 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's the Opposite of a Face? Finding Shared Decodable Concepts and their Negations in the Brain
May 27, 2024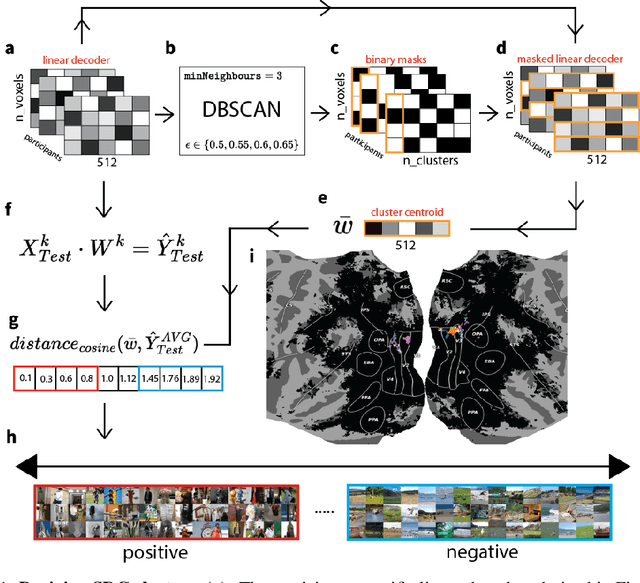
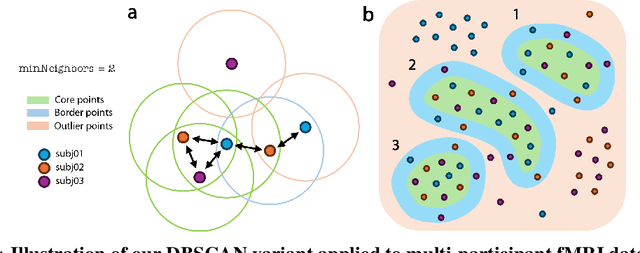
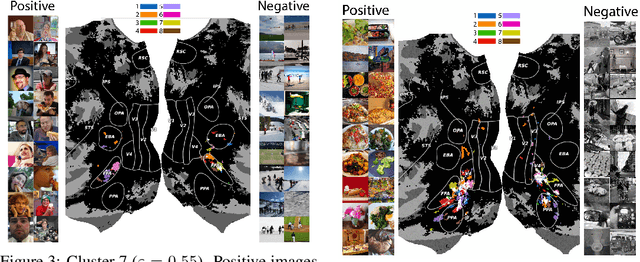

Prior work has offered evidence for functional localization in the brain; different anatomical regions preferentially activate for certain types of visual input. For example, the fusiform face area preferentially activates for visual stimuli that include a face. However, the spectrum of visual semantics is extensive, and only a few semantically-tuned patches of cortex have so far been identified in the human brain. Using a multimodal (natural language and image) neural network architecture (CLIP) we train a highly accurate contrastive model that maps brain responses during naturalistic image viewing to CLIP embeddings. We then use a novel adaptation of the DBSCAN clustering algorithm to cluster the parameters of these participant-specific contrastive models. This reveals what we call Shared Decodable Concepts (SDCs): clusters in CLIP space that are decodable from common sets of voxels across multiple participants. Examining the images most and least associated with each SDC cluster gives us additional insight into the semantic properties of each SDC. We note SDCs for previously reported visual features (e.g. orientation tuning in early visual cortex) as well as visual semantic concepts such as faces, places and bodies. In cases where our method finds multiple clusters for a visuo-semantic concept, the least associated images allow us to dissociate between confounding factors. For example, we discovered two clusters of food images, one driven by color, the other by shape. We also uncover previously unreported areas such as regions of extrastriate body area (EBA) tuned for legs/hands and sensitivity to numerosity in right intraparietal sulcus, and more. Thus, our contrastive-learning methodology better characterizes new and existing visuo-semantic representations in the brain by leveraging multimodal neural network representations and a novel adaptation of clustering algorithms.
Identifying Shared Decodable Concepts in the Human Brain Using Image-Language Foundation Models
Jun 06, 2023



We introduce a method that takes advantage of high-quality pretrained multimodal representations to explore fine-grained semantic networks in the human brain. Previous studies have documented evidence of functional localization in the brain, with different anatomical regions preferentially activating for different types of sensory input. Many such localized structures are known, including the fusiform face area and parahippocampal place area. This raises the question of whether additional brain regions (or conjunctions of brain regions) are also specialized for other important semantic concepts. To identify such brain regions, we developed a data-driven approach to uncover visual concepts that are decodable from a massive functional magnetic resonance imaging (fMRI) dataset. Our analysis is broadly split into three sections. First, a fully connected neural network is trained to map brain responses to the outputs of an image-language foundation model, CLIP (Radford et al., 2021). Subsequently, a contrastive-learning dimensionality reduction method reveals the brain-decodable components of CLIP space. In the final section of our analysis, we localize shared decodable concepts in the brain using a voxel-masking optimization method to produce a shared decodable concept (SDC) space. The accuracy of our procedure is validated by comparing it to previous localization experiments that identify regions for faces, bodies, and places. In addition to these concepts, whose corresponding brain regions were already known, we localize novel concept representations which are shared across participants to other areas of the human brain. We also demonstrate how this method can be used to inspect fine-grained semantic networks for individual participants. We envisage that this extensible method can also be adapted to explore other questions at the intersection of AI and neuroscience.
