 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechTexC: Classification of Technical Texts using Convolution and Bidirectional Long Short Term Memory Network
Paper and Code
Dec 21, 2020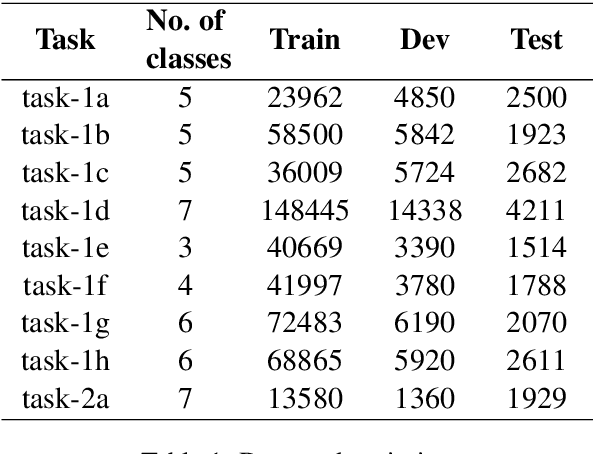
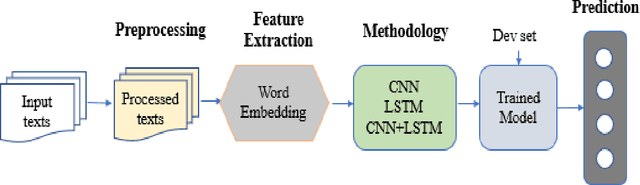
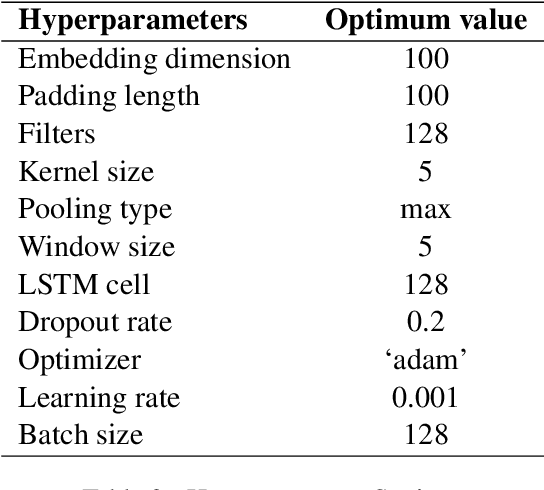
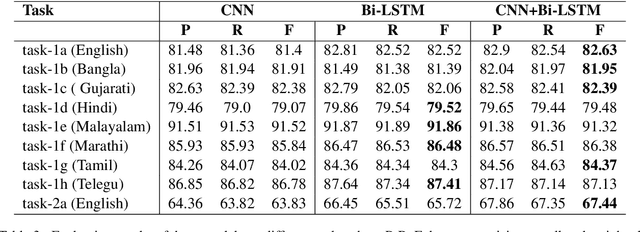
This paper illustrates the details description of technical text classification system and its results that developed as a part of participation in the shared task TechDofication 2020. The shared task consists of two sub-tasks: (i) first task identify the coarse-grained technical domain of given text in a specified language and (ii) the second task classify a text of computer science domain into fine-grained sub-domains. A classification system (called 'TechTexC') is developed to perform the classification task using three techniques: convolution neural network (CNN), bidirectional long short term memory (BiLSTM) network, and combined CNN with BiLSTM. Results show that CNN with BiLSTM model outperforms the other techniques concerning task-1 of sub-tasks (a, b, c and g) and task-2a. This combined model obtained f1 scores of 82.63 (sub-task a), 81.95 (sub-task b), 82.39 (sub-task c), 84.37 (sub-task g), and 67.44 (task-2a) on the development dataset. Moreover, in the case of test set, the combined CNN with BiLSTM approach achieved that higher accuracy for the subtasks 1a (70.76%), 1b (79.97%), 1c (65.45%), 1g (49.23%) and 2a (70.14%).