 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of UMLS Concept Extraction from Clinical Notes using Boolean Combination Ensembles
Paper and Code
Aug 04, 2021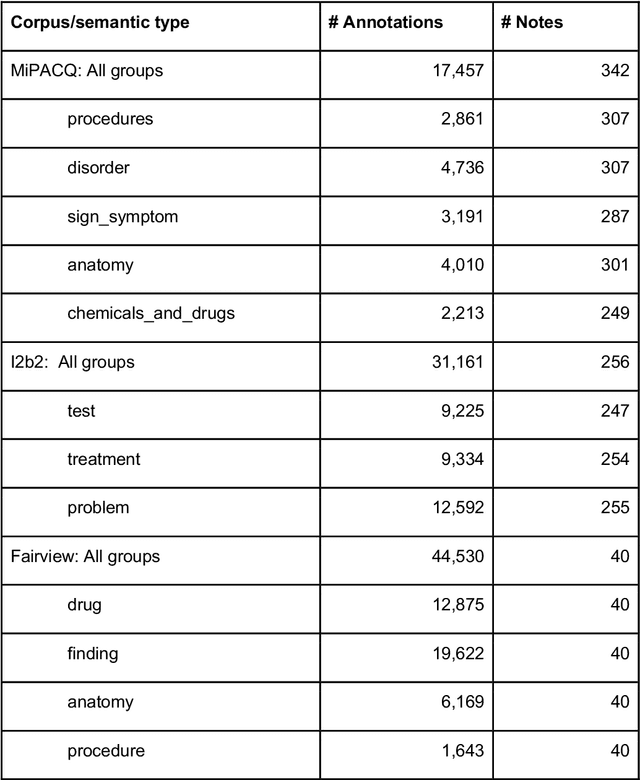
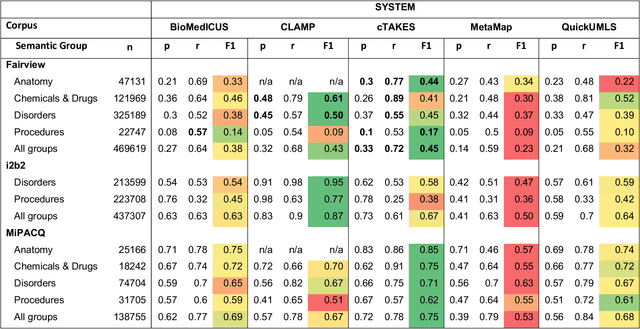
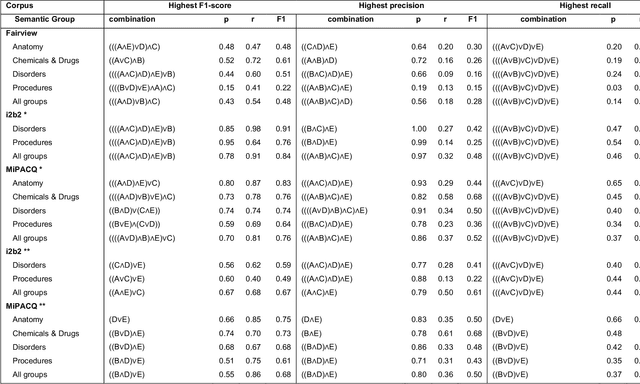
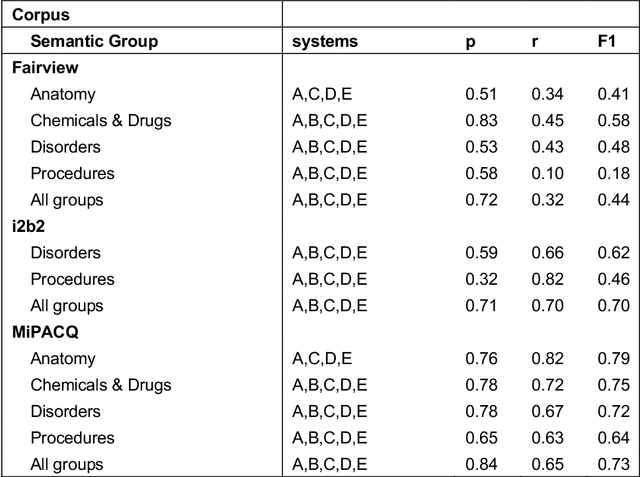
Our objective in this study is to investigate the behavior of Boolean operators on combining annotation output from multiple Natural Language Processing (NLP) systems across multiple corpora and to assess how filtering by aggregation of Unified Medical Language System (UMLS) Metathesaurus concepts affects system performance for Named Entity Recognition (NER) of UMLS concepts. We used three corpora annotated for UMLS concepts: 2010 i2b2 VA challenge set (31,161 annotations), Multi-source Integrated Platform for Answering Clinical Questions (MiPACQ) corpus (17,457 annotations including UMLS concept unique identifiers), and Fairview Health Services corpus (44,530 annotations). Our results showed that for UMLS concept matching, Boolean ensembling of the MiPACQ corpus trended towards higher performance over individual systems. Use of an approximate grid-search can help optimize the precision-recall tradeoff and can provide a set of heuristics for choosing an optimal set of ensembles.