Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomonym Identification using BERT -- Using a Clustering Approach
Paper and Code
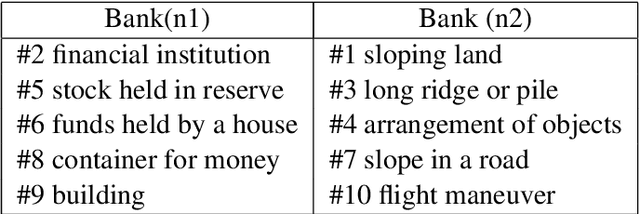
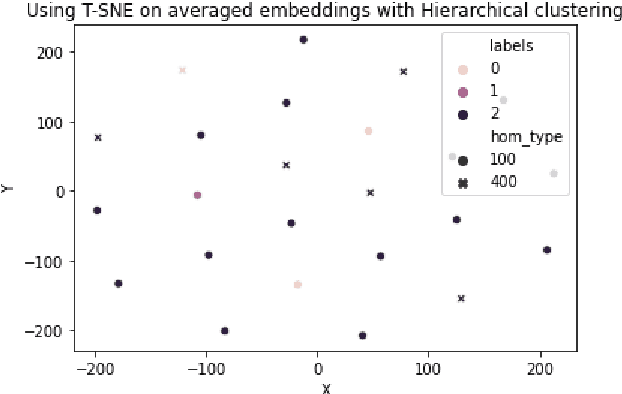


Homonym identification is important for WSD that require coarse-grained partitions of senses. The goal of this project is to determine whether contextual information is sufficient for identifying a homonymous word. To capture the context, BERT embeddings are used as opposed to Word2Vec, which conflates senses into one vector. SemCor is leveraged to retrieve the embeddings. Various clustering algorithms are applied to the embeddings. Finally, the embeddings are visualized in a lower-dimensional space to understand the feasibility of the clustering process.
View paper on