 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicEval: A Systematic Framework for Evaluating Automated Repair Techniques for Logical Vulnerabilities in Real-World Software
Apr 14, 2026Logical vulnerabilities in software stem from flaws in program logic rather than memory safety, which can lead to critical security failures. Although existing automated program repair techniques primarily focus on repairing memory corruption vulnerabilities, they struggle with logical vulnerabilities because of their limited semantic understanding of the vulnerable code and its expected behavior. On the other hand, recent successes of large language models (LLMs) in understanding and repairing code are promising. However, no framework currently exists to analyze the capabilities and limitations of such techniques for logical vulnerabilities. This paper aims to systematically evaluate both traditional and LLM-based repair approaches for addressing real-world logical vulnerabilities. To facilitate our assessment, we created the first ever dataset, LogicDS, of 86 logical vulnerabilities with assigned CVEs reflecting tangible security impact. We also developed a systematic framework, LogicEval, to evaluate patches for logical vulnerabilities. Evaluations suggest that compilation and testing failures are primarily driven by prompt sensitivity, loss of code context, and difficulty in patch localization.
Hermes: Unlocking Security Analysis of Cellular Network Protocols by Synthesizing Finite State Machines from Natural Language Specifications
Oct 11, 2023
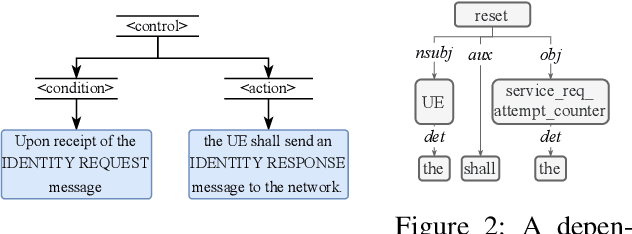


In this paper, we present Hermes, an end-to-end framework to automatically generate formal representations from natural language cellular specifications. We first develop a neural constituency parser, NEUTREX, to process transition-relevant texts and extract transition components (i.e., states, conditions, and actions). We also design a domain-specific language to translate these transition components to logical formulas by leveraging dependency parse trees. Finally, we compile these logical formulas to generate transitions and create the formal model as finite state machines. To demonstrate the effectiveness of Hermes, we evaluate it on 4G NAS, 5G NAS, and 5G RRC specifications and obtain an overall accuracy of 81-87%, which is a substantial improvement over the state-of-the-art. Our security analysis of the extracted models uncovers 3 new vulnerabilities and identifies 19 previous attacks in 4G and 5G specifications, and 7 deviations in commercial 4G basebands.
CoDesc: A Large Code-Description Parallel Dataset
May 29, 2021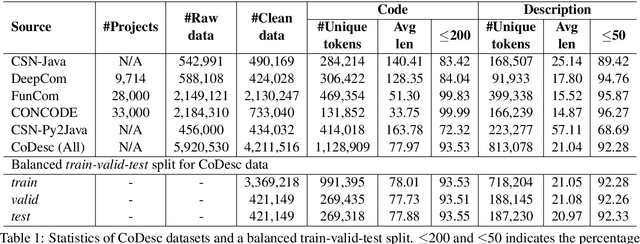

