2023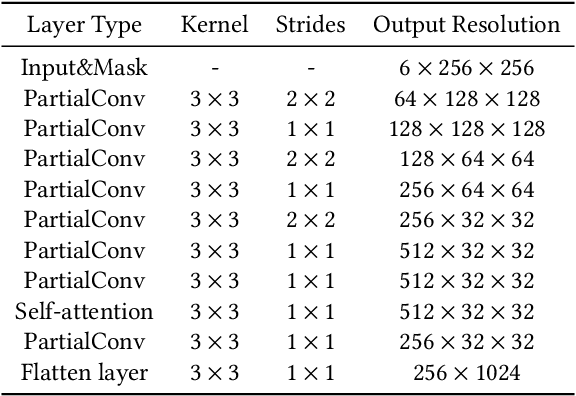
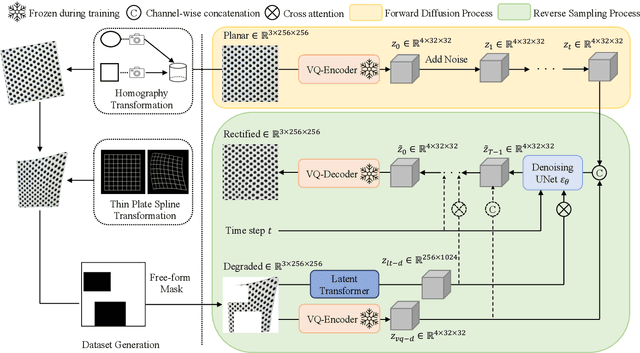

We present a novel framework for rectifying occlusions and distortions in degraded texture samples from natural images. Traditional texture synthesis approaches focus on generating textures from pristine samples, which necessitate meticulous preparation by humans and are often unattainable in most natural images. These challenges stem from the frequent occlusions and distortions of texture samples in natural images due to obstructions and variations in object surface geometry. To address these issues, we propose a framework that synthesizes holistic textures from degraded samples in natural images, extending the applicability of exemplar-based texture synthesis techniques. Our framework utilizes a conditional Latent Diffusion Model (LDM) with a novel occlusion-aware latent transformer. This latent transformer not only effectively encodes texture features from partially-observed samples necessary for the generation process of the LDM, but also explicitly captures long-range dependencies in samples with large occlusions. To train our model, we introduce a method for generating synthetic data by applying geometric transformations and free-form mask generation to clean textures. Experimental results demonstrate that our framework significantly outperforms existing methods both quantitatively and quantitatively. Furthermore, we conduct comprehensive ablation studies to validate the different components of our proposed framework. Results are corroborated by a perceptual user study which highlights the efficiency of our proposed approach.
Controllable Multi-domain Semantic Artwork Synthesis
Aug 19, 2023We present a novel framework for multi-domain synthesis of artwork from semantic layouts. One of the main limitations of this challenging task is the lack of publicly available segmentation datasets for art synthesis. To address this problem, we propose a dataset, which we call ArtSem, that contains 40,000 images of artwork from 4 different domains with their corresponding semantic label maps. We generate the dataset by first extracting semantic maps from landscape photography and then propose a conditional Generative Adversarial