 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD2M: A Decentralized, Privacy-Preserving, Incentive-Compatible Data Marketplace for Collaborative Learning
Dec 11, 2025The rising demand for collaborative machine learning and data analytics calls for secure and decentralized data sharing frameworks that balance privacy, trust, and incentives. Existing approaches, including federated learning (FL) and blockchain-based data markets, fall short: FL often depends on trusted aggregators and lacks Byzantine robustness, while blockchain frameworks struggle with computation-intensive training and incentive integration. We present \prot, a decentralized data marketplace that unifies federated learning, blockchain arbitration, and economic incentives into a single framework for privacy-preserving data sharing. \prot\ enables data buyers to submit bid-based requests via blockchain smart contracts, which manage auctions, escrow, and dispute resolution. Computationally intensive training is delegated to \cone\ (\uline{Co}mpute \uline{N}etwork for \uline{E}xecution), an off-chain distributed execution layer. To safeguard against adversarial behavior, \prot\ integrates a modified YODA protocol with exponentially growing execution sets for resilient consensus, and introduces Corrected OSMD to mitigate malicious or low-quality contributions from sellers. All protocols are incentive-compatible, and our game-theoretic analysis establishes honesty as the dominant strategy. We implement \prot\ on Ethereum and evaluate it over benchmark datasets -- MNIST, Fashion-MNIST, and CIFAR-10 -- under varying adversarial settings. \prot\ achieves up to 99\% accuracy on MNIST and 90\% on Fashion-MNIST, with less than 3\% degradation up to 30\% Byzantine nodes, and 56\% accuracy on CIFAR-10 despite its complexity. Our results show that \prot\ ensures privacy, maintains robustness under adversarial conditions, and scales efficiently with the number of participants, making it a practical foundation for real-world decentralized data sharing.
Scope of Large Language Models for Mining Emerging Opinions in Online Health Discourse
Mar 05, 2024In this paper, we develop an LLM-powered framework for the curation and evaluation of emerging opinion mining in online health communities. We formulate emerging opinion mining as a pairwise stance detection problem between (title, comment) pairs sourced from Reddit, where post titles contain emerging health-related claims on a topic that is not predefined. The claims are either explicitly or implicitly expressed by the user. We detail (i) a method of claim identification -- the task of identifying if a post title contains a claim and (ii) an opinion mining-driven evaluation framework for stance detection using LLMs. We facilitate our exploration by releasing a novel test dataset, Long COVID-Stance, or LC-stance, which can be used to evaluate LLMs on the tasks of claim identification and stance detection in online health communities. Long Covid is an emerging post-COVID disorder with uncertain and complex treatment guidelines, thus making it a suitable use case for our task. LC-Stance contains long COVID treatment related discourse sourced from a Reddit community. Our evaluation shows that GPT-4 significantly outperforms prior works on zero-shot stance detection. We then perform thorough LLM model diagnostics, identifying the role of claim type (i.e. implicit vs explicit claims) and comment length as sources of model error.
Two-stage Deep Stacked Autoencoder with Shallow Learning for Network Intrusion Detection System
Dec 03, 2021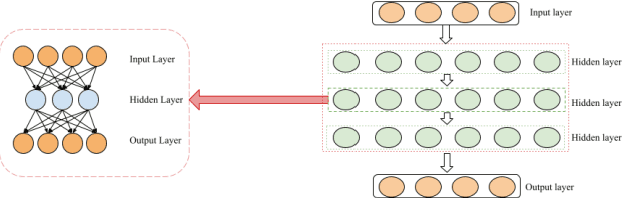
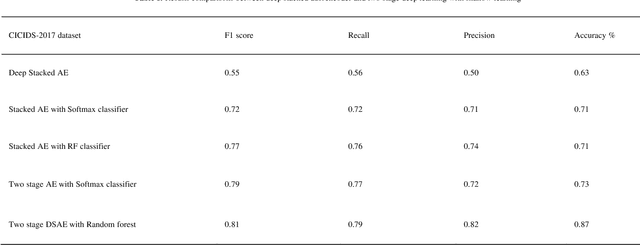
Sparse events, such as malign attacks in real-time network traffic, have caused big organisations an immense hike in revenue loss. This is due to the excessive growth of the network and its exposure to a plethora of people. The standard methods used to detect intrusions are not promising and have significant failure to identify new malware. Moreover, the challenges in handling high volume data with sparsity, high false positives, fewer detection rates in minor class, training time and feature engineering of the dimensionality of data has promoted deep learning to take over the task with less time and great results. The existing system needs improvement in solving real-time network traffic issues along with feature engineering. Our proposed work overcomes these challenges by giving promising results using deep-stacked autoencoders in two stages. The two-stage deep learning combines with shallow learning using the random forest for classification in the second stage. This made the model get well with the latest Canadian Institute for Cybersecurity - Intrusion Detection System 2017 (CICIDS-2017) dataset. Zero false positives with admirable detection accuracy were achieved.
