 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Multimodal Cognitive Assistant for Emergency Medical Services
Mar 11, 2024Emergency Medical Services (EMS) responders often operate under time-sensitive conditions, facing cognitive overload and inherent risks, requiring essential skills in critical thinking and rapid decision-making. This paper presents CognitiveEMS, an end-to-end wearable cognitive assistant system that can act as a collaborative virtual partner engaging in the real-time acquisition and analysis of multimodal data from an emergency scene and interacting with EMS responders through Augmented Reality (AR) smart glasses. CognitiveEMS processes the continuous streams of data in real-time and leverages edge computing to provide assistance in EMS protocol selection and intervention recognition. We address key technical challenges in real-time cognitive assistance by introducing three novel components: (i) a Speech Recognition model that is fine-tuned for real-world medical emergency conversations using simulated EMS audio recordings, augmented with synthetic data generated by large language models (LLMs); (ii) an EMS Protocol Prediction model that combines state-of-the-art (SOTA) tiny language models with EMS domain knowledge using graph-based attention mechanisms; (iii) an EMS Action Recognition module which leverages multimodal audio and video data and protocol predictions to infer the intervention/treatment actions taken by the responders at the incident scene. Our results show that for speech recognition we achieve superior performance compared to SOTA (WER of 0.290 vs. 0.618) on conversational data. Our protocol prediction component also significantly outperforms SOTA (top-3 accuracy of 0.800 vs. 0.200) and the action recognition achieves an accuracy of 0.727, while maintaining an end-to-end latency of 3.78s for protocol prediction on the edge and 0.31s on the server.
Camera-Independent Single Image Depth Estimation from Defocus Blur
Nov 21, 2023Monocular depth estimation is an important step in many downstream tasks in machine vision. We address the topic of estimating monocular depth from defocus blur which can yield more accurate results than the semantic based depth estimation methods. The existing monocular depth from defocus techniques are sensitive to the particular camera that the images are taken from. We show how several camera-related parameters affect the defocus blur using optical physics equations and how they make the defocus blur depend on these parameters. The simple correction procedure we propose can alleviate this problem which does not require any retraining of the original model. We created a synthetic dataset which can be used to test the camera independent performance of depth from defocus blur models. We evaluate our model on both synthetic and real datasets (DDFF12 and NYU depth V2) obtained with different cameras and show that our methods are significantly more robust to the changes of cameras. Code: https://github.com/sleekEagle/defocus_camind.git
DKEC: Domain Knowledge Enhanced Multi-Label Classification for Electronic Health Records
Oct 10, 2023Multi-label text classification (MLTC) tasks in the medical domain often face long-tail label distribution, where rare classes have fewer training samples than frequent classes. Although previous works have explored different model architectures and hierarchical label structures to find important features, most of them neglect to incorporate the domain knowledge from medical guidelines. In this paper, we present DKEC, Domain Knowledge Enhanced Classifier for medical diagnosis prediction with two innovations: (1) a label-wise attention mechanism that incorporates a heterogeneous graph and domain ontologies to capture the semantic relationships between medical entities, (2) a simple yet effective group-wise training method based on similarity of labels to increase samples of rare classes. We evaluate DKEC on two real-world medical datasets: the RAA dataset, a collection of 4,417 patient care reports from emergency medical services (EMS) incidents, and a subset of 53,898 reports from the MIMIC-III dataset. Experimental results show that our method outperforms the state-of-the-art, particularly for the few-shot (tail) classes. More importantly, we study the applicability of DKEC to different language models and show that DKEC can help the smaller language models achieve comparable performance to large language models.
