 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Triage as Pairwise Ranking: A Benchmark for Urgency in Patient Portal Messages
Jan 19, 2026Medical triage is the task of allocating medical resources and prioritizing patients based on medical need. This paper introduces the first large-scale public dataset for studying medical triage in the context of asynchronous outpatient portal messages. Our novel task formulation views patient message triage as a pairwise inference problem, where we train LLMs to choose `"which message is more medically urgent" in a head-to-head tournament-style re-sort of a physician's inbox. Our novel benchmark PMR-Bench contains 1569 unique messages and 2,000+ high-quality test pairs for pairwise medical urgency assessment alongside a scalable training data generation pipeline. PMR-Bench includes samples that contain both unstructured patient-written messages alongside real electronic health record (EHR) data, emulating a real-world medical triage scenario. We develop a novel automated data annotation strategy to provide LLMs with in-domain guidance on this task. The resulting data is used to train two model classes, UrgentReward and UrgentSFT, leveraging Bradley-Terry and next token prediction objective, respectively to perform pairwise urgency classification. We find that UrgentSFT achieves top performance on PMR-Bench, with UrgentReward showing distinct advantages in low-resource settings. For example, UrgentSFT-8B and UrgentReward-8B provide a 15- and 16-point boost, respectively, on inbox sorting metrics over off-the-shelf 8B models. Paper resources can be found at https://tinyurl.com/Patient-Message-Triage
Socially Constructed Treatment Plans: Analyzing Online Peer Interactions to Understand How Patients Navigate Complex Medical Conditions
Mar 27, 2025When faced with complex and uncertain medical conditions (e.g., cancer, mental health conditions, recovery from substance dependency), millions of patients seek online peer support. In this study, we leverage content analysis of online discourse and ethnographic studies with clinicians and patient representatives to characterize how treatment plans for complex conditions are "socially constructed." Specifically, we ground online conversation on medication-assisted recovery treatment to medication guidelines and subsequently surface when and why people deviate from the clinical guidelines. We characterize the implications and effectiveness of socially constructed treatment plans through in-depth interviews with clinical experts. Finally, given the enthusiasm around AI-powered solutions for patient communication, we investigate whether and how socially constructed treatment-related knowledge is reflected in a state-of-the-art large language model (LLM). Leveraging a novel mixed-method approach, this study highlights critical research directions for patient-centered communication in online health communities.
REGen: A Reliable Evaluation Framework for Generative Event Argument Extraction
Feb 24, 2025Event argument extraction identifies arguments for predefined event roles in text. Traditional evaluations rely on exact match (EM), requiring predicted arguments to match annotated spans exactly. However, this approach fails for generative models like large language models (LLMs), which produce diverse yet semantically accurate responses. EM underestimates performance by disregarding valid variations, implicit arguments (unstated but inferable), and scattered arguments (distributed across a document). To bridge this gap, we introduce Reliable Evaluation framework for Generative event argument extraction (REGen), a framework that better aligns with human judgment. Across six datasets, REGen improves performance by an average of 23.93 F1 points over EM. Human validation further confirms REGen's effectiveness, achieving 87.67% alignment with human assessments of argument correctness.
Explicit, Implicit, and Scattered: Revisiting Event Extraction to Capture Complex Arguments
Oct 04, 2024



Prior works formulate the extraction of event-specific arguments as a span extraction problem, where event arguments are explicit -- i.e. assumed to be contiguous spans of text in a document. In this study, we revisit this definition of Event Extraction (EE) by introducing two key argument types that cannot be modeled by existing EE frameworks. First, implicit arguments are event arguments which are not explicitly mentioned in the text, but can be inferred through context. Second, scattered arguments are event arguments that are composed of information scattered throughout the text. These two argument types are crucial to elicit the full breadth of information required for proper event modeling. To support the extraction of explicit, implicit, and scattered arguments, we develop a novel dataset, DiscourseEE, which includes 7,464 argument annotations from online health discourse. Notably, 51.2% of the arguments are implicit, and 17.4% are scattered, making DiscourseEE a unique corpus for complex event extraction. Additionally, we formulate argument extraction as a text generation problem to facilitate the extraction of complex argument types. We provide a comprehensive evaluation of state-of-the-art models and highlight critical open challenges in generative event extraction. Our data and codebase are available at https://omar-sharif03.github.io/DiscourseEE.
