 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocially Constructed Treatment Plans: Analyzing Online Peer Interactions to Understand How Patients Navigate Complex Medical Conditions
Mar 27, 2025When faced with complex and uncertain medical conditions (e.g., cancer, mental health conditions, recovery from substance dependency), millions of patients seek online peer support. In this study, we leverage content analysis of online discourse and ethnographic studies with clinicians and patient representatives to characterize how treatment plans for complex conditions are "socially constructed." Specifically, we ground online conversation on medication-assisted recovery treatment to medication guidelines and subsequently surface when and why people deviate from the clinical guidelines. We characterize the implications and effectiveness of socially constructed treatment plans through in-depth interviews with clinical experts. Finally, given the enthusiasm around AI-powered solutions for patient communication, we investigate whether and how socially constructed treatment-related knowledge is reflected in a state-of-the-art large language model (LLM). Leveraging a novel mixed-method approach, this study highlights critical research directions for patient-centered communication in online health communities.
REGen: A Reliable Evaluation Framework for Generative Event Argument Extraction
Feb 24, 2025Event argument extraction identifies arguments for predefined event roles in text. Traditional evaluations rely on exact match (EM), requiring predicted arguments to match annotated spans exactly. However, this approach fails for generative models like large language models (LLMs), which produce diverse yet semantically accurate responses. EM underestimates performance by disregarding valid variations, implicit arguments (unstated but inferable), and scattered arguments (distributed across a document). To bridge this gap, we introduce Reliable Evaluation framework for Generative event argument extraction (REGen), a framework that better aligns with human judgment. Across six datasets, REGen improves performance by an average of 23.93 F1 points over EM. Human validation further confirms REGen's effectiveness, achieving 87.67% alignment with human assessments of argument correctness.
Explicit, Implicit, and Scattered: Revisiting Event Extraction to Capture Complex Arguments
Oct 04, 2024



Prior works formulate the extraction of event-specific arguments as a span extraction problem, where event arguments are explicit -- i.e. assumed to be contiguous spans of text in a document. In this study, we revisit this definition of Event Extraction (EE) by introducing two key argument types that cannot be modeled by existing EE frameworks. First, implicit arguments are event arguments which are not explicitly mentioned in the text, but can be inferred through context. Second, scattered arguments are event arguments that are composed of information scattered throughout the text. These two argument types are crucial to elicit the full breadth of information required for proper event modeling. To support the extraction of explicit, implicit, and scattered arguments, we develop a novel dataset, DiscourseEE, which includes 7,464 argument annotations from online health discourse. Notably, 51.2% of the arguments are implicit, and 17.4% are scattered, making DiscourseEE a unique corpus for complex event extraction. Additionally, we formulate argument extraction as a text generation problem to facilitate the extraction of complex argument types. We provide a comprehensive evaluation of state-of-the-art models and highlight critical open challenges in generative event extraction. Our data and codebase are available at https://omar-sharif03.github.io/DiscourseEE.
A Thematic Framework for Analyzing Large-scale Self-reported Social Media Data on Opioid Use Disorder Treatment Using Buprenorphine Product
Oct 02, 2024Background: One of the key FDA-approved medications for Opioid Use Disorder (OUD) is buprenorphine. Despite its popularity, individuals often report various information needs regarding buprenorphine treatment on social media platforms like Reddit. However, the key challenge is to characterize these needs. In this study, we propose a theme-based framework to curate and analyze large-scale data from social media to characterize self-reported treatment information needs (TINs). Methods: We collected 15,253 posts from r/Suboxone, one of the largest Reddit sub-community for buprenorphine products. Following the standard protocol, we first identified and defined five main themes from the data and then coded 6,000 posts based on these themes, where one post can be labeled with applicable one to three themes. Finally, we determined the most frequently appearing sub-themes (topics) for each theme by analyzing samples from each group. Results: Among the 6,000 posts, 40.3% contained a single theme, 36% two themes, and 13.9% three themes. The most frequent topics for each theme or theme combination came with several key findings - prevalent reporting of psychological and physical effects during recovery, complexities in accessing buprenorphine, and significant information gaps regarding medication administration, tapering, and usage of substances during different stages of recovery. Moreover, self-treatment strategies and peer-driven advice reveal valuable insights and potential misconceptions. Conclusions: The findings obtained using our proposed framework can inform better patient education and patient-provider communication, design systematic interventions to address treatment-related misconceptions and rumors, and streamline the generation of hypotheses for future research.
