 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Critical Role of Aspects in Measuring Document Similarity
Jan 06, 2026We introduce ASPECTSIM, a simple and interpretable framework that requires conditioning document similarity on an explicitly specified aspect, which is different from the traditional holistic approach in measuring document similarity. Experimenting with a newly constructed benchmark of 26K aspect-document pairs, we found that ASPECTSIM, when implemented with direct GPT-4o prompting, achieves substantially higher human-machine agreement ($\approx$80% higher) than the same for holistic similarity without explicit aspects. These findings underscore the importance of explicitly accounting for aspects when measuring document similarity and highlight the need to revise standard practice. Next, we conducted a large-scale meta-evaluation using 16 smaller open-source LLMs and 9 embedding models with a focus on making ASPECTSIM accessible and reproducible. While directly prompting LLMs to produce ASPECTSIM scores turned out be ineffective (20-30% human-machine agreement), a simple two-stage refinement improved their agreement by $\approx$140%. Nevertheless, agreement remains well below that of GPT-4o-based models, indicating that smaller open-source LLMs still lag behind large proprietary models in capturing aspect-conditioned similarity.
From Sight to Insight: Improving Visual Reasoning Capabilities of Multimodal Models via Reinforcement Learning
Jan 01, 2026Reinforcement learning (RL) has emerged as a promising approach for eliciting reasoning chains before generating final answers. However, multimodal large language models (MLLMs) generate reasoning that lacks integration of visual information. This limits their ability to solve problems that demand accurate visual perception, such as visual puzzles. We show that visual perception is the key bottleneck in such tasks: converting images into textual descriptions significantly improves performance, yielding gains of 26.7% for Claude 3.5 and 23.6% for Claude 3.7. To address this, we investigate reward-driven RL as a mechanism to unlock long visual reasoning in open-source MLLMs without requiring costly supervision. We design and evaluate six reward functions targeting different reasoning aspects, including image understanding, thinking steps, and answer accuracy. Using group relative policy optimization (GRPO), our approach explicitly incentivizes longer, structured reasoning and mitigates bypassing of visual information. Experiments on Qwen-2.5-VL-7B achieve 5.56% improvements over the base model, with consistent gains across both in-domain and out-of-domain settings.
Deciphering Hate: Identifying Hateful Memes and Their Targets
Mar 16, 2024
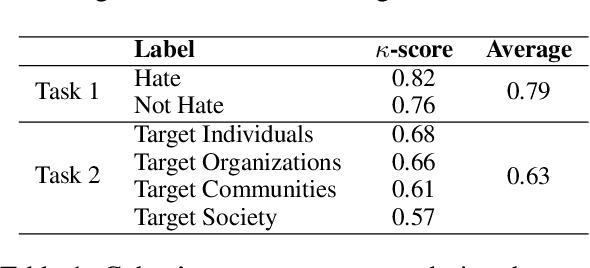
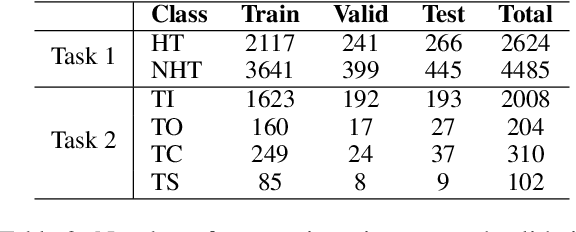
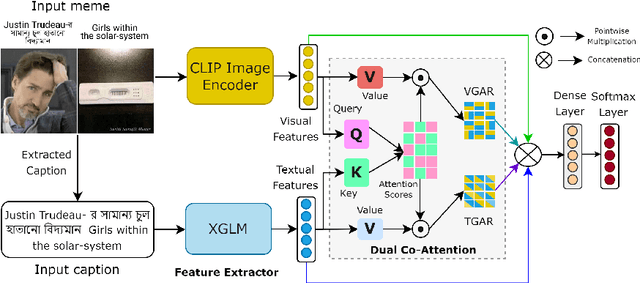
Internet memes have become a powerful means for individuals to express emotions, thoughts, and perspectives on social media. While often considered as a source of humor and entertainment, memes can also disseminate hateful content targeting individuals or communities. Most existing research focuses on the negative aspects of memes in high-resource languages, overlooking the distinctive challenges associated with low-resource languages like Bengali (also known as Bangla). Furthermore, while previous work on Bengali memes has focused on detecting hateful memes, there has been no work on detecting their targeted entities. To bridge this gap and facilitate research in this arena, we introduce a novel multimodal dataset for Bengali, BHM (Bengali Hateful Memes). The dataset consists of 7,148 memes with Bengali as well as code-mixed captions, tailored for two tasks: (i) detecting hateful memes, and (ii) detecting the social entities they target (i.e., Individual, Organization, Community, and Society). To solve these tasks, we propose DORA (Dual cO attention fRAmework), a multimodal deep neural network that systematically extracts the significant modality features from the memes and jointly evaluates them with the modality-specific features to understand the context better. Our experiments show that DORA is generalizable on other low-resource hateful meme datasets and outperforms several state-of-the-art rivaling baselines.