A Thematic Framework for Analyzing Large-scale Self-reported Social Media Data on Opioid Use Disorder Treatment Using Buprenorphine Product
Oct 02, 2024Background: One of the key FDA-approved medications for Opioid Use Disorder (OUD) is buprenorphine. Despite its popularity, individuals often report various information needs regarding buprenorphine treatment on social media platforms like Reddit. However, the key challenge is to characterize these needs. In this study, we propose a theme-based framework to curate and analyze large-scale data from social media to characterize self-reported treatment information needs (TINs). Methods: We collected 15,253 posts from r/Suboxone, one of the largest Reddit sub-community for buprenorphine products. Following the standard protocol, we first identified and defined five main themes from the data and then coded 6,000 posts based on these themes, where one post can be labeled with applicable one to three themes. Finally, we determined the most frequently appearing sub-themes (topics) for each theme by analyzing samples from each group. Results: Among the 6,000 posts, 40.3% contained a single theme, 36% two themes, and 13.9% three themes. The most frequent topics for each theme or theme combination came with several key findings - prevalent reporting of psychological and physical effects during recovery, complexities in accessing buprenorphine, and significant information gaps regarding medication administration, tapering, and usage of substances during different stages of recovery. Moreover, self-treatment strategies and peer-driven advice reveal valuable insights and potential misconceptions. Conclusions: The findings obtained using our proposed framework can inform better patient education and patient-provider communication, design systematic interventions to address treatment-related misconceptions and rumors, and streamline the generation of hypotheses for future research.
MindScape Study: Integrating LLM and Behavioral Sensing for Personalized AI-Driven Journaling Experiences
Sep 15, 2024Mental health concerns are prevalent among college students, highlighting the need for effective interventions that promote self-awareness and holistic well-being. MindScape pioneers a novel approach to AI-powered journaling by integrating passively collected behavioral patterns such as conversational engagement, sleep, and location with Large Language Models (LLMs). This integration creates a highly personalized and context-aware journaling experience, enhancing self-awareness and well-being by embedding behavioral intelligence into AI. We present an 8-week exploratory study with 20 college students, demonstrating the MindScape app's efficacy in enhancing positive affect (7%), reducing negative affect (11%), loneliness (6%), and anxiety and depression, with a significant week-over-week decrease in PHQ-4 scores (-0.25 coefficient), alongside improvements in mindfulness (7%) and self-reflection (6%). The study highlights the advantages of contextual AI journaling, with participants particularly appreciating the tailored prompts and insights provided by the MindScape app. Our analysis also includes a comparison of responses to AI-driven contextual versus generic prompts, participant feedback insights, and proposed strategies for leveraging contextual AI journaling to improve well-being on college campuses. By showcasing the potential of contextual AI journaling to support mental health, we provide a foundation for further investigation into the effects of contextual AI journaling on mental health and well-being.
Deciphering Hate: Identifying Hateful Memes and Their Targets
Mar 16, 2024
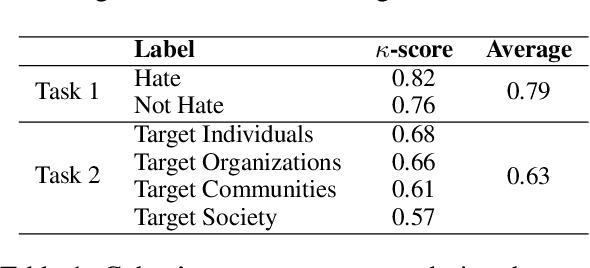
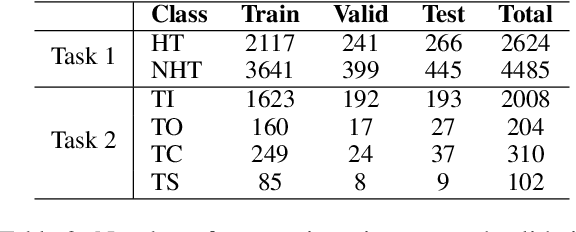
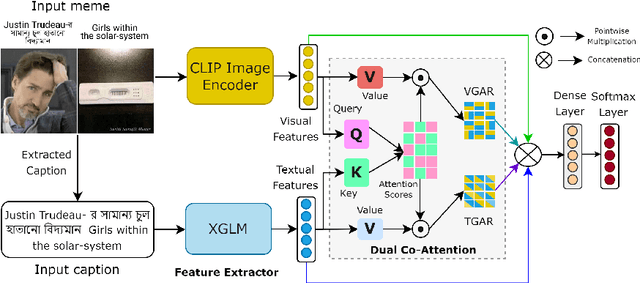
Internet memes have become a powerful means for individuals to express emotions, thoughts, and perspectives on social media. While often considered as a source of humor and entertainment, memes can also disseminate hateful content targeting individuals or communities. Most existing research focuses on the negative aspects of memes in high-resource languages, overlooking the distinctive challenges associated with low-resource languages like Bengali (also known as Bangla). Furthermore, while previous work on Bengali memes has focused on detecting hateful memes, there has been no work on detecting their targeted entities. To bridge this gap and facilitate research in this arena, we introduce a novel multimodal dataset for Bengali, BHM (Bengali Hateful Memes). The dataset consists of 7,148 memes with Bengali as well as code-mixed captions, tailored for two tasks: (i) detecting hateful memes, and (ii) detecting the social entities they target (i.e., Individual, Organization, Community, and Society). To solve these tasks, we propose DORA (Dual cO attention fRAmework), a multimodal deep neural network that systematically extracts the significant modality features from the memes and jointly evaluates them with the modality-specific features to understand the context better. Our experiments show that DORA is generalizable on other low-resource hateful meme datasets and outperforms several state-of-the-art rivaling baselines.