Do LLMs Find Human Answers To Fact-Driven Questions Perplexing? A Case Study on Reddit
Apr 01, 2024Large language models (LLMs) have been shown to be proficient in correctly answering questions in the context of online discourse. However, the study of using LLMs to model human-like answers to fact-driven social media questions is still under-explored. In this work, we investigate how LLMs model the wide variety of human answers to fact-driven questions posed on several topic-specific Reddit communities, or subreddits. We collect and release a dataset of 409 fact-driven questions and 7,534 diverse, human-rated answers from 15 r/Ask{Topic} communities across 3 categories: profession, social identity, and geographic location. We find that LLMs are considerably better at modeling highly-rated human answers to such questions, as opposed to poorly-rated human answers. We present several directions for future research based on our initial findings.
Scope of Large Language Models for Mining Emerging Opinions in Online Health Discourse
Mar 05, 2024In this paper, we develop an LLM-powered framework for the curation and evaluation of emerging opinion mining in online health communities. We formulate emerging opinion mining as a pairwise stance detection problem between (title, comment) pairs sourced from Reddit, where post titles contain emerging health-related claims on a topic that is not predefined. The claims are either explicitly or implicitly expressed by the user. We detail (i) a method of claim identification -- the task of identifying if a post title contains a claim and (ii) an opinion mining-driven evaluation framework for stance detection using LLMs. We facilitate our exploration by releasing a novel test dataset, Long COVID-Stance, or LC-stance, which can be used to evaluate LLMs on the tasks of claim identification and stance detection in online health communities. Long Covid is an emerging post-COVID disorder with uncertain and complex treatment guidelines, thus making it a suitable use case for our task. LC-Stance contains long COVID treatment related discourse sourced from a Reddit community. Our evaluation shows that GPT-4 significantly outperforms prior works on zero-shot stance detection. We then perform thorough LLM model diagnostics, identifying the role of claim type (i.e. implicit vs explicit claims) and comment length as sources of model error.
Characterizing Information Seeking Events in Health-Related Social Discourse
Aug 17, 2023Social media sites have become a popular platform for individuals to seek and share health information. Despite the progress in natural language processing for social media mining, a gap remains in analyzing health-related texts on social discourse in the context of events. Event-driven analysis can offer insights into different facets of healthcare at an individual and collective level, including treatment options, misconceptions, knowledge gaps, etc. This paper presents a paradigm to characterize health-related information-seeking in social discourse through the lens of events. Events here are board categories defined with domain experts that capture the trajectory of the treatment/medication. To illustrate the value of this approach, we analyze Reddit posts regarding medications for Opioid Use Disorder (OUD), a critical global health concern. To the best of our knowledge, this is the first attempt to define event categories for characterizing information-seeking in OUD social discourse. Guided by domain experts, we develop TREAT-ISE, a novel multilabel treatment information-seeking event dataset to analyze online discourse on an event-based framework. This dataset contains Reddit posts on information-seeking events related to recovery from OUD, where each post is annotated based on the type of events. We also establish a strong performance benchmark (77.4% F1 score) for the task by employing several machine learning and deep learning classifiers. Finally, we thoroughly investigate the performance and errors of ChatGPT on this task, providing valuable insights into the LLM's capabilities and ongoing characterization efforts.