Align before Attend: Aligning Visual and Textual Features for Multimodal Hateful Content Detection
Feb 15, 2024Multimodal hateful content detection is a challenging task that requires complex reasoning across visual and textual modalities. Therefore, creating a meaningful multimodal representation that effectively captures the interplay between visual and textual features through intermediate fusion is critical. Conventional fusion techniques are unable to attend to the modality-specific features effectively. Moreover, most studies exclusively concentrated on English and overlooked other low-resource languages. This paper proposes a context-aware attention framework for multimodal hateful content detection and assesses it for both English and non-English languages. The proposed approach incorporates an attention layer to meaningfully align the visual and textual features. This alignment enables selective focus on modality-specific features before fusing them. We evaluate the proposed approach on two benchmark hateful meme datasets, viz. MUTE (Bengali code-mixed) and MultiOFF (English). Evaluation results demonstrate our proposed approach's effectiveness with F1-scores of $69.7$% and $70.3$% for the MUTE and MultiOFF datasets. The scores show approximately $2.5$% and $3.2$% performance improvement over the state-of-the-art systems on these datasets. Our implementation is available at https://github.com/eftekhar-hossain/Bengali-Hateful-Memes.
NLP-CUET@DravidianLangTech-EACL2021: Investigating Visual and Textual Features to Identify Trolls from Multimodal Social Media Memes
Feb 28, 2021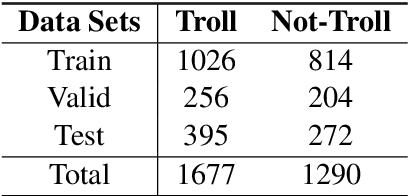
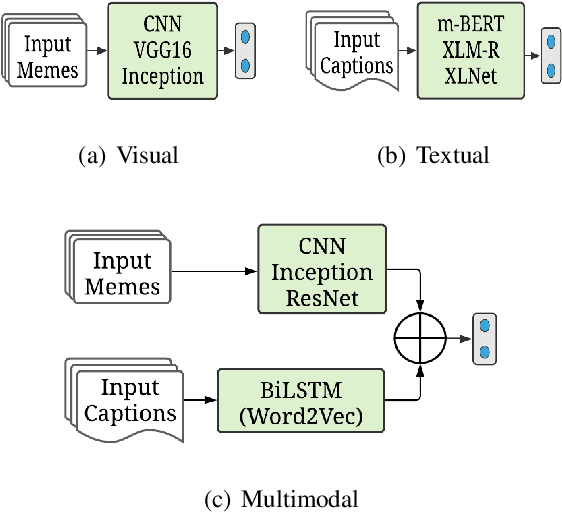
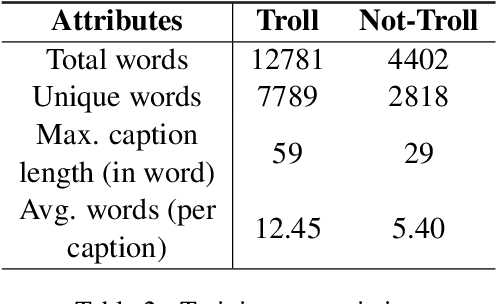
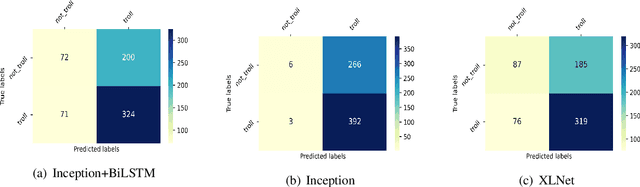
In the past few years, the meme has become a new way of communication on the Internet. As memes are the images with embedded text, it can quickly spread hate, offence and violence. Classifying memes are very challenging because of their multimodal nature and region-specific interpretation. A shared task is organized to develop models that can identify trolls from multimodal social media memes. This work presents a computational model that we have developed as part of our participation in the task. Training data comes in two forms: an image with embedded Tamil code-mixed text and an associated caption given in English. We investigated the visual and textual features using CNN, VGG16, Inception, Multilingual-BERT, XLM-Roberta, XLNet models. Multimodal features are extracted by combining image (CNN, ResNet50, Inception) and text (Long short term memory network) features via early fusion approach. Results indicate that the textual approach with XLNet achieved the highest weighted $f_1$-score of $0.58$, which enabled our model to secure $3^{rd}$ rank in this task.
