 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Scope of In-Context Learning for the Extraction of Medical Temporal Constraints
Mar 16, 2023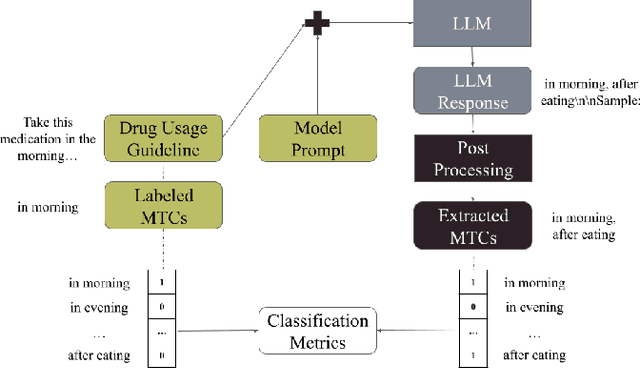
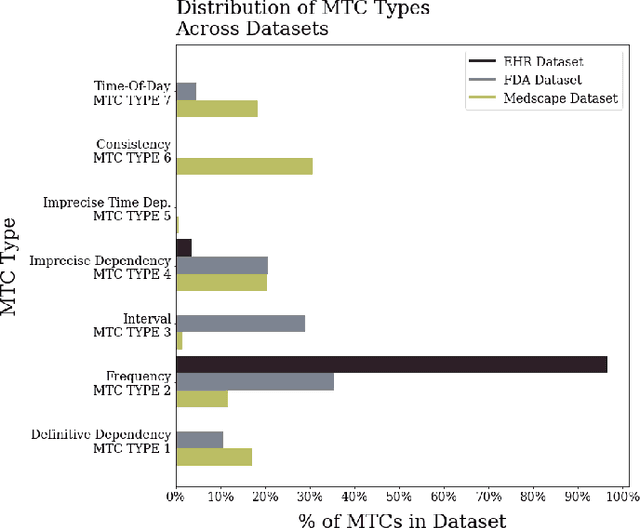

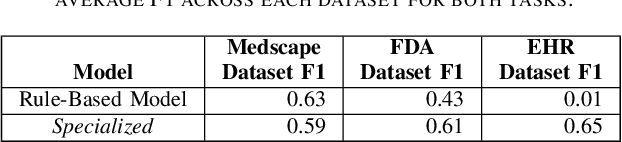
Medications often impose temporal constraints on everyday patient activity. Violations of such medical temporal constraints (MTCs) lead to a lack of treatment adherence, in addition to poor health outcomes and increased healthcare expenses. These MTCs are found in drug usage guidelines (DUGs) in both patient education materials and clinical texts. Computationally representing MTCs in DUGs will advance patient-centric healthcare applications by helping to define safe patient activity patterns. We define a novel taxonomy of MTCs found in DUGs and develop a novel context-free grammar (CFG) based model to computationally represent MTCs from unstructured DUGs. Additionally, we release three new datasets with a combined total of N = 836 DUGs labeled with normalized MTCs. We develop an in-context learning (ICL) solution for automatically extracting and normalizing MTCs found in DUGs, achieving an average F1 score of 0.62 across all datasets. Finally, we rigorously investigate ICL model performance against a baseline model, across datasets and MTC types, and through in-depth error analysis.
CitySpec with Shield: A Secure Intelligent Assistant for Requirement Formalization
Feb 19, 2023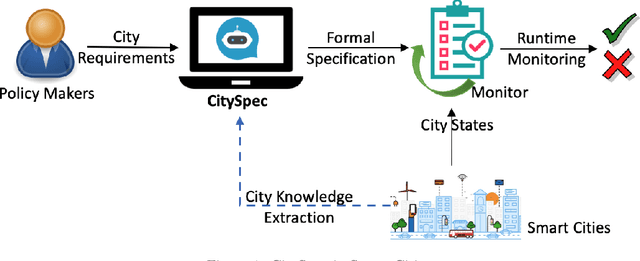

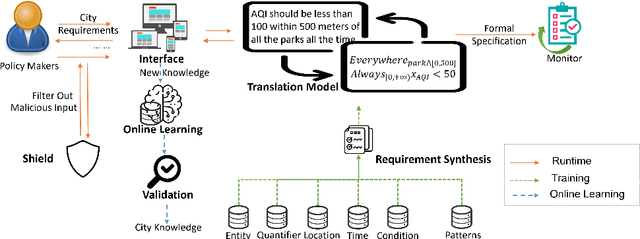
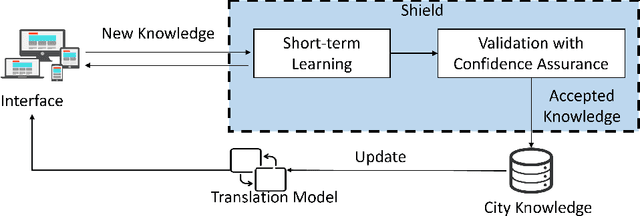
An increasing number of monitoring systems have been developed in smart cities to ensure that the real-time operations of a city satisfy safety and performance requirements. However, many existing city requirements are written in English with missing, inaccurate, or ambiguous information. There is a high demand for assisting city policymakers in converting human-specified requirements to machine-understandable formal specifications for monitoring systems. To tackle this limitation, we build CitySpec, the first intelligent assistant system for requirement specification in smart cities. To create CitySpec, we first collect over 1,500 real-world city requirements across different domains (e.g., transportation and energy) from over 100 cities and extract city-specific knowledge to generate a dataset of city vocabulary with 3,061 words. We also build a translation model and enhance it through requirement synthesis and develop a novel online learning framework with shielded validation. The evaluation results on real-world city requirements show that CitySpec increases the sentence-level accuracy of requirement specification from 59.02% to 86.64%, and has strong adaptability to a new city and a new domain (e.g., the F1 score for requirements in Seattle increases from 77.6% to 93.75% with online learning). After the enhancement from the shield function, CitySpec is now immune to most known textual adversarial inputs (e.g., the attack success rate of DeepWordBug after the shield function is reduced to 0% from 82.73%). We test the CitySpec with 18 participants from different domains. CitySpec shows its strong usability and adaptability to different domains, and also its robustness to malicious inputs.