The Scope of In-Context Learning for the Extraction of Medical Temporal Constraints
Mar 16, 2023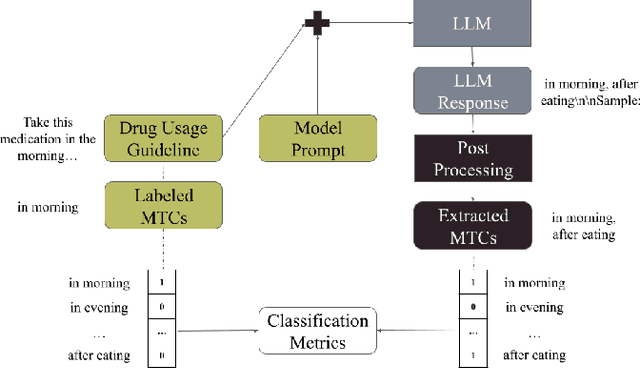
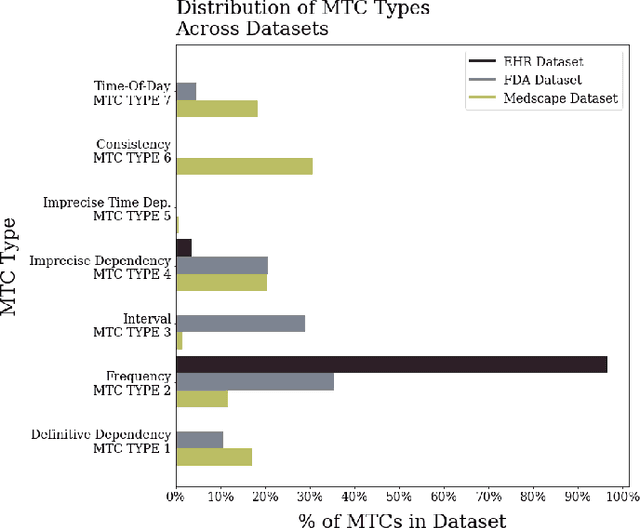

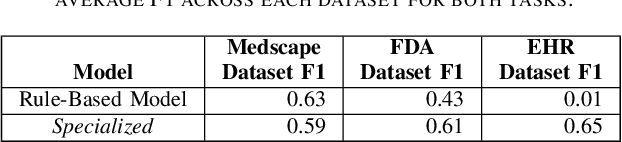
Medications often impose temporal constraints on everyday patient activity. Violations of such medical temporal constraints (MTCs) lead to a lack of treatment adherence, in addition to poor health outcomes and increased healthcare expenses. These MTCs are found in drug usage guidelines (DUGs) in both patient education materials and clinical texts. Computationally representing MTCs in DUGs will advance patient-centric healthcare applications by helping to define safe patient activity patterns. We define a novel taxonomy of MTCs found in DUGs and develop a novel context-free grammar (CFG) based model to computationally represent MTCs from unstructured DUGs. Additionally, we release three new datasets with a combined total of N = 836 DUGs labeled with normalized MTCs. We develop an in-context learning (ICL) solution for automatically extracting and normalizing MTCs found in DUGs, achieving an average F1 score of 0.62 across all datasets. Finally, we rigorously investigate ICL model performance against a baseline model, across datasets and MTC types, and through in-depth error analysis.
