 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Accuracy and Robustness of CNNs Using a Deep CCA Neural Data Regularizer
Sep 06, 2022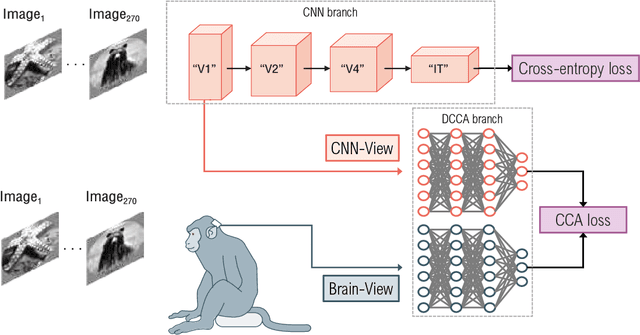
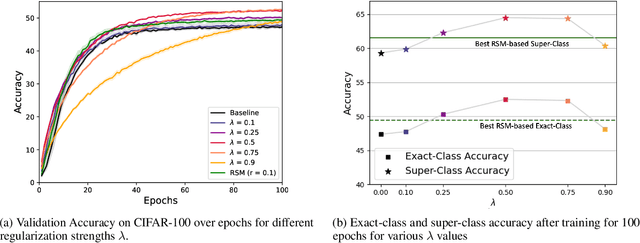
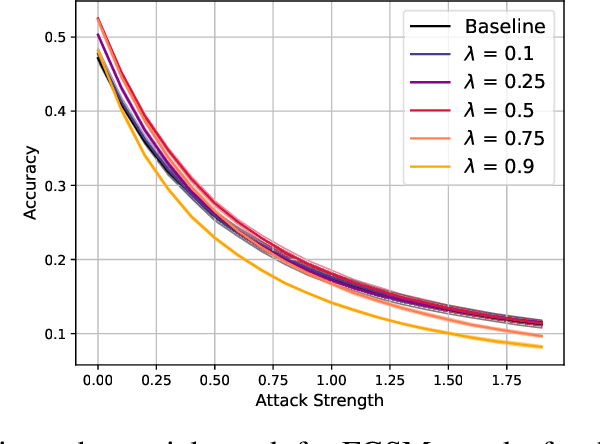
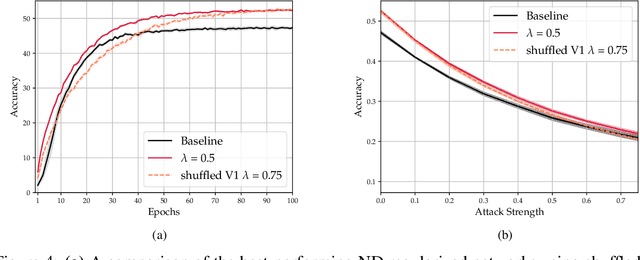
As convolutional neural networks (CNNs) become more accurate at object recognition, their representations become more similar to the primate visual system. This finding has inspired us and other researchers to ask if the implication also runs the other way: If CNN representations become more brain-like, does the network become more accurate? Previous attempts to address this question showed very modest gains in accuracy, owing in part to limitations of the regularization method. To overcome these limitations, we developed a new neural data regularizer for CNNs that uses Deep Canonical Correlation Analysis (DCCA) to optimize the resemblance of the CNN's image representations to that of the monkey visual cortex. Using this new neural data regularizer, we see much larger performance gains in both classification accuracy and within-super-class accuracy, as compared to the previous state-of-the-art neural data regularizers. These networks are also more robust to adversarial attacks than their unregularized counterparts. Together, these results confirm that neural data regularization can push CNN performance higher, and introduces a new method that obtains a larger performance boost.
