 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Curriculum Learning for Vision-Language Tasks: A Study on Small-Scale Multimodal Training
Oct 20, 2024For specialized domains, there is often not a wealth of data with which to train large machine learning models. In such limited data / compute settings, various methods exist aiming to $\textit{do more with less}$, such as finetuning from a pretrained model, modulating difficulty levels as data are presented to a model (curriculum learning), and considering the role of model type / size. Approaches to efficient $\textit{machine}$ learning also take inspiration from $\textit{human}$ learning by considering use cases where machine learning systems have access to approximately the same number of words experienced by a 13 year old child (100M words). We investigate the role of 3 primary variables in a limited data regime as part of the multimodal track of the BabyLM challenge. We contrast: (i) curriculum learning, (ii), pretraining (with text-only data), (iii) model type. We modulate these variables and assess them on two types of tasks: (a) multimodal (text+image), and (b) unimodal (text-only) tasks. We find that curriculum learning benefits multimodal evaluations over non-curriclum learning models, particularly when combining text-only pretraining. On text-only tasks, curriculum learning appears to help models with smaller trainable parameter counts. We suggest possible reasons based on architectural differences and training designs as to why one might observe such results.
Relational Extraction on Wikipedia Tables using Convolutional and Memory Networks
Jul 11, 2023

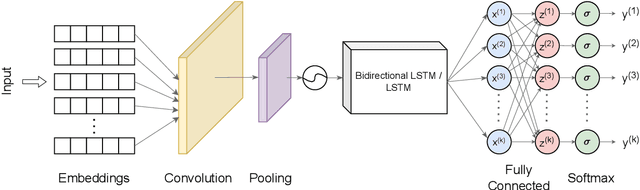

Relation extraction (RE) is the task of extracting relations between entities in text. Most RE methods extract relations from free-form running text and leave out other rich data sources, such as tables. We explore RE from the perspective of applying neural methods on tabularly organized data. We introduce a new model consisting of Convolutional Neural Network (CNN) and Bidirectional-Long Short Term Memory (BiLSTM) network to encode entities and learn dependencies among them, respectively. We evaluate our model on a large and recent dataset and compare results with previous neural methods. Experimental results show that our model consistently outperforms the previous model for the task of relation extraction on tabular data. We perform comprehensive error analyses and ablation study to show the contribution of various components of our model. Finally, we discuss the usefulness and trade-offs of our approach, and provide suggestions for fostering further research.
Influence of various text embeddings on clustering performance in NLP
May 04, 2023