NLP-CUET@LT-EDI-EACL2021: Multilingual Code-Mixed Hope Speech Detection using Cross-lingual Representation Learner
Feb 28, 2021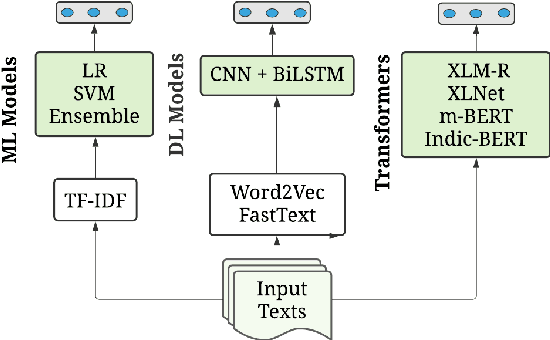
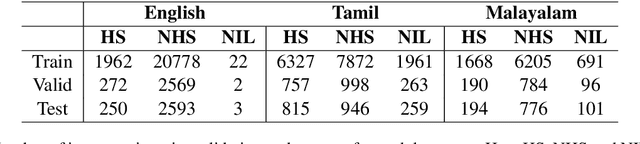
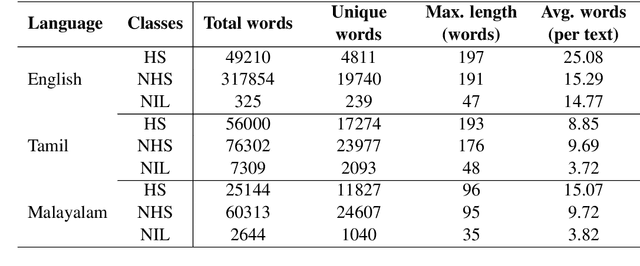
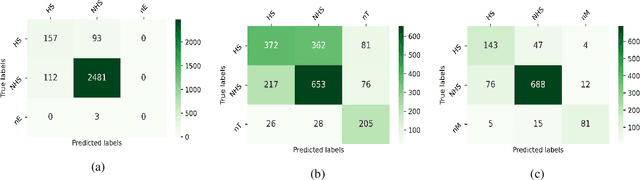
In recent years, several systems have been developed to regulate the spread of negativity and eliminate aggressive, offensive or abusive contents from the online platforms. Nevertheless, a limited number of researches carried out to identify positive, encouraging and supportive contents. In this work, our goal is to identify whether a social media post/comment contains hope speech or not. We propose three distinct models to identify hope speech in English, Tamil and Malayalam language to serve this purpose. To attain this goal, we employed various machine learning (support vector machine, logistic regression, ensemble), deep learning (convolutional neural network + long short term memory) and transformer (m-BERT, Indic-BERT, XLNet, XLM-Roberta) based methods. Results indicate that XLM-Roberta outdoes all other techniques by gaining a weighted $f_1$-score of $0.93$, $0.60$ and $0.85$ respectively for English, Tamil and Malayalam language. Our team has achieved $1^{st}$, $2^{nd}$ and $1^{st}$ rank in these three tasks respectively.
