 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSNet: Parametric Sigmoid Norm Based CNN for Face Recognition
Dec 05, 2019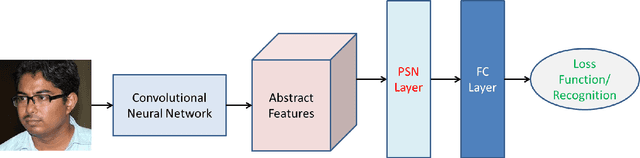

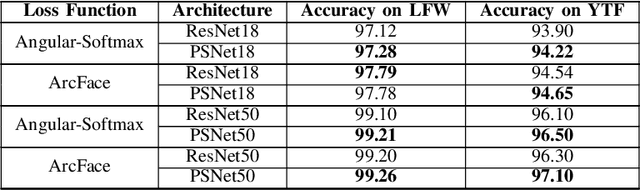
The Convolutional Neural Networks (CNN) have become very popular recently due to its outstanding performance in various computer vision applications. It is also used over widely studied face recognition problem. However, the existing layers of CNN are unable to cope with the problem of hard examples which generally produce lower class scores. Thus, the existing methods become biased towards the easy examples. In this paper, we resolve this problem by incorporating a Parametric Sigmoid Norm (PSN) layer just before the final fully-connected layer. We propose a PSNet CNN model by using the PSN layer. The PSN layer facilitates high gradient flow for harder examples as compared to easy examples. Thus, it forces the network to learn the visual characteristics of hard examples. We conduct the face recognition experiments to test the performance of PSN layer. The suitability of the PSN layer with different loss functions is also experimented. The widely used Labeled Faces in the Wild (LFW) and YouTube Faces (YTF) datasets are used in the experiments. The experimental results confirm the relevance of the proposed PSN layer.
Visual Question Answering using Deep Learning: A Survey and Performance Analysis
Aug 27, 2019
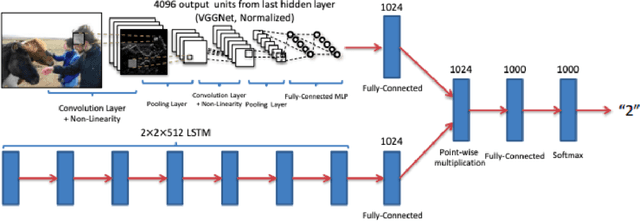
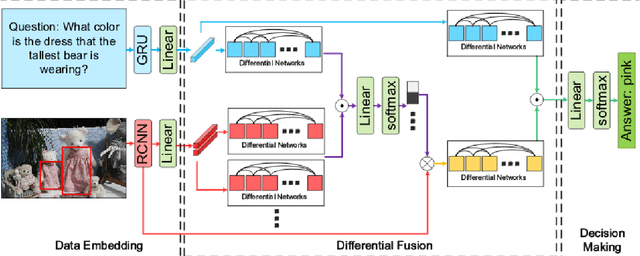
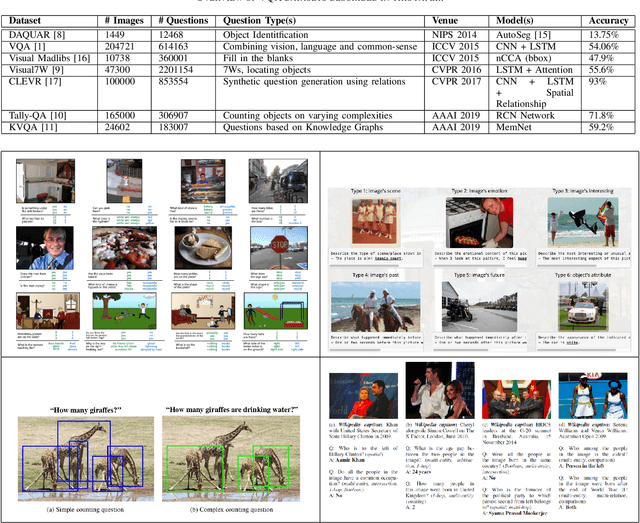
The Visual Question Answering (VQA) task combines challenges for processing data with both Visual and Linguistic processing, to answer basic `common sense' questions about given images. Given an image and a question in natural language, the VQA system tries to find the correct answer to it using visual elements of the image and inference gathered from textual questions. In this survey, we cover and discuss the recent datasets released in the VQA domain dealing with various types of question-formats and enabling robustness of the machine-learning models. Next, we discuss about new deep learning models that have shown promising results over the VQA datasets. At the end, we present and discuss some of the results computed by us over the vanilla VQA models, Stacked Attention Network and the VQA Challenge 2017 winner model. We also provide the detailed analysis along with the challenges and future research directions.
Hard-Mining Loss based Convolutional Neural Network for Face Recognition
Aug 09, 2019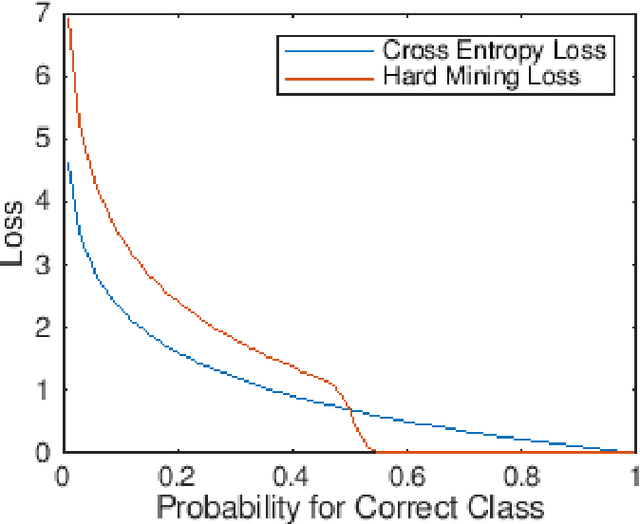

