 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Sensor Models via Language-Informed Pretraining
Mar 12, 2026Modern sensing systems generate large volumes of unlabeled multivariate time-series data. This abundance of unlabeled data makes self-supervised learning (SSL) a natural approach for learning transferable representations. However, most existing approaches are optimized for reconstruction or forecasting objectives and often fail to capture the semantic structure required for downstream classification and reasoning tasks. While recent sensor-language alignment methods improve semantic generalization through captioning and zero-shot transfer, they are limited to fixed sensor configurations, such as predefined channel sets, signal lengths, or temporal resolutions, which hinders cross-domain applicability. To address these gaps, we introduce \textbf{SLIP} (\textbf{S}ensor \textbf{L}anguage-\textbf{I}nformed \textbf{P}retraining), an open-source framework for learning language-aligned representations that generalize across diverse sensor setups. SLIP integrates contrastive alignment with sensor-conditioned captioning, facilitating both discriminative understanding and generative reasoning. By repurposing a pretrained decoder-only language model via cross-attention and introducing an elegant, flexible patch-embedder, SLIP supports different temporal resolutions and variable-length input at inference time without additional retraining. Across 11 datasets, SLIP demonstrates superior performance in zero-shot transfer, signal captioning, and question answering. It achieves a 77.14% average linear-probing accuracy, a 5.93% relative improvement over strong baselines, and reaches 64.83% accuracy in sensor-based question answering.
MindScape Study: Integrating LLM and Behavioral Sensing for Personalized AI-Driven Journaling Experiences
Sep 15, 2024Mental health concerns are prevalent among college students, highlighting the need for effective interventions that promote self-awareness and holistic well-being. MindScape pioneers a novel approach to AI-powered journaling by integrating passively collected behavioral patterns such as conversational engagement, sleep, and location with Large Language Models (LLMs). This integration creates a highly personalized and context-aware journaling experience, enhancing