 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShavette: Low Power Neural Network Acceleration via Algorithm-level Error Detection and Undervolting
Oct 17, 2024



Reduced voltage operation is an effective technique for substantial energy efficiency improvement in digital circuits. This brief introduces a simple approach for enabling reduced voltage operation of Deep Neural Network (DNN) accelerators by mere software modifications. Conventional approaches for enabling reduced voltage operation e.g., Timing Error Detection (TED) systems, incur significant development costs and overheads, while not being applicable to the off-the-shelf components. Contrary to those, the solution proposed in this paper relies on algorithm-based error detection, and hence, is implemented with low development costs, does not require any circuit modifications, and is even applicable to commodity devices. By showcasing the solution through experimenting on popular DNNs, i.e., LeNet and VGG16, on a GPU platform, we demonstrate 18% to 25% energy saving with no accuracy loss of the models and negligible throughput compromise (< 3.9%), considering the overheads from integration of the error detection schemes into the DNN. The integration of presented algorithmic solution into the design is simpler when compared conventional TED based techniques that require extensive circuit-level modifications, cell library characterizations or special support from the design tools.
Transport Triggered Array Processor for Vision Applications
Jun 10, 2019


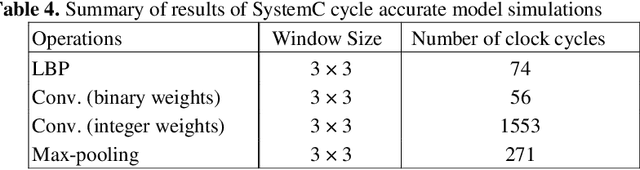
Low-level sensory data processing in many Internet-of-Things (IoT) devices pursue energy efficiency by utilizing sleep modes or slowing the clocking to the minimum. To curb the share of stand-by power dissipation in those designs, near-threshold/sub-threshold operational points or ultra-low-leakage processes in fabrication are employed. Those limit the clocking rates significantly, reducing the computing throughputs of individual processing cores. In this contribution we explore compensating for the performance loss of operating in near-threshold region (Vdd =0.6V) through massive parallelization. Benefits of near-threshold operation and massive parallelism are optimum energy consumption per instruction operation and minimized memory roundtrips, respectively. The Processing Elements (PE) of the design are based on Transport Triggered Architecture. The fine grained programmable parallel solution allows for fast and efficient computation of learnable low-level features (e.g. local binary descriptors and convolutions). Other operations, including Max-pooling have also been implemented. The programmable design achieves excellent energy efficiency for Local Binary Patterns computations.