Water Care: Water Surface Cleaning Bot and Water Body Surveillance System
Nov 24, 2021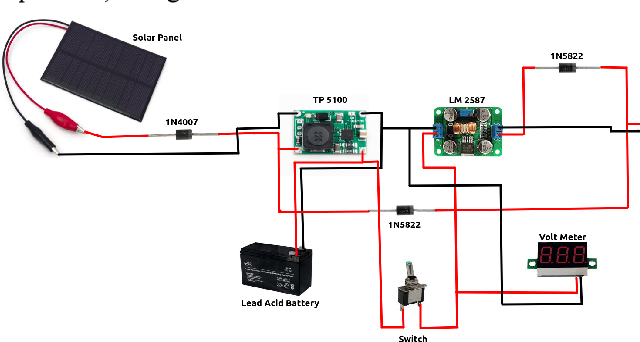
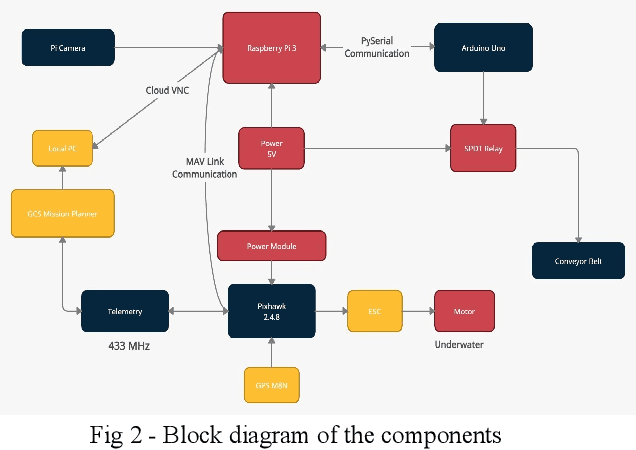
Whenever a person hears about pollution, more often than not, the first thought that comes to their mind is air pollution. One of the most under-mentioned and under-discussed pollution globally is that caused by the non-biodegradable waste in our water bodies. In the case of India, there is a lot of plastic waste on the surface of rivers and lakes. The Ganga river is one of the 10 rivers which account for 90 percent of the plastic that ends up in the sea and there are major cases of local nalaas and lakes being contaminated due to this waste. This limits the source of clean water which leads to major depletion in water sources. From 2001 to 2012, in the city of Hyderabad, 3245 hectares of lakes dissipated. The water recedes by nine feet a year on average in southern New Delhi. Thus, cleaning of these local water bodies and rivers is of utmost importance. Our aim is to develop a water surface cleaning bot that is deployed across the shore. The bot will detect garbage patches on its way and collect the garbage thus making the water bodies clean. This solution employs a surveillance mechanism in order to alert the authorities in case anyone is found polluting the water bodies. A more sustainable system by using solar energy to power the system has been developed. Computer vision algorithms are used for detecting trash on the surface of the water. This trash is collected by the bot and is disposed of at a designated location. In addition to cleaning the water bodies, preventive measures have been also implemented with the help of a virtual fencing algorithm that alerts the authorities if anyone tries to pollute the water premises. A web application and a mobile app is deployed to keep a check on the movement of the bot and shore surveillance respectively. This complete solution involves both preventive and curative measures that are required for water care.
