 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning for API Aspect Analysis
Aug 14, 2023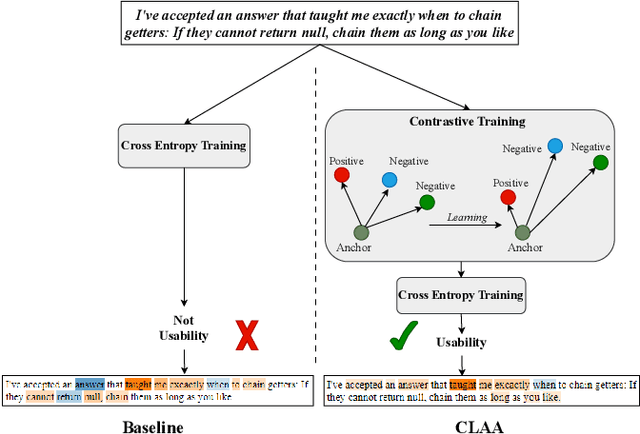



We present a novel approach - CLAA - for API aspect detection in API reviews that utilizes transformer models trained with a supervised contrastive loss objective function. We evaluate CLAA using performance and impact analysis. For performance analysis, we utilized a benchmark dataset on developer discussions collected from Stack Overflow and compare the results to those obtained using state-of-the-art transformer models. Our experiments show that contrastive learning can significantly improve the performance of transformer models in detecting aspects such as Performance, Security, Usability, and Documentation. For impact analysis, we performed empirical and developer study. On a randomly selected and manually labeled 200 online reviews, CLAA achieved 92% accuracy while the SOTA baseline achieved 81.5%. According to our developer study involving 10 participants, the use of 'Stack Overflow + CLAA' resulted in increased accuracy and confidence during API selection. Replication package: https://github.com/disa-lab/Contrastive-Learning-API-Aspect-ASE2023
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022



Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
BanglaNLG: Benchmarks and Resources for Evaluating Low-Resource Natural Language Generation in Bangla
May 24, 2022

This work presents BanglaNLG, a comprehensive benchmark for evaluating natural language generation (NLG) models in Bangla, a widely spoken yet low-resource language in the web domain. We aggregate three challenging conditional text generation tasks under the BanglaNLG benchmark. Then, using a clean corpus of 27.5 GB of Bangla data, we pretrain BanglaT5, a sequence-to-sequence Transformer model for Bangla. BanglaT5 achieves state-of-the-art performance in all of these tasks, outperforming mT5 (base) by up to 5.4%. We are making the BanglaT5 language model and a leaderboard publicly available in the hope of advancing future research and evaluation on Bangla NLG. The resources can be found at https://github.com/csebuetnlp/BanglaNLG.
CrossSum: Beyond English-Centric Cross-Lingual Abstractive Text Summarization for 1500+ Language Pairs
Dec 16, 2021We present CrossSum, a large-scale dataset comprising 1.65 million cross-lingual article-summary samples in 1500+ language-pairs constituting 45 languages. We use the multilingual XL-Sum dataset and align identical articles written in different languages via cross-lingual retrieval using a language-agnostic representation model. We propose a multi-stage data sampling algorithm and fine-tune mT5, a multilingual pretrained model, with explicit cross-lingual supervision with CrossSum and introduce a new metric for evaluating cross-lingual summarization. Results on established and our proposed metrics indicate that models fine-tuned on CrossSum outperforms summarization+translation baselines, even when the source and target language pairs are linguistically distant. To the best of our knowledge, CrossSum is the largest cross-lingual summarization dataset and also the first-ever that does not rely on English as the pivot language. We are releasing the dataset, alignment and training scripts, and the models to spur future research on cross-lingual abstractive summarization. The resources can be found at \url{https://github.com/csebuetnlp/CrossSum}.
XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages
Jun 25, 2021
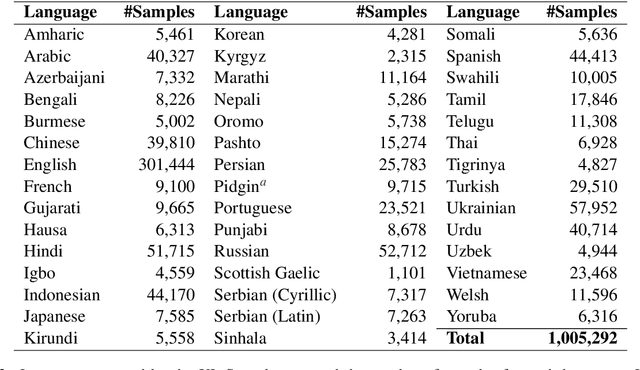
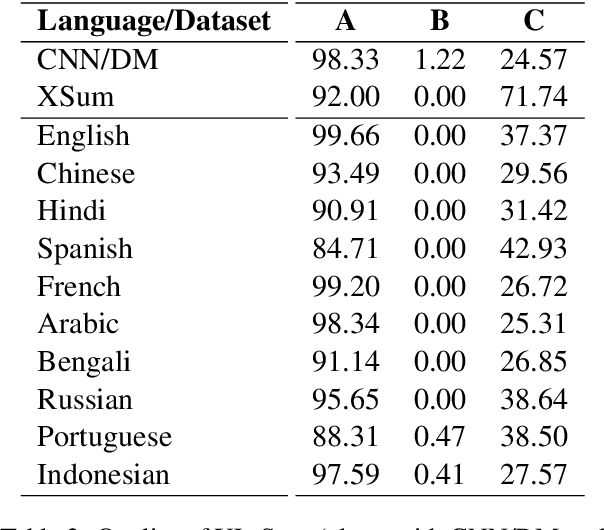
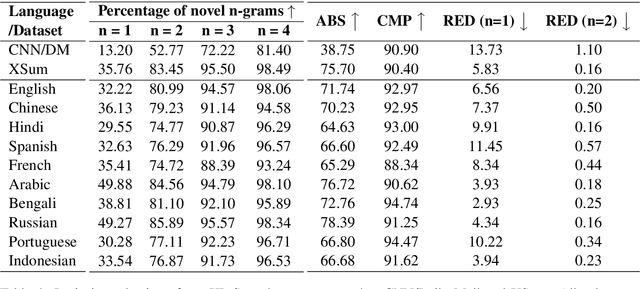
Contemporary works on abstractive text summarization have focused primarily on high-resource languages like English, mostly due to the limited availability of datasets for low/mid-resource ones. In this work, we present XL-Sum, a comprehensive and diverse dataset comprising 1 million professionally annotated article-summary pairs from BBC, extracted using a set of carefully designed heuristics. The dataset covers 44 languages ranging from low to high-resource, for many of which no public dataset is currently available. XL-Sum is highly abstractive, concise, and of high quality, as indicated by human and intrinsic evaluation. We fine-tune mT5, a state-of-the-art pretrained multilingual model, with XL-Sum and experiment on multilingual and low-resource summarization tasks. XL-Sum induces competitive results compared to the ones obtained using similar monolingual datasets: we show higher than 11 ROUGE-2 scores on 10 languages we benchmark on, with some of them exceeding 15, as obtained by multilingual training. Additionally, training on low-resource languages individually also provides competitive performance. To the best of our knowledge, XL-Sum is the largest abstractive summarization dataset in terms of the number of samples collected from a single source and the number of languages covered. We are releasing our dataset and models to encourage future research on multilingual abstractive summarization. The resources can be found at \url{https://github.com/csebuetnlp/xl-sum}.