Mad Libs Are All You Need: Augmenting Cross-Domain Document-Level Event Argument Data
Mar 05, 2024Document-Level Event Argument Extraction (DocEAE) is an extremely difficult information extraction problem -- with significant limitations in low-resource cross-domain settings. To address this problem, we introduce Mad Lib Aug (MLA), a novel generative DocEAE data augmentation framework. Our approach leverages the intuition that Mad Libs, which are categorically masked documents used as a part of a popular game, can be generated and solved by LLMs to produce data for DocEAE. Using MLA, we achieve a 2.6-point average improvement in overall F1 score. Moreover, this approach achieves a 3.9 and 5.2 point average increase in zero and few-shot event roles compared to augmentation-free baselines across all experiments. To better facilitate analysis of cross-domain DocEAE, we additionally introduce a new metric, Role-Depth F1 (RDF1), which uses statistical depth to identify roles in the target domain which are semantic outliers with respect to roles observed in the source domain. Our experiments show that MLA augmentation can boost RDF1 performance by an average of 5.85 points compared to non-augmented datasets.
Scope of Large Language Models for Mining Emerging Opinions in Online Health Discourse
Mar 05, 2024In this paper, we develop an LLM-powered framework for the curation and evaluation of emerging opinion mining in online health communities. We formulate emerging opinion mining as a pairwise stance detection problem between (title, comment) pairs sourced from Reddit, where post titles contain emerging health-related claims on a topic that is not predefined. The claims are either explicitly or implicitly expressed by the user. We detail (i) a method of claim identification -- the task of identifying if a post title contains a claim and (ii) an opinion mining-driven evaluation framework for stance detection using LLMs. We facilitate our exploration by releasing a novel test dataset, Long COVID-Stance, or LC-stance, which can be used to evaluate LLMs on the tasks of claim identification and stance detection in online health communities. Long Covid is an emerging post-COVID disorder with uncertain and complex treatment guidelines, thus making it a suitable use case for our task. LC-Stance contains long COVID treatment related discourse sourced from a Reddit community. Our evaluation shows that GPT-4 significantly outperforms prior works on zero-shot stance detection. We then perform thorough LLM model diagnostics, identifying the role of claim type (i.e. implicit vs explicit claims) and comment length as sources of model error.
Align before Attend: Aligning Visual and Textual Features for Multimodal Hateful Content Detection
Feb 15, 2024Multimodal hateful content detection is a challenging task that requires complex reasoning across visual and textual modalities. Therefore, creating a meaningful multimodal representation that effectively captures the interplay between visual and textual features through intermediate fusion is critical. Conventional fusion techniques are unable to attend to the modality-specific features effectively. Moreover, most studies exclusively concentrated on English and overlooked other low-resource languages. This paper proposes a context-aware attention framework for multimodal hateful content detection and assesses it for both English and non-English languages. The proposed approach incorporates an attention layer to meaningfully align the visual and textual features. This alignment enables selective focus on modality-specific features before fusing them. We evaluate the proposed approach on two benchmark hateful meme datasets, viz. MUTE (Bengali code-mixed) and MultiOFF (English). Evaluation results demonstrate our proposed approach's effectiveness with F1-scores of $69.7$% and $70.3$% for the MUTE and MultiOFF datasets. The scores show approximately $2.5$% and $3.2$% performance improvement over the state-of-the-art systems on these datasets. Our implementation is available at https://github.com/eftekhar-hossain/Bengali-Hateful-Memes.