 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel DNN Training Framework via Data Sampling and Multi-Task Optimization
Paper and Code
Jul 02, 2020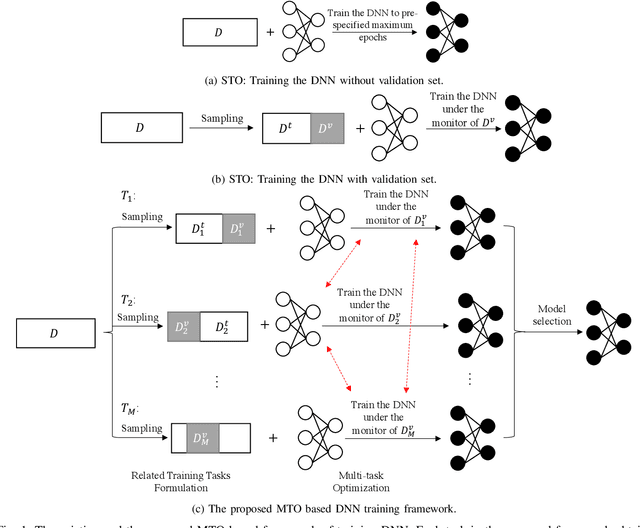
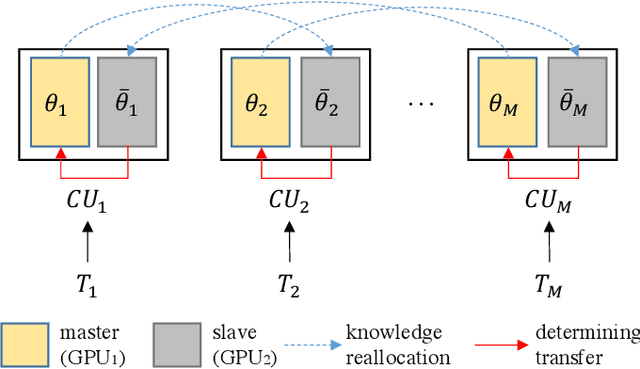
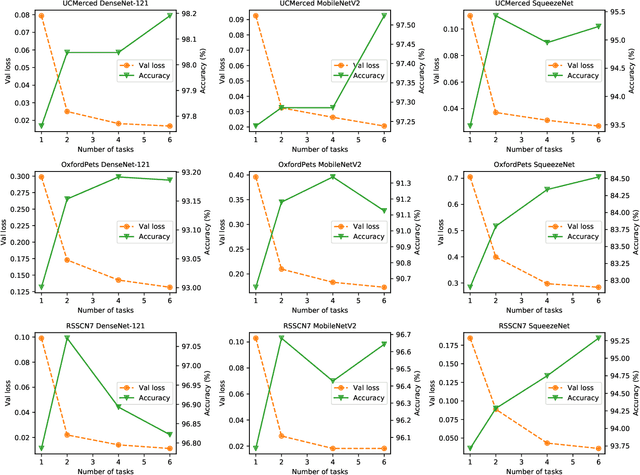
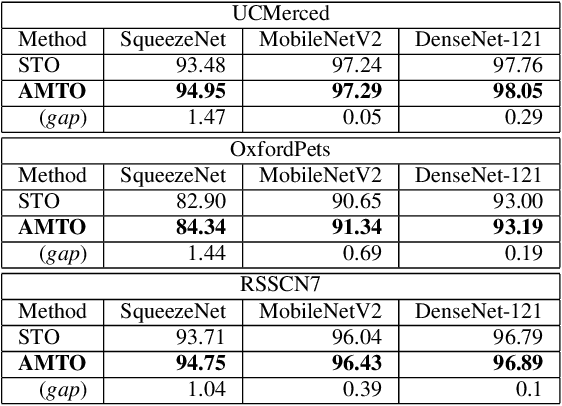
Conventional DNN training paradigms typically rely on one training set and one validation set, obtained by partitioning an annotated dataset used for training, namely gross training set, in a certain way. The training set is used for training the model while the validation set is used to estimate the generalization performance of the trained model as the training proceeds to avoid over-fitting. There exist two major issues in this paradigm. Firstly, the validation set may hardly guarantee an unbiased estimate of generalization performance due to potential mismatching with test data. Secondly, training a DNN corresponds to solve a complex optimization problem, which is prone to getting trapped into inferior local optima and thus leads to undesired training results. To address these issues, we propose a novel DNN training framework. It generates multiple pairs of training and validation sets from the gross training set via random splitting, trains a DNN model of a pre-specified structure on each pair while making the useful knowledge (e.g., promising network parameters) obtained from one model training process to be transferred to other model training processes via multi-task optimization, and outputs the best, among all trained models, which has the overall best performance across the validation sets from all pairs. The knowledge transfer mechanism featured in this new framework can not only enhance training effectiveness by helping the model training process to escape from local optima but also improve on generalization performance via implicit regularization imposed on one model training process from other model training processes. We implement the proposed framework, parallelize the implementation on a GPU cluster, and apply it to train several widely used DNN models. Experimental results demonstrate the superiority of the proposed framework over the conventional training paradigm.