Theme-driven Keyphrase Extraction from Social Media on Opioid Recovery
Jan 27, 2023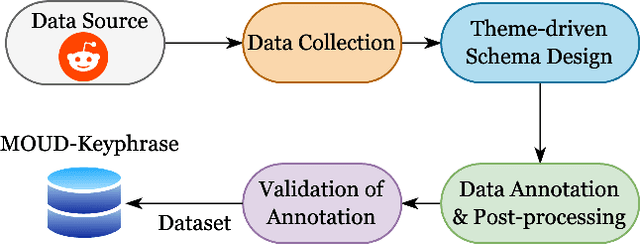
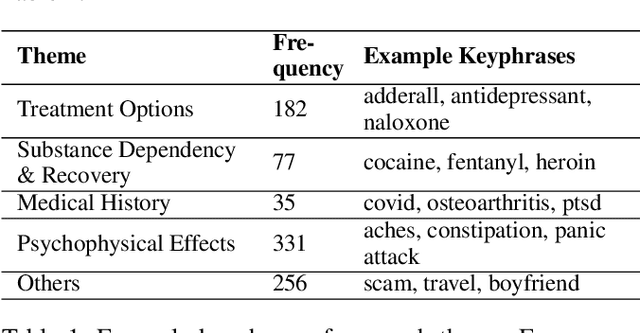

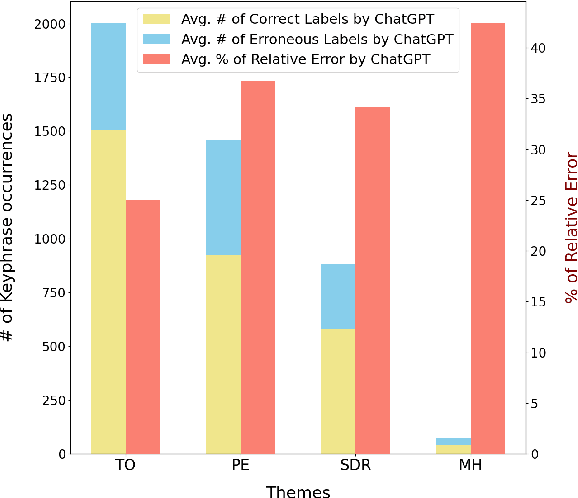
An emerging trend on social media platforms is their use as safe spaces for peer support. Particularly in healthcare, where many medical conditions contain harsh stigmas, social media has become a stigma-free way to engage in dialogues regarding symptoms, treatments, and personal experiences. Many existing works have employed NLP algorithms to facilitate quantitative analysis of health trends. Notably absent from existing works are keyphrase extraction (KE) models for social health posts-a task crucial to discovering emerging public health trends. This paper presents a novel, theme-driven KE dataset, SuboxoPhrase, and a qualitative annotation scheme with an overarching goal of extracting targeted clinically-relevant keyphrases. To the best of our knowledge, this is the first study to design a KE schema for social media healthcare texts. To demonstrate the value of this approach, this study analyzes Reddit posts regarding medications for opioid use disorder, a paramount health concern worldwide. Additionally, we benchmark ten off-the-shelf KE models on our new dataset, demonstrating the unique extraction challenges in modeling user-generated health texts. The proposed theme-driven KE approach lays the foundation of future work on efficient, large-scale analysis of social health texts, allowing researchers to surface useful public health trends, patterns, and knowledge gaps.