self-awareness and well-being by embedding behavioral intelligence into AI. We present an 8-week exploratory study with 20 college students, demonstrating the MindScape app's efficacy in enhancing positive affect (7%), reducing negative affect (11%), loneliness (6%), and anxiety and depression, with a significant week-over-week decrease in PHQ-4 scores (-0.25 coefficient), alongside improvements in mindfulness (7%) and self-reflection (6%). The study highlights the advantages of contextual AI journaling, with participants particularly appreciating the tailored prompts and insights provided by the MindScape app. Our analysis also includes a comparison of responses to AI-driven contextual versus generic prompts, participant feedback insights, and proposed strategies for leveraging contextual AI journaling to improve well-being on college campuses. By showcasing the potential of contextual AI journaling to support mental health, we provide a foundation for further investigation into the effects of contextual AI journaling on mental health and well-being.
An Empirical Study of UMLS Concept Extraction from Clinical Notes using Boolean Combination Ensembles
Aug 04, 2021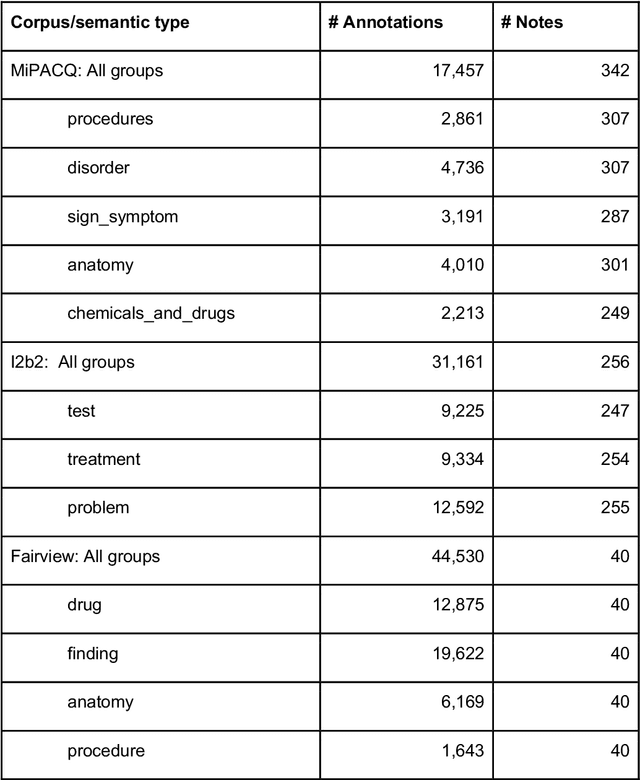
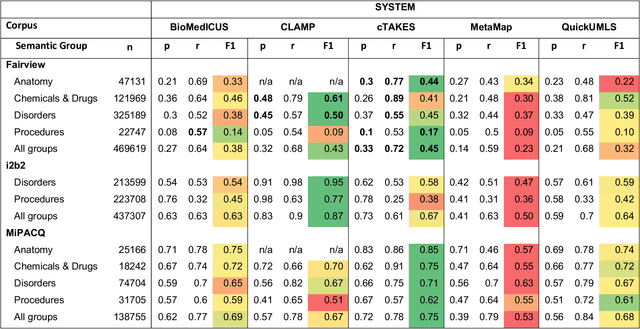
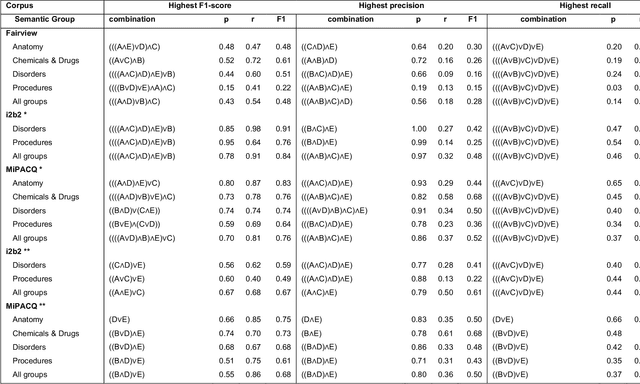
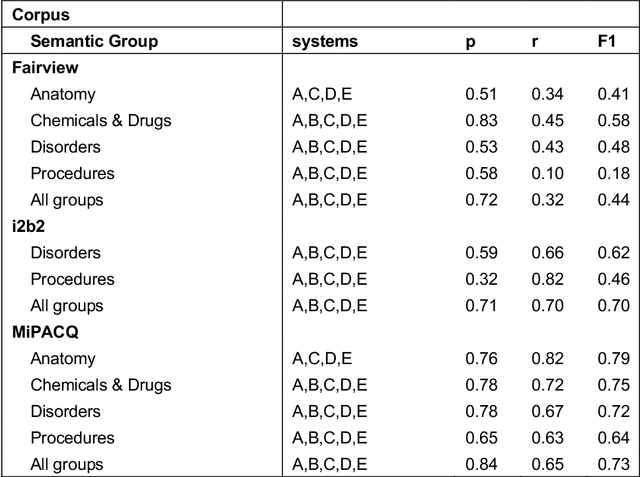
Our objective in this study is to investigate the behavior of Boolean operators on combining annotation output from multiple Natural Language Processing (NLP) systems across multiple corpora and to assess how filtering by aggregation of Unified Medical Language System (UMLS) Metathesaurus concepts affects system performance for Named Entity Recognition (NER) of UMLS concepts. We used three corpora annotated for UMLS concepts: 2010 i2b2 VA challenge set (31,161 annotations), Multi-source Integrated Platform for Answering Clinical Questions (MiPACQ) corpus (17,457 annotations including UMLS concept unique identifiers), and Fairview Health Services corpus (44,530 annotations). Our results showed that for UMLS concept matching, Boolean ensembling of the MiPACQ corpus trended towards higher performance over individual systems. Use of an approximate grid-search can help optimize the precision-recall tradeoff and can provide a set of heuristics for choosing an optimal set of ensembles.