 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP-CUET@DravidianLangTech-EACL2021: Offensive Language Detection from Multilingual Code-Mixed Text using Transformers
Paper and Code
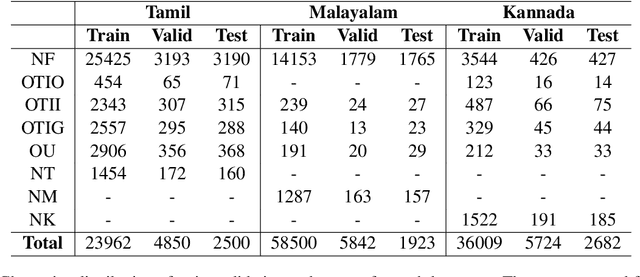
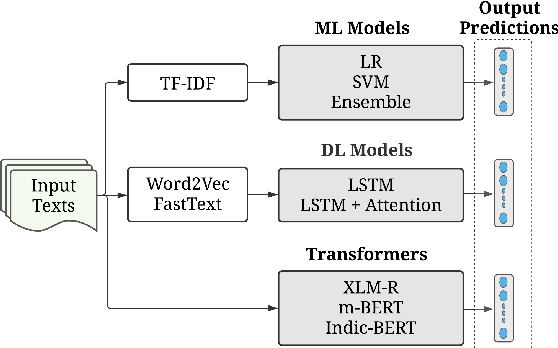
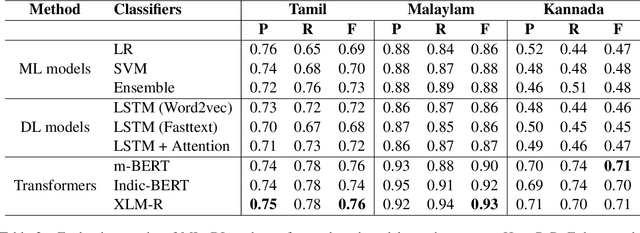
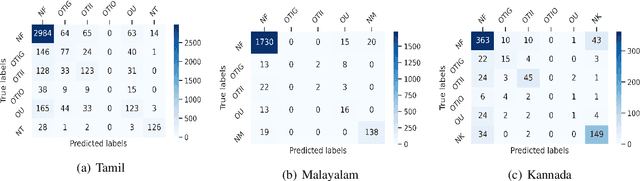
The increasing accessibility of the internet facilitated social media usage and encouraged individuals to express their opinions liberally. Nevertheless, it also creates a place for content polluters to disseminate offensive posts or contents. Most of such offensive posts are written in a cross-lingual manner and can easily evade the online surveillance systems. This paper presents an automated system that can identify offensive text from multilingual code-mixed data. In the task, datasets provided in three languages including Tamil, Malayalam and Kannada code-mixed with English where participants are asked to implement separate models for each language. To accomplish the tasks, we employed two machine learning techniques (LR, SVM), three deep learning (LSTM, LSTM+Attention) techniques and three transformers (m-BERT, Indic-BERT, XLM-R) based methods. Results show that XLM-R outperforms other techniques in Tamil and Malayalam languages while m-BERT achieves the highest score in the Kannada language. The proposed models gained weighted $f_1$ score of $0.76$ (for Tamil), $0.93$ (for Malayalam), and $0.71$ (for Kannada) with a rank of $3^{rd}$, $5^{th}$ and $4^{th}$ respectively.