Autonomous bot with ML-based reactive navigation for indoor environment
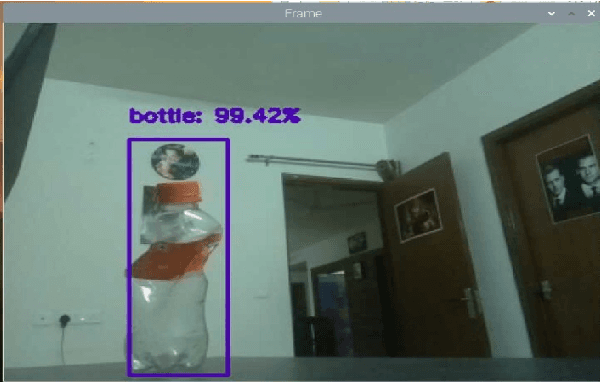
Nov 24, 2021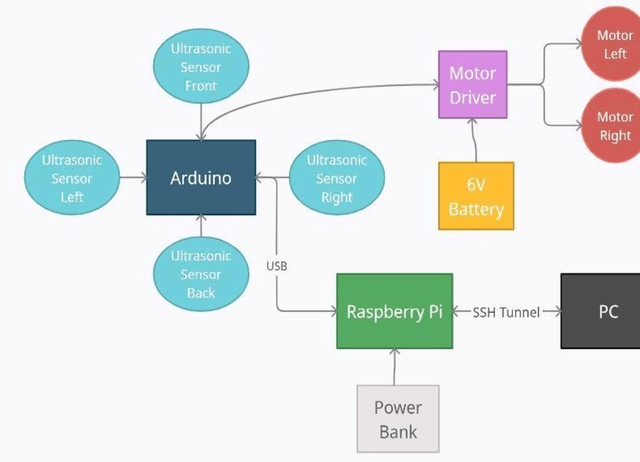
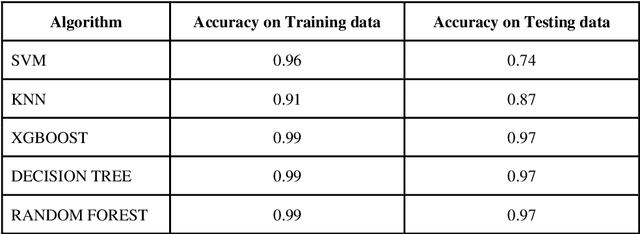
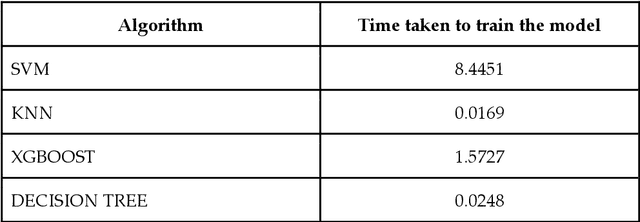
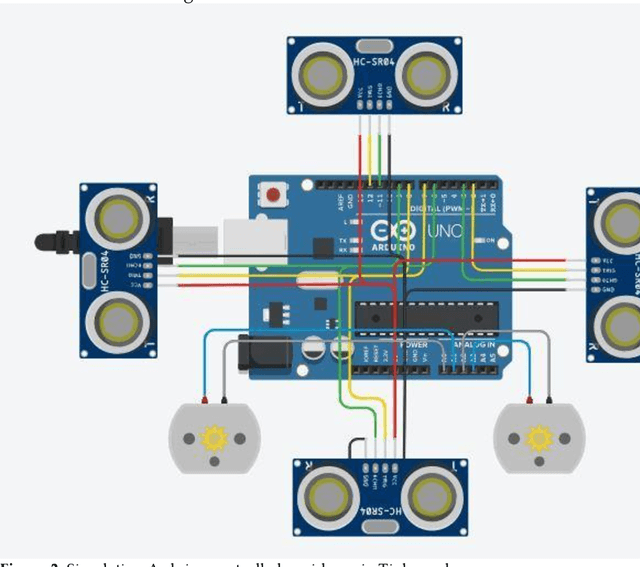
Local or reactive navigation is essential for autonomous mobile robots which operate in an indoor environment. Techniques such as SLAM, computer vision require significant computational power which increases cost. Similarly, using rudimentary methods makes the robot susceptible to inconsistent behavior. This paper aims to develop a robot that balances cost and accuracy by using machine learning to predict the best obstacle avoidance move based on distance inputs from four ultrasonic sensors that are strategically mounted on the front, front-left, front-right, and back of the robot. The underlying hardware consists of an Arduino Uno and a Raspberry Pi 3B. The machine learning model is first trained on the data collected by the robot. Then the Arduino continuously polls the sensors and calculates the distance values, and in case of critical need for avoidance, a suitable maneuver is made by the Arduino. In other scenarios, sensor data is sent to the Raspberry Pi using a USB connection and the machine learning model generates the best move for navigation, which is sent to the Arduino for driving motors accordingly. The system is mounted on a 2-WD robot chassis and tested in a cluttered indoor setting with most impressive results.