NLP-CUET@DravidianLangTech-EACL2021: Offensive Language Detection from Multilingual Code-Mixed Text using Transformers
Feb 28, 2021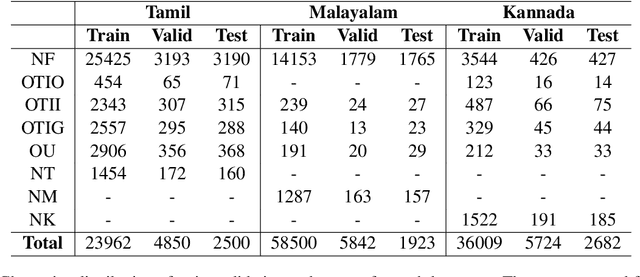
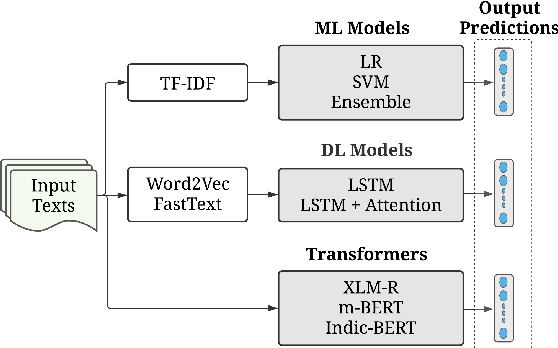
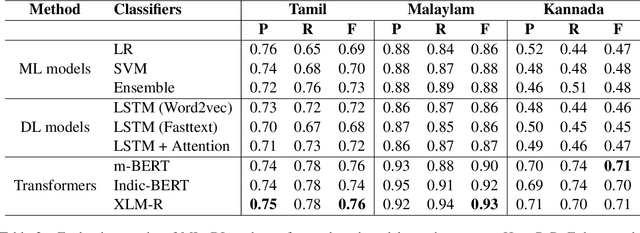
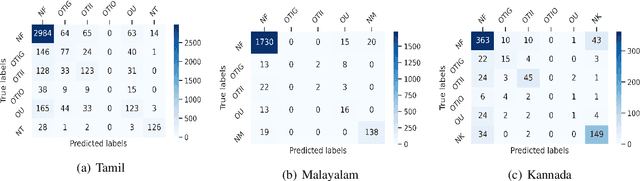
The increasing accessibility of the internet facilitated social media usage and encouraged individuals to express their opinions liberally. Nevertheless, it also creates a place for content polluters to disseminate offensive posts or contents. Most of such offensive posts are written in a cross-lingual manner and can easily evade the online surveillance systems. This paper presents an automated system that can identify offensive text from multilingual code-mixed data. In the task, datasets provided in three languages including Tamil, Malayalam and Kannada code-mixed with English where participants are asked to implement separate models for each language. To accomplish the tasks, we employed two machine learning techniques (LR, SVM), three deep learning (LSTM, LSTM+Attention) techniques and three transformers (m-BERT, Indic-BERT, XLM-R) based methods. Results show that XLM-R outperforms other techniques in Tamil and Malayalam languages while m-BERT achieves the highest score in the Kannada language. The proposed models gained weighted $f_1$ score of $0.76$ (for Tamil), $0.93$ (for Malayalam), and $0.71$ (for Kannada) with a rank of $3^{rd}$, $5^{th}$ and $4^{th}$ respectively.