Theme-driven Keyphrase Extraction from Social Media on Opioid Recovery
Jan 27, 2023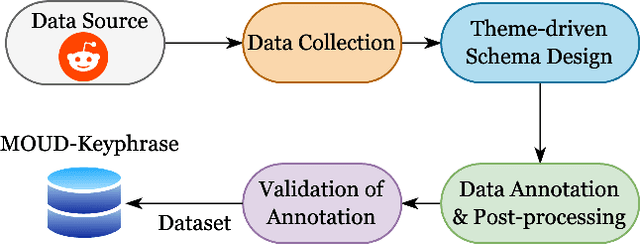
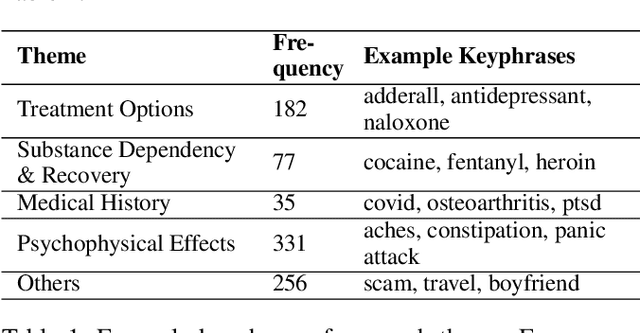

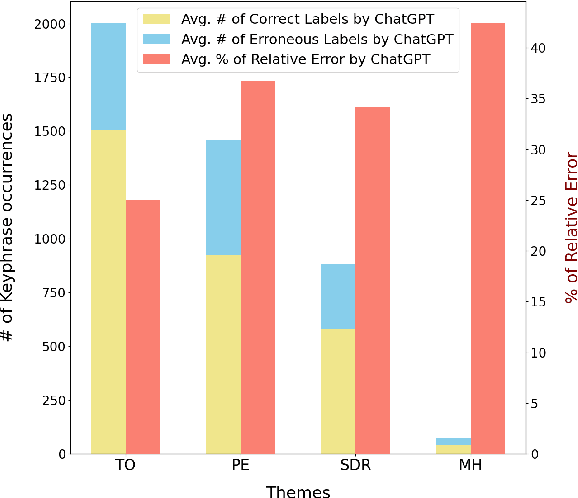
An emerging trend on social media platforms is their use as safe spaces for peer support. Particularly in healthcare, where many medical conditions contain harsh stigmas, social media has become a stigma-free way to engage in dialogues regarding symptoms, treatments, and personal experiences. Many existing works have employed NLP algorithms to facilitate quantitative analysis of health trends. Notably absent from existing works are keyphrase extraction (KE) models for social health posts-a task crucial to discovering emerging public health trends. This paper presents a novel, theme-driven KE dataset, SuboxoPhrase, and a qualitative annotation scheme with an overarching goal of extracting targeted clinically-relevant keyphrases. To the best of our knowledge, this is the first study to design a KE schema for social media healthcare texts. To demonstrate the value of this approach, this study analyzes Reddit posts regarding medications for opioid use disorder, a paramount health concern worldwide. Additionally, we benchmark ten off-the-shelf KE models on our new dataset, demonstrating the unique extraction challenges in modeling user-generated health texts. The proposed theme-driven KE approach lays the foundation of future work on efficient, large-scale analysis of social health texts, allowing researchers to surface useful public health trends, patterns, and knowledge gaps.
Scope of Pre-trained Language Models for Detecting Conflicting Health Information
Sep 22, 2022

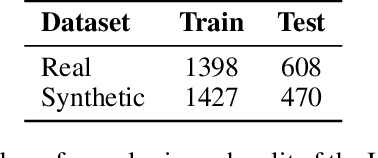

An increasing number of people now rely on online platforms to meet their health information needs. Thus identifying inconsistent or conflicting textual health information has become a safety-critical task. Health advice data poses a unique challenge where information that is accurate in the context of one diagnosis can be conflicting in the context of another. For example, people suffering from diabetes and hypertension often receive conflicting health advice on diet. This motivates the need for technologies which can provide contextualized, user-specific health advice. A crucial step towards contextualized advice is the ability to compare health advice statements and detect if and how they are conflicting. This is the task of health conflict detection (HCD). Given two pieces of health advice, the goal of HCD is to detect and categorize the type of conflict. It is a challenging task, as (i) automatically identifying and categorizing conflicts requires a deeper understanding of the semantics of the text, and (ii) the amount of available data is quite limited. In this study, we are the first to explore HCD in the context of pre-trained language models. We find that DeBERTa-v3 performs best with a mean F1 score of 0.68 across all experiments. We additionally investigate the challenges posed by different conflict types and how synthetic data improves a model's understanding of conflict-specific semantics. Finally, we highlight the difficulty in collecting real health conflicts and propose a human-in-the-loop synthetic data augmentation approach to expand existing HCD datasets. Our HCD training dataset is over 2x bigger than the existing HCD dataset and is made publicly available on Github.