An Intelligent Assistant for Converting City Requirements to Formal Specification
Jun 14, 2022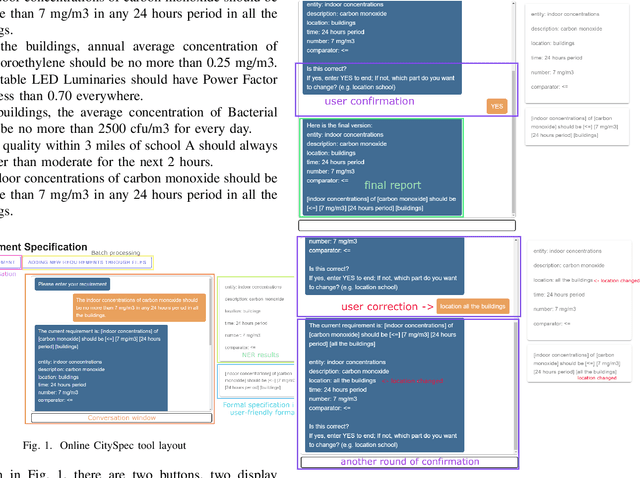

As more and more monitoring systems have been deployed to smart cities, there comes a higher demand for converting new human-specified requirements to machine-understandable formal specifications automatically. However, these human-specific requirements are often written in English and bring missing, inaccurate, or ambiguous information. In this paper, we present CitySpec, an intelligent assistant system for requirement specification in smart cities. CitySpec not only helps overcome the language differences brought by English requirements and formal specifications, but also offers solutions to those missing, inaccurate, or ambiguous information. The goal of this paper is to demonstrate how CitySpec works. Specifically, we present three demos: (1) interactive completion of requirements in CitySpec; (2) human-in-the-loop correction while CitySepc encounters exceptions; (3) online learning in CitySpec.
CitySpec: An Intelligent Assistant System for Requirement Specification in Smart Cities
Jun 07, 2022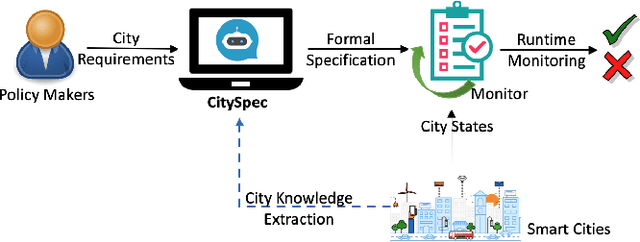
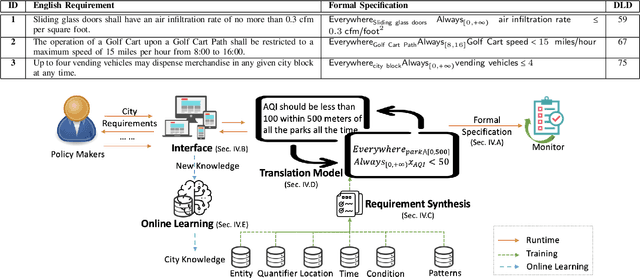
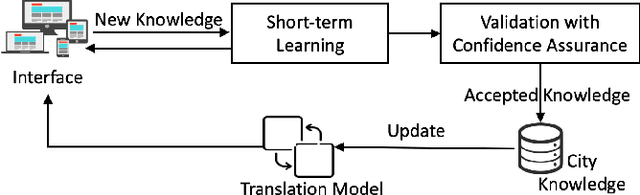
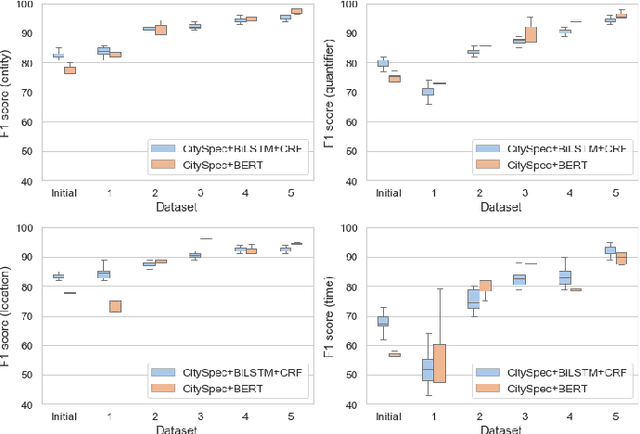
An increasing number of monitoring systems have been developed in smart cities to ensure that real-time operations of a city satisfy safety and performance requirements. However, many existing city requirements are written in English with missing, inaccurate, or ambiguous information. There is a high demand for assisting city policy makers in converting human-specified requirements to machine-understandable formal specifications for monitoring systems. To tackle this limitation, we build CitySpec, the first intelligent assistant system for requirement specification in smart cities. To create CitySpec, we first collect over 1,500 real-world city requirements across different domains from over 100 cities and extract city-specific knowledge to generate a dataset of city vocabulary with 3,061 words. We also build a translation model and enhance it through requirement synthesis and develop a novel online learning framework with validation under uncertainty. The evaluation results on real-world city requirements show that CitySpec increases the sentence-level accuracy of requirement specification from 59.02% to 86.64%, and has strong adaptability to a new city and a new domain (e.g., F1 score for requirements in Seattle increases from 77.6% to 93.75% with online learning).