 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Space Partitioning for Nearest Neighbor Search
Paper and Code
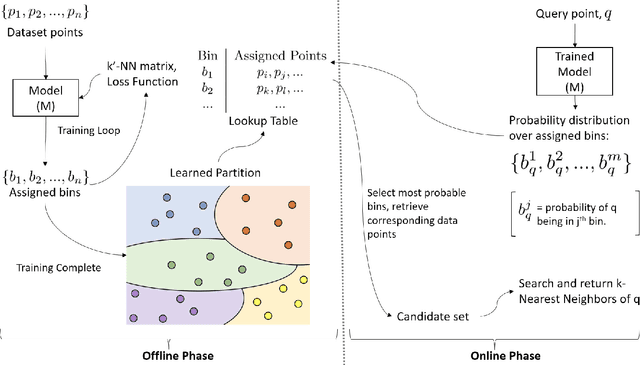


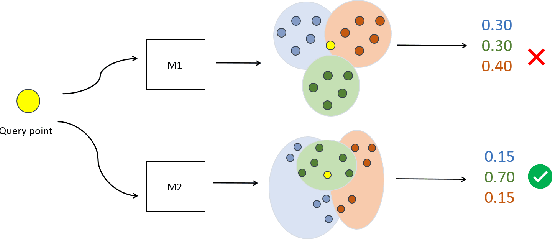
Approximate Nearest Neighbor Search (ANNS) in high dimensional spaces is crucial for many real-life applications (e.g., e-commerce, web, multimedia, etc.) dealing with an abundance of data. In this paper, we propose an end-to-end learning framework that couples the partitioning (one key step of ANNS) and learning-to-search steps using a custom loss function. A key advantage of our proposed solution is that it does not require any expensive pre-processing of the dataset, which is one of the key limitations of the state-of-the-art approach. We achieve the above edge by formulating a multi-objective custom loss function that does not need ground truth labels to quantify the quality of a given partition of the data space, making it entirely unsupervised. We also propose an ensembling technique by adding varying input weights to the loss function to train an ensemble of models to enhance the search quality. On several standard benchmarks for ANNS, we show that our method beats the state-of-the-art space partitioning method and the ubiquitous K-means clustering method while using fewer parameters and shorter offline training times. Without loss of generality, our unsupervised partitioning approach is shown as a promising alternative to many widely used clustering methods like K-means clustering and DBSCAN.