 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP-CUET@DravidianLangTech-EACL2021: Investigating Visual and Textual Features to Identify Trolls from Multimodal Social Media Memes
Paper and Code
Feb 28, 2021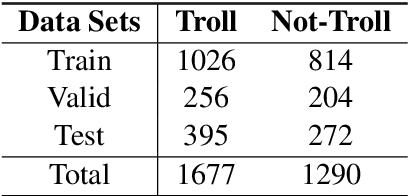
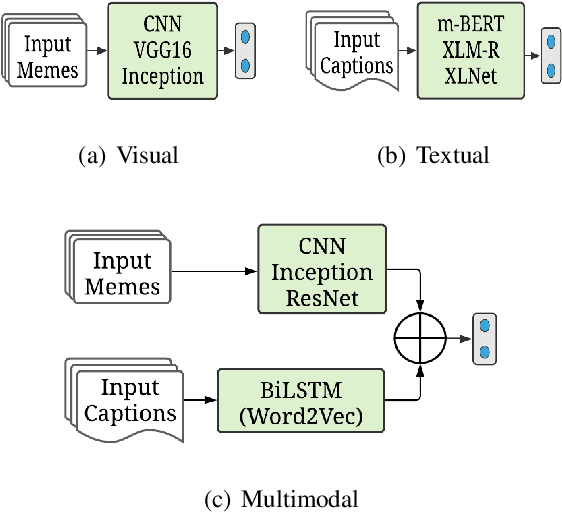
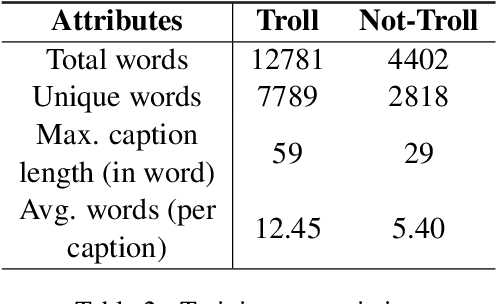
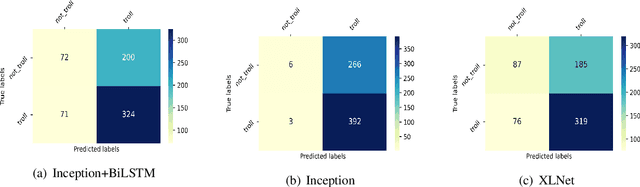
In the past few years, the meme has become a new way of communication on the Internet. As memes are the images with embedded text, it can quickly spread hate, offence and violence. Classifying memes are very challenging because of their multimodal nature and region-specific interpretation. A shared task is organized to develop models that can identify trolls from multimodal social media memes. This work presents a computational model that we have developed as part of our participation in the task. Training data comes in two forms: an image with embedded Tamil code-mixed text and an associated caption given in English. We investigated the visual and textual features using CNN, VGG16, Inception, Multilingual-BERT, XLM-Roberta, XLNet models. Multimodal features are extracted by combining image (CNN, ResNet50, Inception) and text (Long short term memory network) features via early fusion approach. Results indicate that the textual approach with XLNet achieved the highest weighted $f_1$-score of $0.58$, which enabled our model to secure $3^{rd}$ rank in this task.