Translation between natural language and source code can help software development by enabling developers to comprehend, ideate, search, and write computer programs in natural language. Despite growing interest from the industry and the research community, this task is often difficult due to the lack of large standard datasets suitable for training deep neural models, standard noise removal methods, and evaluation benchmarks. This leaves researchers to collect new small-scale datasets, resulting in inconsistencies across published works. In this study, we present CoDesc -- a large parallel dataset composed of 4.2 million Java methods and natural language descriptions. With extensive analysis, we identify and remove prevailing noise patterns from the dataset. We demonstrate the proficiency of CoDesc in two complementary tasks for code-description pairs: code summarization and code search. We show that the dataset helps improve code search by up to 22\% and achieves the new state-of-the-art in code summarization. Furthermore, we show CoDesc's effectiveness in pre-training--fine-tuning setup, opening possibilities in building pretrained language models for Java. To facilitate future research, we release the dataset, a data processing tool, and a benchmark at \url{https://github.com/csebuetnlp/CoDesc}.
BERT2Code: Can Pretrained Language Models be Leveraged for Code Search?
Apr 16, 2021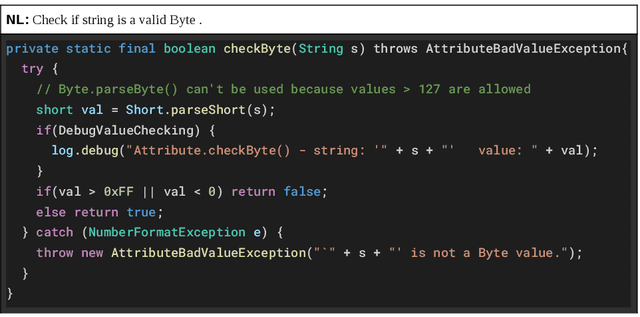
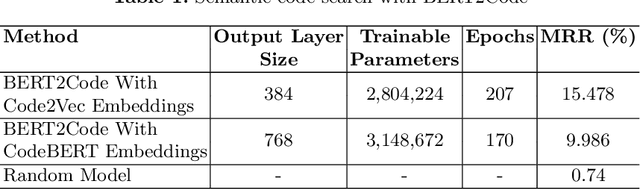
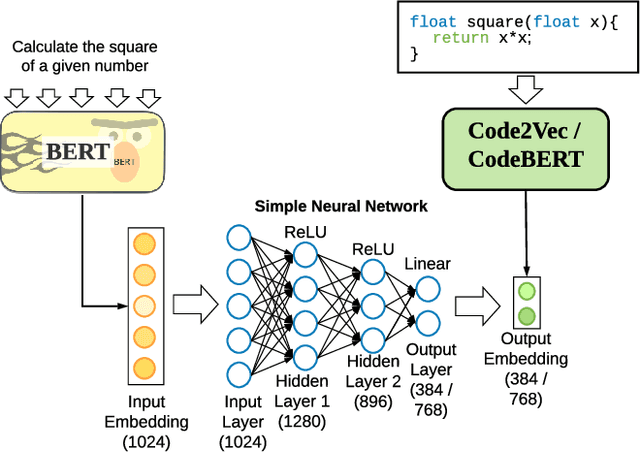

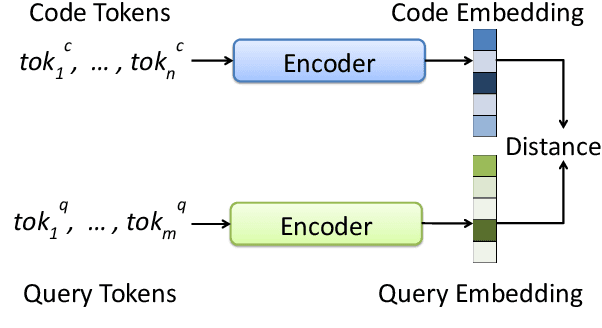
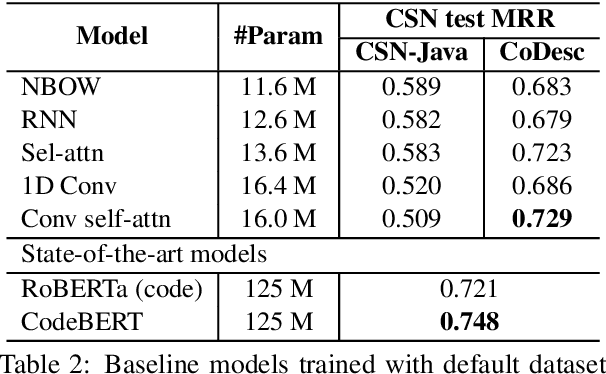
Millions of repetitive code snippets are submitted to code repositories every day. To search from these large codebases using simple natural language queries would allow programmers to ideate, prototype, and develop easier and faster. Although the existing methods have shown good performance in searching codes when the natural language description contains keywords from the code, they are still far behind in searching codes based on the semantic meaning of the natural language query and semantic structure of the code. In recent years, both natural language and programming language research communities have created techniques to embed them in vector spaces. In this work, we leverage the efficacy of these embedding models using a simple, lightweight 2-layer neural network in the task of semantic code search. We show that our model learns the inherent relationship between the embedding spaces and further probes into the scope of improvement by empirically analyzing the embedding methods. In this analysis, we show that the quality of the code embedding model is the bottleneck for our model's performance, and discuss future directions of study in this area.