Biomedical image analysis competitions: The state of current participation practice
Dec 16, 2022The number of international benchmarking competitions is steadily increasing in various fields of machine learning (ML) research and practice. So far, however, little is known about the common practice as well as bottlenecks faced by the community in tackling the research questions posed. To shed light on the status quo of algorithm development in the specific field of biomedical imaging analysis, we designed an international survey that was issued to all participants of challenges conducted in conjunction with the IEEE ISBI 2021 and MICCAI 2021 conferences (80 competitions in total). The survey covered participants' expertise and working environments, their chosen strategies, as well as algorithm characteristics. A median of 72% challenge participants took part in the survey. According to our results, knowledge exchange was the primary incentive (70%) for participation, while the reception of prize money played only a minor role (16%). While a median of 80 working hours was spent on method development, a large portion of participants stated that they did not have enough time for method development (32%). 25% perceived the infrastructure to be a bottleneck. Overall, 94% of all solutions were deep learning-based. Of these, 84% were based on standard architectures. 43% of the respondents reported that the data samples (e.g., images) were too large to be processed at once. This was most commonly addressed by patch-based training (69%), downsampling (37%), and solving 3D analysis tasks as a series of 2D tasks. K-fold cross-validation on the training set was performed by only 37% of the participants and only 50% of the participants performed ensembling based on multiple identical models (61%) or heterogeneous models (39%). 48% of the respondents applied postprocessing steps.
Improving the Accuracy and Robustness of CNNs Using a Deep CCA Neural Data Regularizer
Sep 06, 2022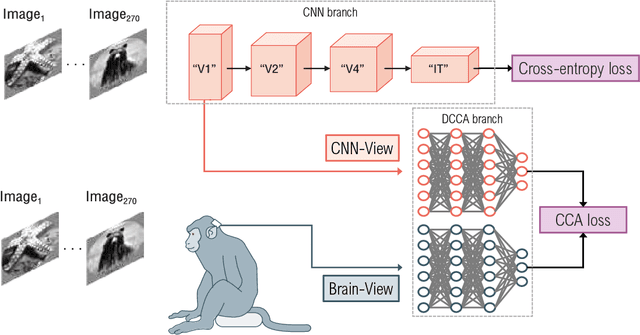
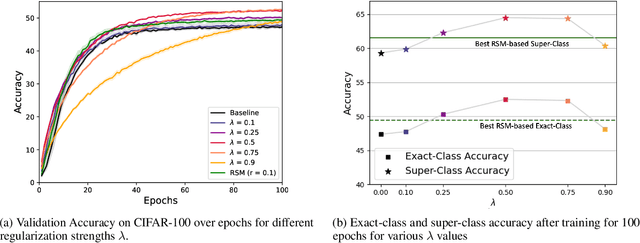
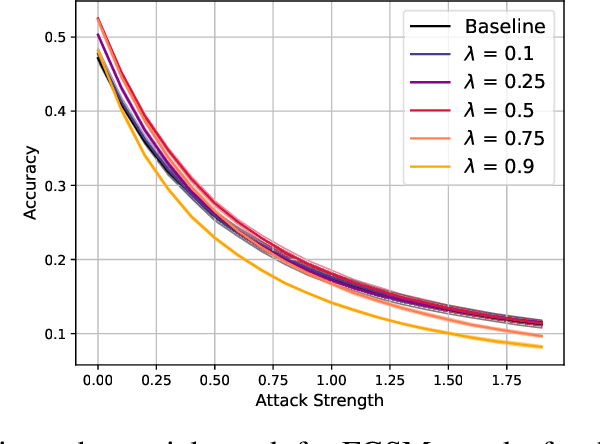
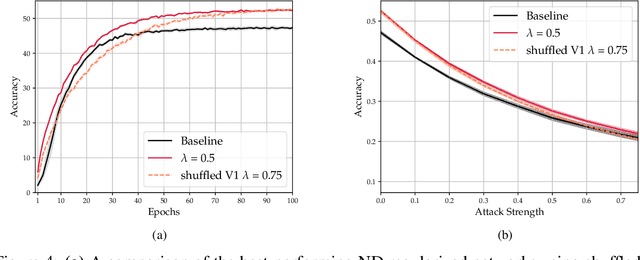
As convolutional neural networks (CNNs) become more accurate at object recognition, their representations become more similar to the primate visual system. This finding has inspired us and other researchers to ask if the implication also runs the other way: If CNN representations become more brain-like, does the network become more accurate? Previous attempts to address this question showed very modest gains in accuracy, owing in part to limitations of the regularization method. To overcome these limitations, we developed a new neural data regularizer for CNNs that uses Deep Canonical Correlation Analysis (DCCA) to optimize the resemblance of the CNN's image representations to that of the monkey visual cortex. Using this new neural data regularizer, we see much larger performance gains in both classification accuracy and within-super-class accuracy, as compared to the previous state-of-the-art neural data regularizers. These networks are also more robust to adversarial attacks than their unregularized counterparts. Together, these results confirm that neural data regularization can push CNN performance higher, and introduces a new method that obtains a larger performance boost.