Network (GAN)-based approach to generate high-quality artwork from the semantic maps without necessitating paired training data. Furthermore, we propose an artwork synthesis model that uses domain-dependent variational encoders for high-quality multi-domain synthesis. The model is improved and complemented with a simple but effective normalization method, based on normalizing both the semantic and style jointly, which we call Spatially STyle-Adaptive Normalization (SSTAN). In contrast to previous methods that only take semantic layout as input, our model is able to learn a joint representation of both style and semantic information, which leads to better generation quality for synthesizing artistic images. Results indicate that our model learns to separate the domains in the latent space, and thus, by identifying the hyperplanes that separate the different domains, we can also perform fine-grained control of the synthesized artwork. By combining our proposed dataset and approach, we are able to generate user-controllable artwork that is of higher quality than existing
Time-series Anomaly Detection based on Difference Subspace between Signal Subspaces
Apr 05, 2023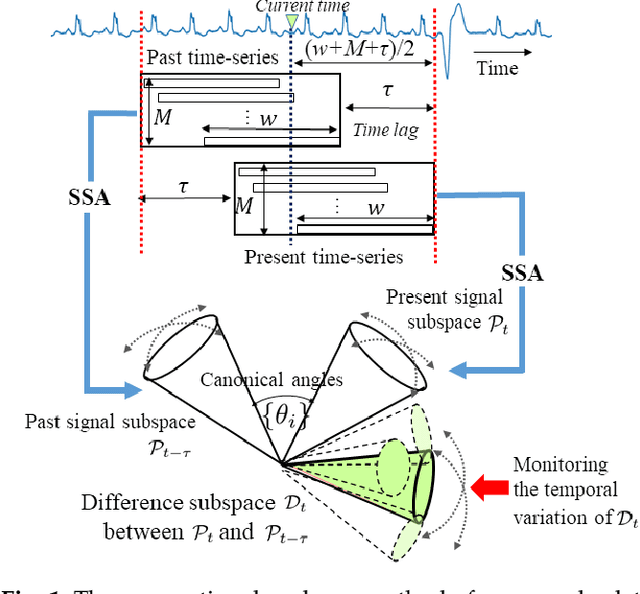
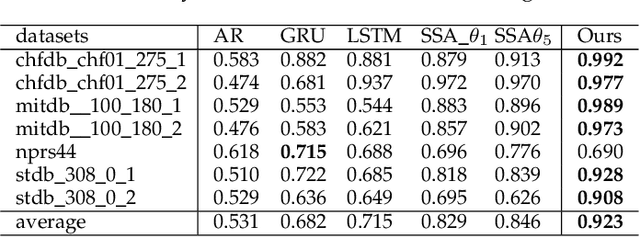
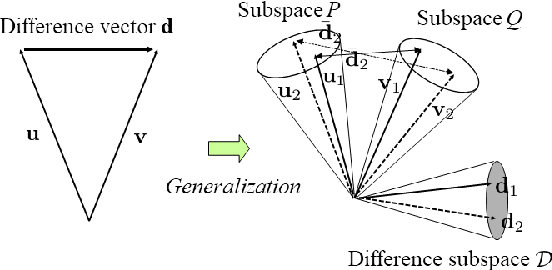
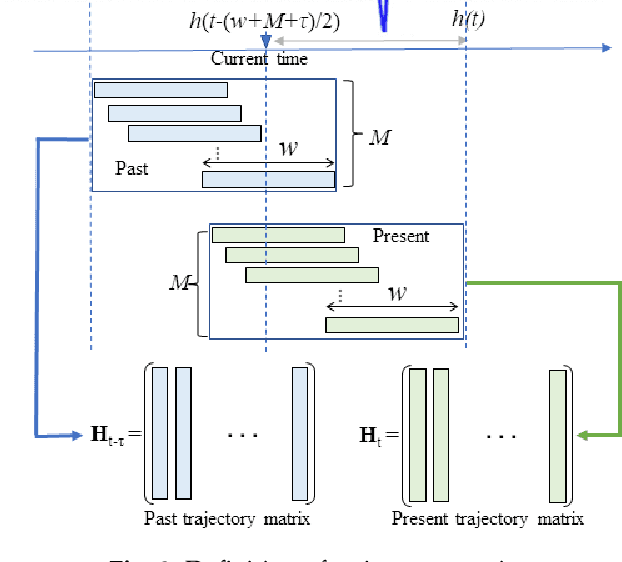
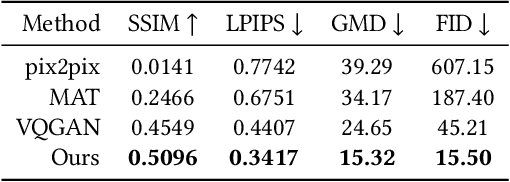
This paper proposes a new method for anomaly detection in time-series data by incorporating the concept of difference subspace into the singular spectrum analysis (SSA). The key idea is to monitor slight temporal variations of the difference subspace between two signal subspaces corresponding to the past and present time-series data, as anomaly score. It is a natural generalization of the conventional SSA-based method which measures the minimum angle between the two signal subspaces as the degree of changes. By replacing the minimum angle with the difference subspace, our method boosts the performance while using the SSA-based framework as it can capture the whole structural difference between the two subspaces in its magnitude and direction. We demonstrate our method's effectiveness through performance evaluations on public time-series datasets.