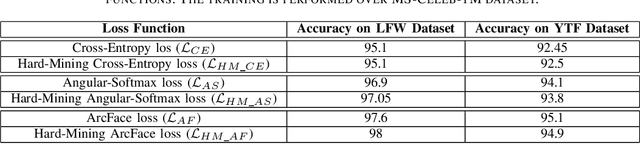
Face Recognition is one of the prominent problems in the computer vision domain. Witnessing advances in deep learning, significant work has been observed in face recognition, which touched upon various parts of the recognition framework like Convolutional Neural Network (CNN), Layers, Loss functions, etc. Various loss functions such as Cross-Entropy, Angular-Softmax and ArcFace have been introduced to learn the weights of network for face recognition. However, these loss functions are not able to priorities the hard samples as compared to easy samples. Moreover, their learning process is biased due to a number of easy examples compared to hard examples. In this paper, we address this issue by considering hard examples with more priority. In order to do so, We propose a Hard-Mining loss by by increasing the loss for harder examples and decreasing the loss for easy examples. The proposed concept is generic and can be used with any existing loss function. We test the Hard-Mining loss with different losses such as Cross-Entropy, Angular-Softmax and ArcFace. The proposed Hard-Mining loss is tested over widely used the Labeled Faces in the Wild (LFW) and YouTube Faces (YTF) datasets while training is performed over CASIA-WebFace and MS-Celeb-1M datasets. We use the residual network (i.e., ResNet18) for the experimental analysis. The experimental results suggest that the performance of existing loss functions is boosted when used in the framework of the proposed Hard-Mining loss.
A Performance Comparison of Loss Functions for Deep Face Recognition
Jan 01, 2019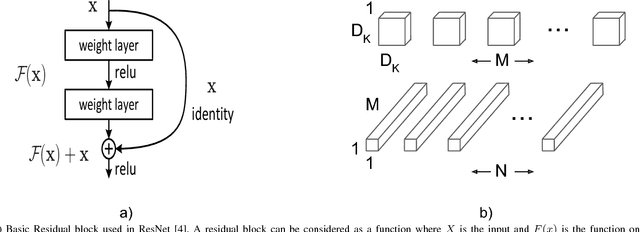
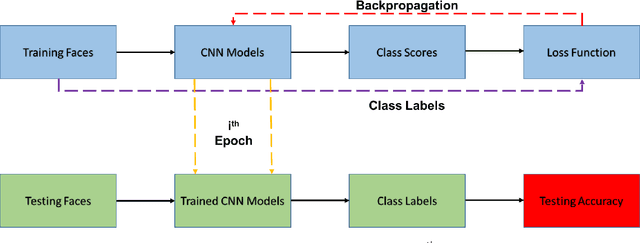
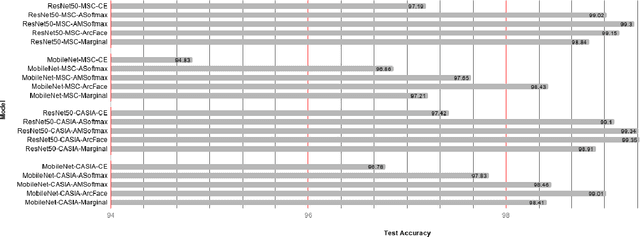

The emergence of biometric tools and its increased usage in day to day devices has brought simplicity in the authentication process for the users as compared to the passwords and pattern locks being used. The ease of use of biometric reduces the manual work and helps in faster and automatic authentication. Among different biometric traits, the face is one which can be captured without much cooperation of users. Moreover, face recognition is one of the most widely publicized feature in the devices today and hence represents an important problem that should be studied with the utmost priority. As per the recent trends, the Convolutional Neural Network (CNN) based approaches are highly successful in many tasks of Computer Vision including face recognition. The loss function is used on the top of CNN to judge the goodness of any network. The loss functions play an important role in CNN training. Basically, it generates a huge loss, if the network does not perform well using the current parameter setting. In this paper, we present a performance comparison of different loss functions such as Cross-Entropy, Angular Softmax, Additive-Margin Softmax, ArcFace and Marginal Loss for face recognition. The experiments are conducted with two CNN architectures namely, ResNet and MobileNet. Two widely used face datasets namely, CASIA-Webface and MS-Celeb-1M are used for the training and benchmark Labeled Faces in the Wild (LFW) face dataset is used for the testing. The training and test results are analyzed in this paper.