CitySpec with Shield: A Secure Intelligent Assistant for Requirement Formalization
Feb 19, 2023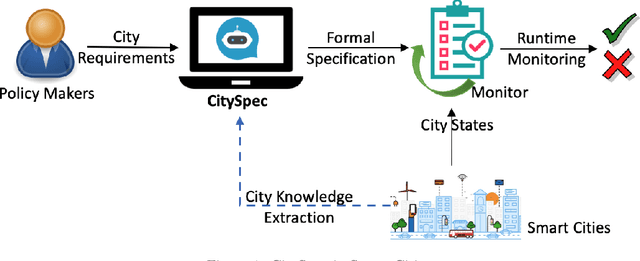

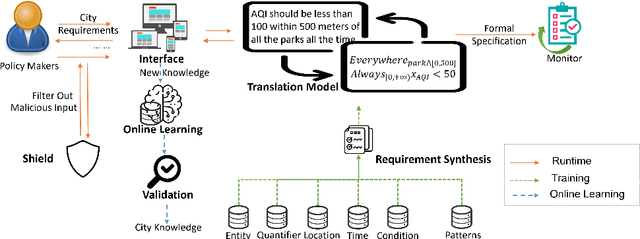
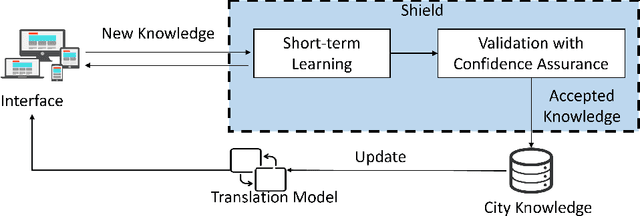
An increasing number of monitoring systems have been developed in smart cities to ensure that the real-time operations of a city satisfy safety and performance requirements. However, many existing city requirements are written in English with missing, inaccurate, or ambiguous information. There is a high demand for assisting city policymakers in converting human-specified requirements to machine-understandable formal specifications for monitoring systems. To tackle this limitation, we build CitySpec, the first intelligent assistant system for requirement specification in smart cities. To create CitySpec, we first collect over 1,500 real-world city requirements across different domains (e.g., transportation and energy) from over 100 cities and extract city-specific knowledge to generate a dataset of city vocabulary with 3,061 words. We also build a translation model and enhance it through requirement synthesis and develop a novel online learning framework with shielded validation. The evaluation results on real-world city requirements show that CitySpec increases the sentence-level accuracy of requirement specification from 59.02% to 86.64%, and has strong adaptability to a new city and a new domain (e.g., the F1 score for requirements in Seattle increases from 77.6% to 93.75% with online learning). After the enhancement from the shield function, CitySpec is now immune to most known textual adversarial inputs (e.g., the attack success rate of DeepWordBug after the shield function is reduced to 0% from 82.73%). We test the CitySpec with 18 participants from different domains. CitySpec shows its strong usability and adaptability to different domains, and also its robustness to malicious inputs.
CitySpec: An Intelligent Assistant System for Requirement Specification in Smart Cities
Jun 07, 2022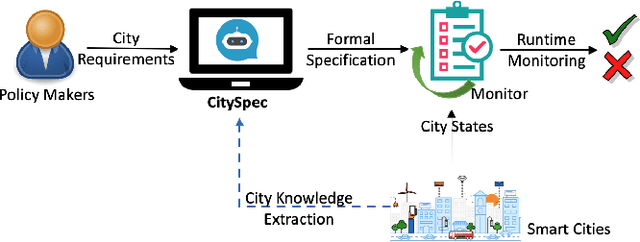
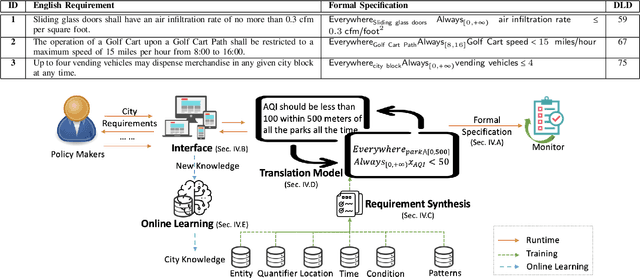
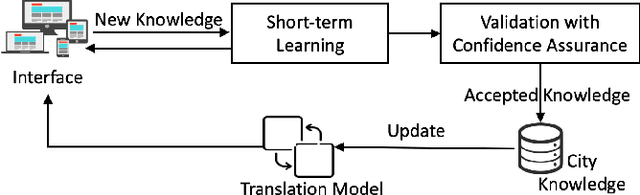
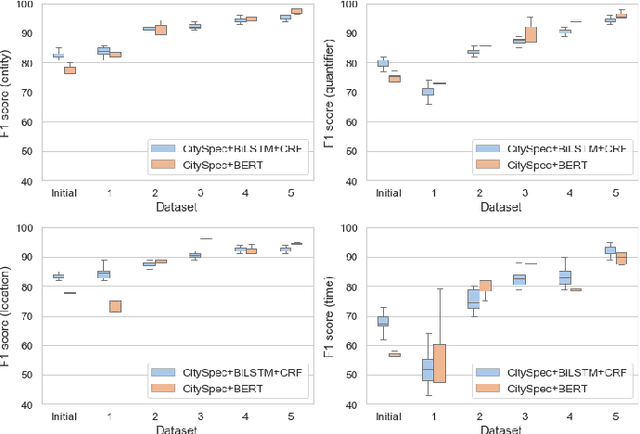
An increasing number of monitoring systems have been developed in smart cities to ensure that real-time operations of a city satisfy safety and performance requirements. However, many existing city requirements are written in English with missing, inaccurate, or ambiguous information. There is a high demand for assisting city policy makers in converting human-specified requirements to machine-understandable formal specifications for monitoring systems. To tackle this limitation, we build CitySpec, the first intelligent assistant system for requirement specification in smart cities. To create CitySpec, we first collect over 1,500 real-world city requirements across different domains from over 100 cities and extract city-specific knowledge to generate a dataset of city vocabulary with 3,061 words. We also build a translation model and enhance it through requirement synthesis and develop a novel online learning framework with validation under uncertainty. The evaluation results on real-world city requirements show that CitySpec increases the sentence-level accuracy of requirement specification from 59.02% to 86.64%, and has strong adaptability to a new city and a new domain (e.g., F1 score for requirements in Seattle increases from 77.6% to 93.75% with online learning).