CoDesc: A Large Code-Description Parallel Dataset
May 29, 2021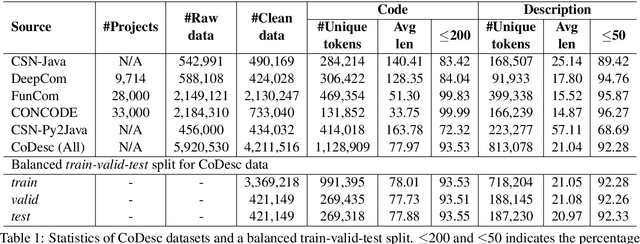
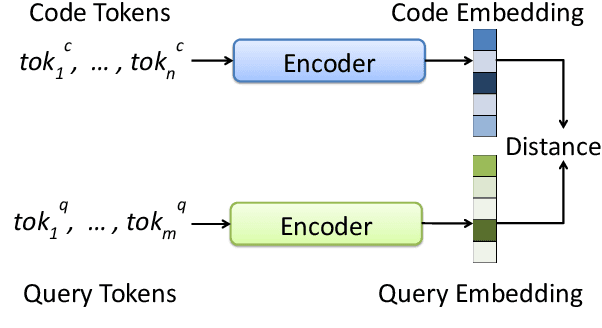
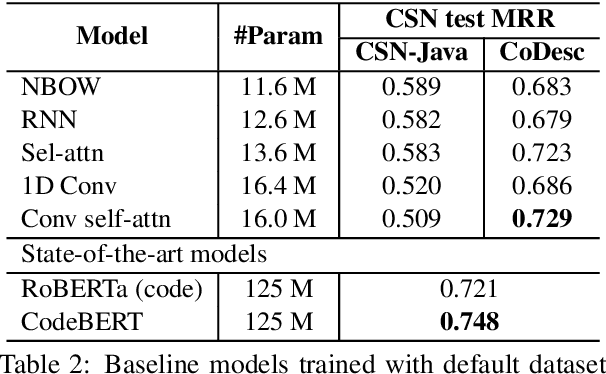

Translation between natural language and source code can help software development by enabling developers to comprehend, ideate, search, and write computer programs in natural language. Despite growing interest from the industry and the research community, this task is often difficult due to the lack of large standard datasets suitable for training deep neural models, standard noise removal methods, and evaluation benchmarks. This leaves researchers to collect new small-scale datasets, resulting in inconsistencies across published works. In this study, we present CoDesc -- a large parallel dataset composed of 4.2 million Java methods and natural language descriptions. With extensive analysis, we identify and remove prevailing noise patterns from the dataset. We demonstrate the proficiency of CoDesc in two complementary tasks for code-description pairs: code summarization and code search. We show that the dataset helps improve code search by up to 22\% and achieves the new state-of-the-art in code summarization. Furthermore, we show CoDesc's effectiveness in pre-training--fine-tuning setup, opening possibilities in building pretrained language models for Java. To facilitate future research, we release the dataset, a data processing tool, and a benchmark at \url{https://github.com/csebuetnlp/CoDesc}.
BERT2Code: Can Pretrained Language Models be Leveraged for Code Search?
Apr 16, 2021
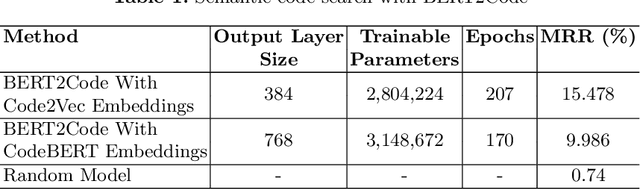
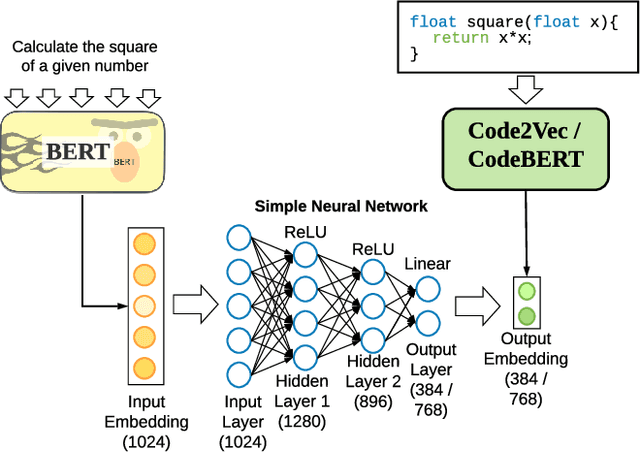

Millions of repetitive code snippets are submitted to code repositories every day. To search from these large codebases using simple natural language queries would allow programmers to ideate, prototype, and develop easier and faster. Although the existing methods have shown good performance in searching codes when the natural language description contains keywords from the code, they are still far behind in searching codes based on the semantic meaning of the natural language query and semantic structure of the code. In recent years, both natural language and programming language research communities have created techniques to embed them in vector spaces. In this work, we leverage the efficacy of these embedding models using a simple, lightweight 2-layer neural network in the task of semantic code search. We show that our model learns the inherent relationship between the embedding spaces and further probes into the scope of improvement by empirically analyzing the embedding methods. In this analysis, we show that the quality of the code embedding model is the bottleneck for our model's performance, and discuss future directions of study in this area.