Combating Hostility: Covid-19 Fake News and Hostile Post Detection in Social Media
Jan 09, 2021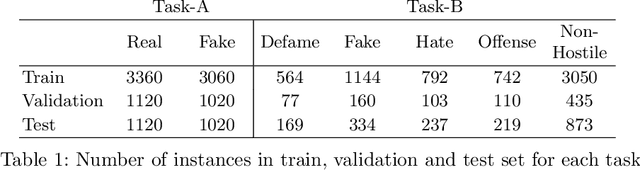
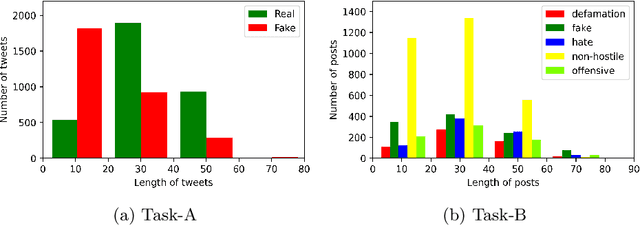
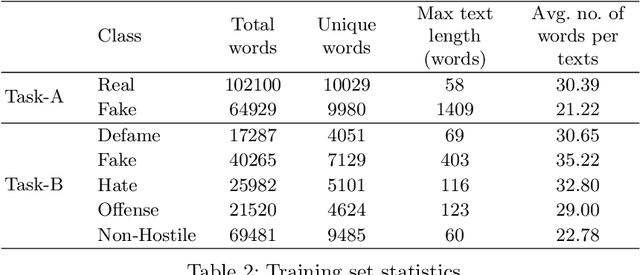
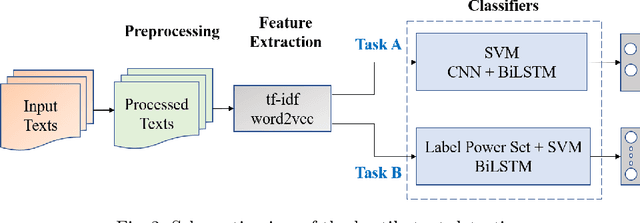
This paper illustrates a detail description of the system and its results that developed as a part of the participation at CONSTRAINT shared task in AAAI-2021. The shared task comprises two tasks: a) COVID19 fake news detection in English b) Hostile post detection in Hindi. Task-A is a binary classification problem with fake and real class, while task-B is a multi-label multi-class classification task with five hostile classes (i.e. defame, fake, hate, offense, non-hostile). Various techniques are used to perform the classification task, including SVM, CNN, BiLSTM, and CNN+BiLSTM with tf-idf and Word2Vec embedding techniques. Results indicate that SVM with tf-idf features achieved the highest 94.39% weighted $f_1$ score on the test set in task-A. Label powerset SVM with n-gram features obtained the maximum coarse-grained and fine-grained $f_1$ score of 86.03% and 50.98% on the task-B test set respectively.
TechTexC: Classification of Technical Texts using Convolution and Bidirectional Long Short Term Memory Network
Dec 21, 2020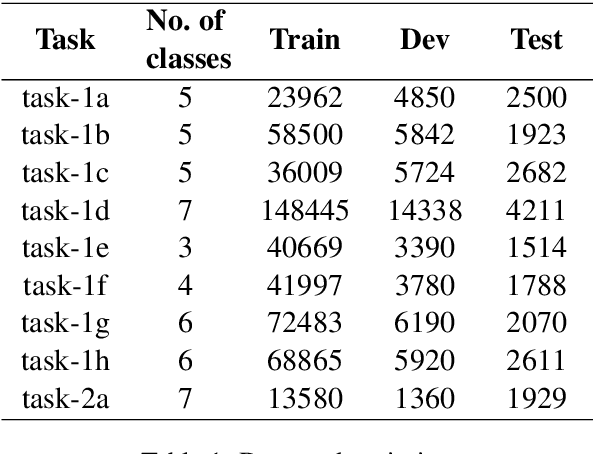
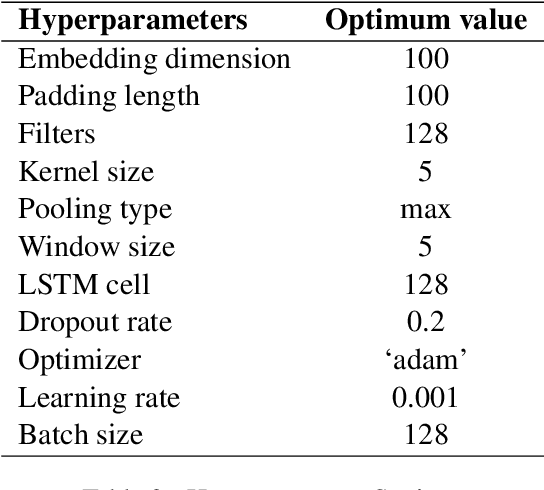
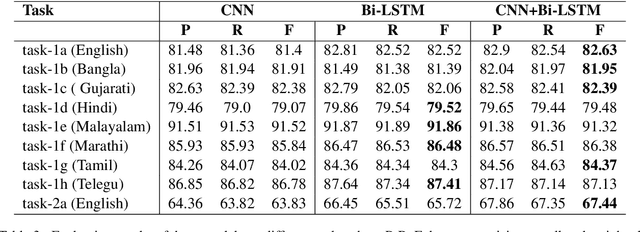
This paper illustrates the details description of technical text classification system and its results that developed as a part of participation in the shared task TechDofication 2020. The shared task consists of two sub-tasks: (i) first task identify the coarse-grained technical domain of given text in a specified language and (ii) the second task classify a text of computer science domain into fine-grained sub-domains. A classification system (called 'TechTexC') is developed to perform the classification task using three techniques: convolution neural network (CNN), bidirectional long short term memory (BiLSTM) network, and combined CNN with BiLSTM. Results show that CNN with BiLSTM model outperforms the other techniques concerning task-1 of sub-tasks (a, b, c and g) and task-2a. This combined model obtained f1 scores of 82.63 (sub-task a), 81.95 (sub-task b), 82.39 (sub-task c), 84.37 (sub-task g), and 67.44 (task-2a) on the development dataset. Moreover, in the case of test set, the combined CNN with BiLSTM approach achieved that higher accuracy for the subtasks 1a (70.76%), 1b (79.97%), 1c (65.45%), 1g (49.23%) and 2a (70.14%).