PSNet: Parametric Sigmoid Norm Based CNN for Face Recognition
Dec 05, 2019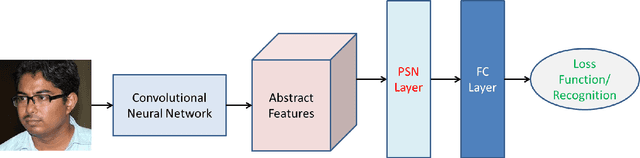

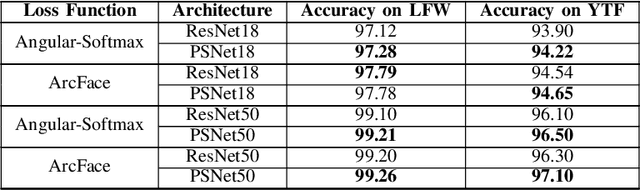
The Convolutional Neural Networks (CNN) have become very popular recently due to its outstanding performance in various computer vision applications. It is also used over widely studied face recognition problem. However, the existing layers of CNN are unable to cope with the problem of hard examples which generally produce lower class scores. Thus, the existing methods become biased towards the easy examples. In this paper, we resolve this problem by incorporating a Parametric Sigmoid Norm (PSN) layer just before the final fully-connected layer. We propose a PSNet CNN model by using the PSN layer. The PSN layer facilitates high gradient flow for harder examples as compared to easy examples. Thus, it forces the network to learn the visual characteristics of hard examples. We conduct the face recognition experiments to test the performance of PSN layer. The suitability of the PSN layer with different loss functions is also experimented. The widely used Labeled Faces in the Wild (LFW) and YouTube Faces (YTF) datasets are used in the experiments. The experimental results confirm the relevance of the proposed PSN layer.
Visual Question Answering using Deep Learning: A Survey and Performance Analysis
Aug 27, 2019
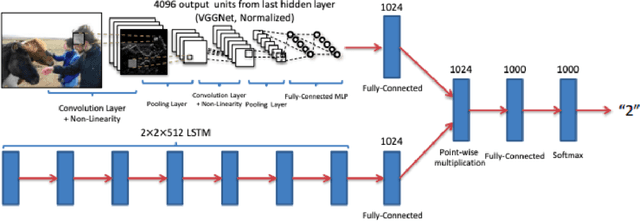
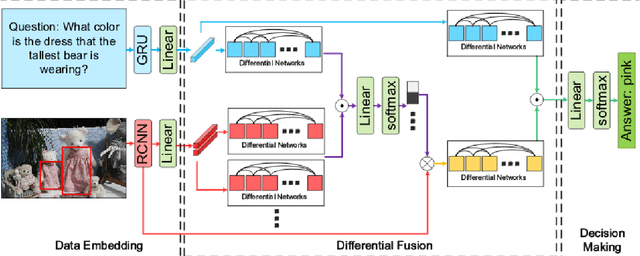
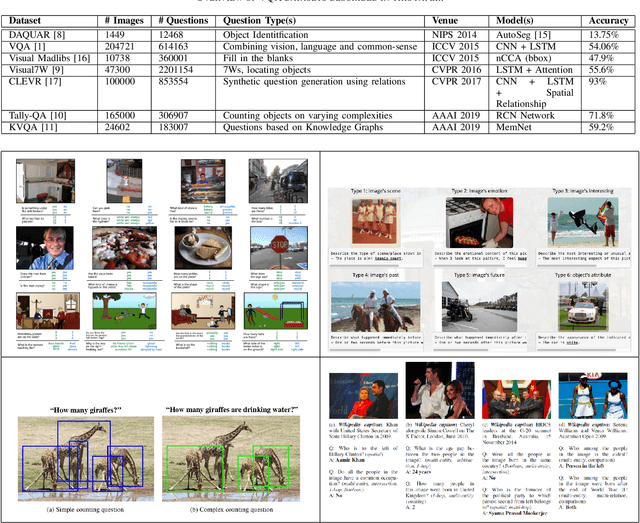
The Visual Question Answering (VQA) task combines challenges for processing data with both Visual and Linguistic processing, to answer basic `common sense' questions about given images. Given an image and a question in natural language, the VQA system tries to find the correct answer to it using visual elements of the image and inference gathered from textual questions. In this survey, we cover and discuss the recent datasets released in the VQA domain dealing with various types of question-formats and enabling robustness of the machine-learning models. Next, we discuss about new deep learning models that have shown promising results over the VQA datasets. At the end, we present and discuss some of the results computed by us over the vanilla VQA models, Stacked Attention Network and the VQA Challenge 2017 winner model. We also provide the detailed analysis along with the challenges and future research directions.