BanglaBERT: Combating Embedding Barrier for Low-Resource Language Understanding
Jan 01, 2021Pre-training language models on large volume of data with self-supervised objectives has become a standard practice in natural language processing. However, most such state-of-the-art models are available in only English and other resource-rich languages. Even in multilingual models, which are trained on hundreds of languages, low-resource ones still remain underrepresented. Bangla, the seventh most widely spoken language in the world, is still low in terms of resources. Few downstream task datasets for language understanding in Bangla are publicly available, and there is a clear shortage of good quality data for pre-training. In this work, we build a Bangla natural language understanding model pre-trained on 18.6 GB data we crawled from top Bangla sites on the internet. We introduce a new downstream task dataset and benchmark on four tasks on sentence classification, document classification, natural language understanding, and sequence tagging. Our model outperforms multilingual baselines and previous state-of-the-art results by 1-6%. In the process, we identify a major shortcoming of multilingual models that hurt performance for low-resource languages that don't share writing scripts with any high resource one, which we name the `Embedding Barrier'. We perform extensive experiments to study this barrier. We release all our datasets and pre-trained models to aid future NLP research on Bangla and other low-resource languages. Our code and data are available at https://github.com/csebuetnlp/banglabert.
Not Low-Resource Anymore: Aligner Ensembling, Batch Filtering, and New Datasets for Bengali-English Machine Translation
Oct 07, 2020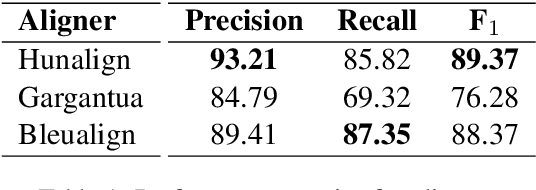
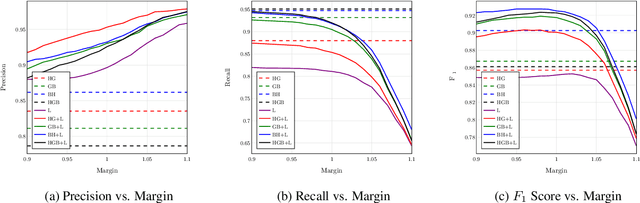
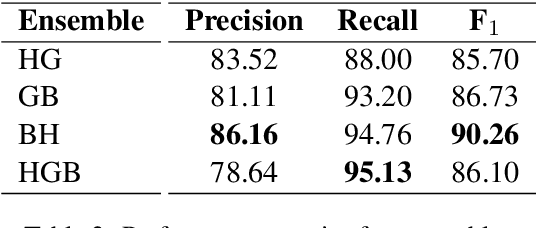
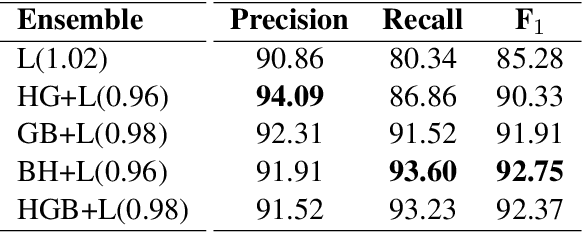
Despite being the seventh most widely spoken language in the world, Bengali has received much less attention in machine translation literature due to being low in resources. Most publicly available parallel corpora for Bengali are not large enough; and have rather poor quality, mostly because of incorrect sentence alignments resulting from erroneous sentence segmentation, and also because of a high volume of noise present in them. In this work, we build a customized sentence segmenter for Bengali and propose two novel methods for parallel corpus creation on low-resource setups: aligner ensembling and batch filtering. With the segmenter and the two methods combined, we compile a high-quality Bengali-English parallel corpus comprising of 2.75 million sentence pairs, more than 2 million of which were not available before. Training on neural models, we achieve an improvement of more than 9 BLEU score over previous approaches to Bengali-English machine translation. We also evaluate on a new test set of 1000 pairs made with extensive quality control. We release the segmenter, parallel corpus, and the evaluation set, thus elevating Bengali from its low-resource status. To the best of our knowledge, this is the first ever large scale study on Bengali-English machine translation. We believe our study will pave the way for future research on Bengali-English machine translation as well as other low-resource languages. Our data and code are available at https://github.com/csebuetnlp/banglanmt.