SentiLSTM: A Deep Learning Approach for Sentiment Analysis of Restaurant Reviews
Nov 19, 2020
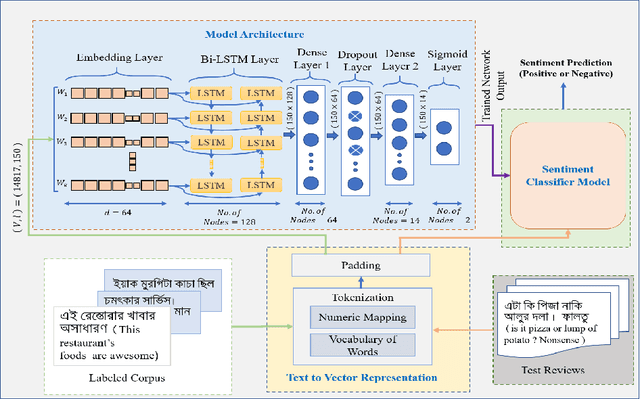
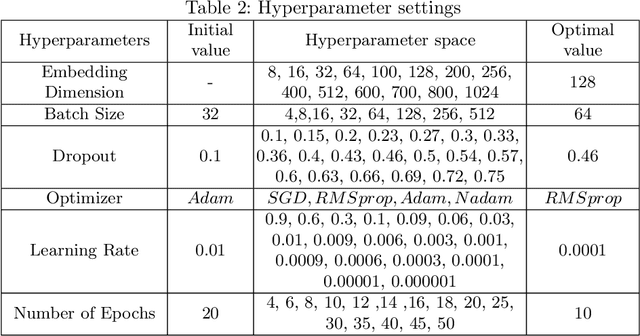
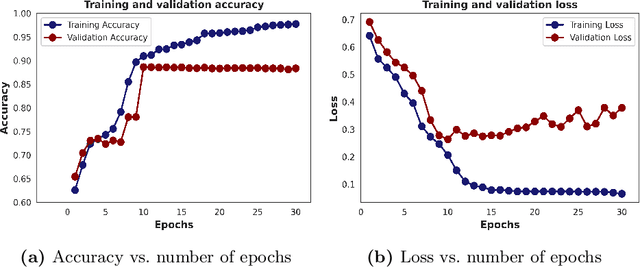
The amount of textual data generation has increased enormously due to the effortless access of the Internet and the evolution of various web 2.0 applications. These textual data productions resulted because of the people express their opinion, emotion or sentiment about any product or service in the form of tweets, Facebook post or status, blog write up, and reviews. Sentiment analysis deals with the process of computationally identifying and categorizing opinions expressed in a piece of text, especially in order to determine whether the writer's attitude toward a particular topic is positive, negative, or neutral. The impact of customer review is significant to perceive the customer attitude towards a restaurant. Thus, the automatic detection of sentiment from reviews is advantageous for the restaurant owners, or service providers and customers to make their decisions or services more satisfactory. This paper proposes, a deep learning-based technique (i.e., BiLSTM) to classify the reviews provided by the clients of the restaurant into positive and negative polarities. A corpus consists of 8435 reviews is constructed to evaluate the proposed technique. In addition, a comparative analysis of the proposed technique with other machine learning algorithms presented. The results of the evaluation on test dataset show that BiLSTM technique produced in the highest accuracy of 91.35%.