Hard-Mining Loss based Convolutional Neural Network for Face Recognition
Aug 09, 2019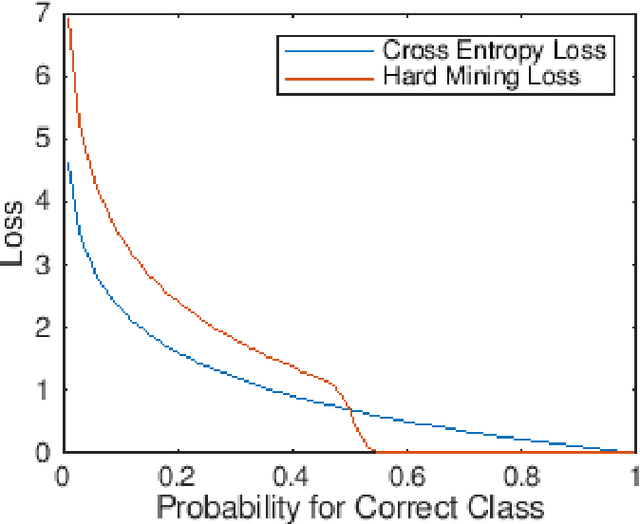

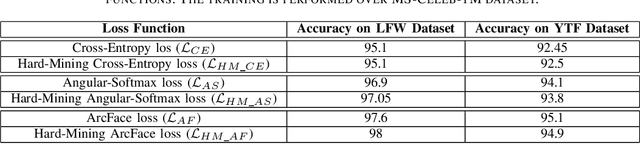
Face Recognition is one of the prominent problems in the computer vision domain. Witnessing advances in deep learning, significant work has been observed in face recognition, which touched upon various parts of the recognition framework like Convolutional Neural Network (CNN), Layers, Loss functions, etc. Various loss functions such as Cross-Entropy, Angular-Softmax and ArcFace have been introduced to learn the weights of network for face recognition. However, these loss functions are not able to priorities the hard samples as compared to easy samples. Moreover, their learning process is biased due to a number of easy examples compared to hard examples. In this paper, we address this issue by considering hard examples with more priority. In order to do so, We propose a Hard-Mining loss by by increasing the loss for harder examples and decreasing the loss for easy examples. The proposed concept is generic and can be used with any existing loss function. We test the Hard-Mining loss with different losses such as Cross-Entropy, Angular-Softmax and ArcFace. The proposed Hard-Mining loss is tested over widely used the Labeled Faces in the Wild (LFW) and YouTube Faces (YTF) datasets while training is performed over CASIA-WebFace and MS-Celeb-1M datasets. We use the residual network (i.e., ResNet18) for the experimental analysis. The experimental results suggest that the performance of existing loss functions is boosted when used in the framework of the proposed Hard-Mining loss.
A Performance Comparison of Loss Functions for Deep Face Recognition
Jan 01, 2019
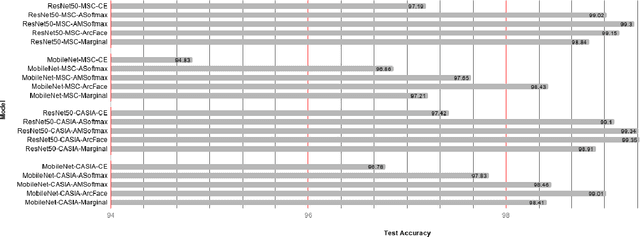

The emergence of biometric tools and its increased usage in day to day devices has brought simplicity in the authentication process for the users as compared to the passwords and pattern locks being used. The ease of use of biometric reduces the manual work and helps in faster and automatic authentication. Among different biometric traits, the face is one which can be captured without much cooperation of users. Moreover, face recognition is one of the most widely publicized feature in the devices today and hence represents an important problem that should be studied with the utmost priority. As per the recent trends, the Convolutional Neural Network (CNN) based approaches are highly successful in many tasks of Computer Vision including face recognition. The loss function is used on the top of CNN to judge the goodness of any network. The loss functions play an important role in CNN training. Basically, it generates a huge loss, if the network does not perform well using the current parameter setting. In this paper, we present a performance comparison of different loss functions such as Cross-Entropy, Angular Softmax, Additive-Margin Softmax, ArcFace and Marginal Loss for face recognition. The experiments are conducted with two CNN architectures namely, ResNet and MobileNet. Two widely used face datasets namely, CASIA-Webface and MS-Celeb-1M are used for the training and benchmark Labeled Faces in the Wild (LFW) face dataset is used for the testing. The training and test results are analyzed in this paper.