With the advent of e-commerce platforms, reviews are crucial for customers to assess the credibility of a product. The star ratings do not always match the review text written by the customer. For example, a three star rating (out of five) may be incongruous with the review text, which may be more suitable for a five star review. A clustering approach can be used to relabel the correct star ratings by grouping the text reviews into individual groups. In this work, we explore the task of choosing different text embeddings to represent these reviews and also explore the impact the embedding choice has on the performance of various classes of clustering algorithms. We use contextual (BERT) and non-contextual (Word2Vec) text embeddings to represent the text and measure their impact of three classes on clustering algorithms - partitioning based (KMeans), single linkage agglomerative hierarchical, and density based (DBSCAN and HDBSCAN), each with various experimental settings. We use the silhouette score, adjusted rand index score, and cluster purity score metrics to evaluate the performance of the algorithms and discuss the impact of different embeddings on the clustering performance. Our results indicate that the type of embedding chosen drastically affects the performance of the algorithm, the performance varies greatly across different types of clustering algorithms, no embedding type is better than the other, and DBSCAN outperforms KMeans and single linkage agglomerative clustering but also labels more data points as outliers. We provide a thorough comparison of the performances of different algorithms and provide numerous ideas to foster further research in the domain of text clustering.
Analysis of Evolutionary Program Synthesis for Card Games
Jan 08, 2021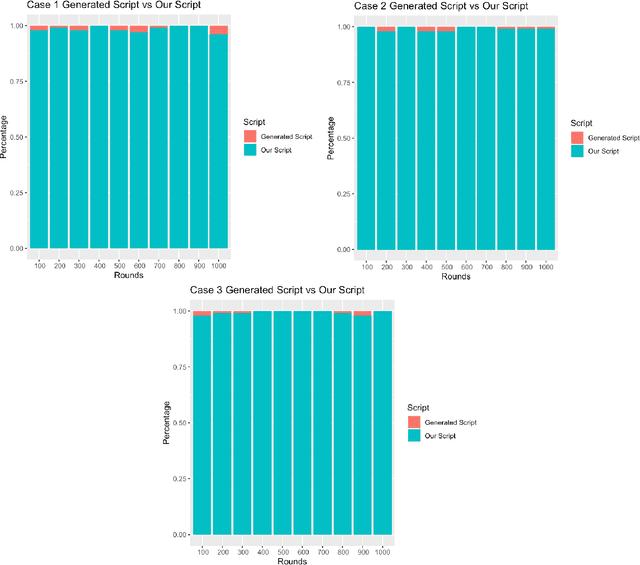
In this report, we inspect the application of an evolutionary approach to the game of Rack'O, which is a card game revolving around the notion of decision making. We first apply the evolutionary technique for obtaining a set of rules over many generations and then compare them with a script written by a human player. A high-level domain-specific language is used that deter-mines which the sets of rules are synthesized. We report the results by providing a comprehensive analysis of the set of rules and their implications.
Homonym Identification using BERT -- Using a Clustering Approach
Jan 07, 2021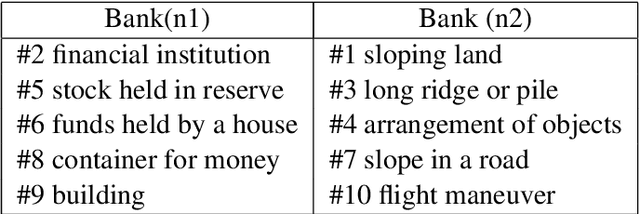
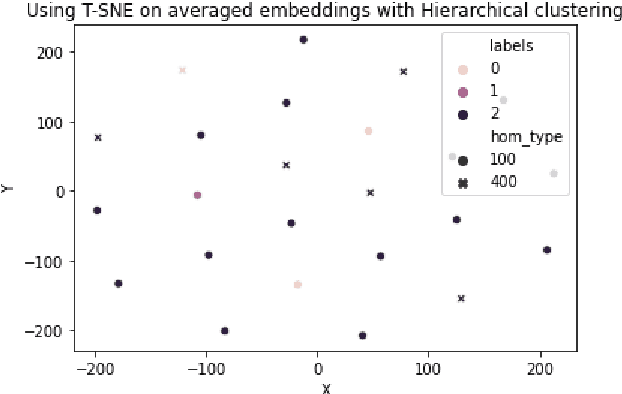


Homonym identification is important for WSD that require coarse-grained partitions of senses. The goal of this project is to determine whether contextual information is sufficient for identifying a homonymous word. To capture the context, BERT embeddings are used as opposed to Word2Vec, which conflates senses into one vector. SemCor is leveraged to retrieve the embeddings. Various clustering algorithms are applied to the embeddings. Finally, the embeddings are visualized in a lower-dimensional space to understand the feasibility of the clustering process.
Comparing Classification Models on Kepler Data
Jan 07, 2021


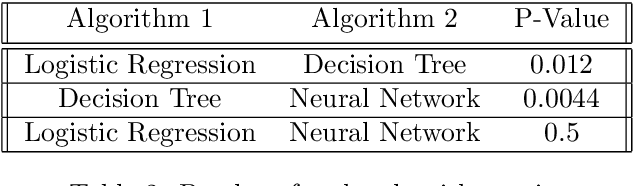
Even though the original Kepler mission ended due to mechanical failures, the Kepler satellite continues to collect data. Using classification models, we can understand the features exoplanets possess and then use those features to investigate further for any more information on the candidate planet. Based on the classification model, the idea is to find out the probability of the planet under observation being a candidate for an exoplanet or a false positive. If the model predicts that the observation is a candidate for being an exoplanet, then the further investigation can be conducted. From the model, we can narrow down the features that might explain the difference between a candidate and a false-positive which ultimately helps us to increase the efficiency of any model and fine-tune the model and ultimately the process of searching for any future exoplanets. The model comparison is supported by McNemar's test for checking significance.