Different Spectral Representations in Optimized Artificial Neural Networks and Brains
Aug 22, 2022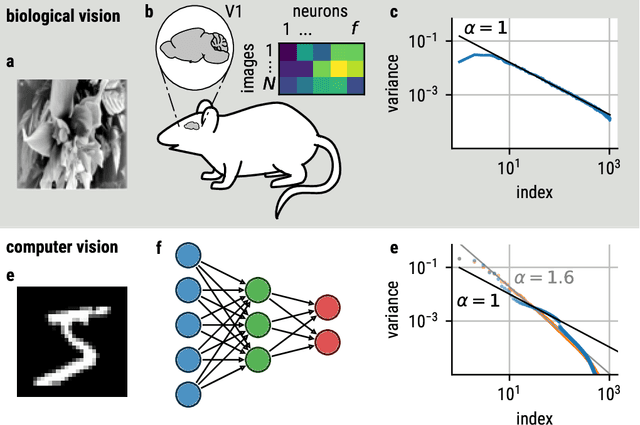
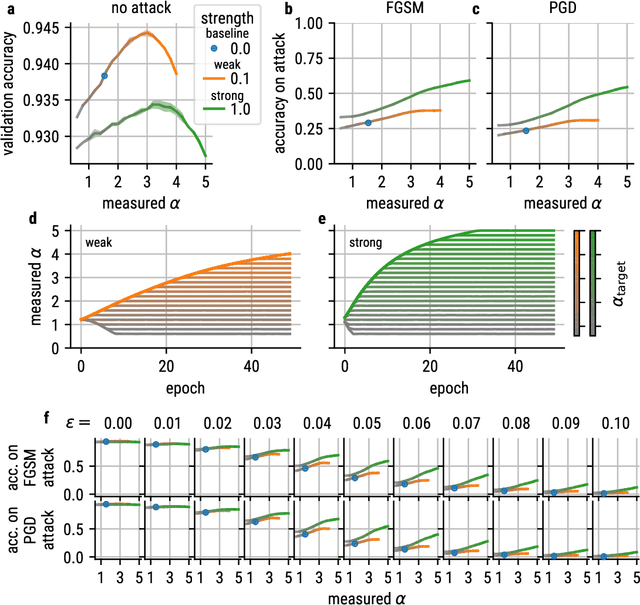

Recent studies suggest that artificial neural networks (ANNs) that match the spectral properties of the mammalian visual cortex -- namely, the $\sim 1/n$ eigenspectrum of the covariance matrix of neural activities -- achieve higher object recognition performance and robustness to adversarial attacks than those that do not. To our knowledge, however, no previous work systematically explored how modifying the ANN's spectral properties affects performance. To fill this gap, we performed a systematic search over spectral regularizers, forcing the ANN's eigenspectrum to follow $1/n^\alpha$ power laws with different exponents $\alpha$. We found that larger powers (around 2--3) lead to better validation accuracy and more robustness to adversarial attacks on dense networks. This surprising finding applied to both shallow and deep networks and it overturns the notion that the brain-like spectrum (corresponding to $\alpha \sim 1$) always optimizes ANN performance and/or robustness. For convolutional networks, the best $\alpha$ values depend on the task complexity and evaluation metric: lower $\alpha$ values optimized validation accuracy and robustness to adversarial attack for networks performing a simple object recognition task (categorizing MNIST images of handwritten digits); for a more complex task (categorizing CIFAR-10 natural images), we found that lower $\alpha$ values optimized validation accuracy whereas higher $\alpha$ values optimized adversarial robustness. These results have two main implications. First, they cast doubt on the notion that brain-like spectral properties ($\alpha \sim 1$) \emph{always} optimize ANN performance. Second, they demonstrate the potential for fine-tuned spectral regularizers to optimize a chosen design metric, i.e., accuracy and/or robustness.
Spiking Machine Intelligence: What we can learn from biology and how spiking Neural Networks can help to improve Machine Learning
Apr 28, 2020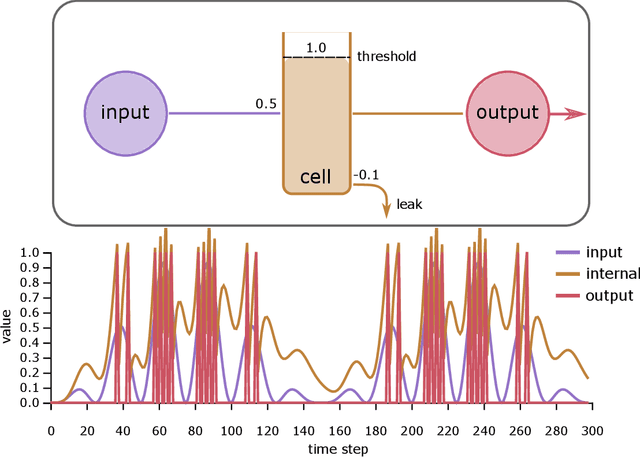
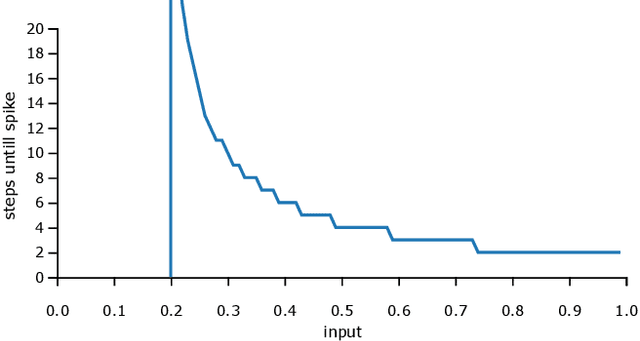
Up to now, modern Machine Learning is based on fitting high dimensional functions to enormous data sets, taking advantage of huge hardware resources. We show that biologically inspired neuron models such as the Integrate-and-Fire (LIF) neurons provide novel and efficient ways of information encoding. They can be integrated in Machine Learning models, and are a potential target to improve Machine Learning performance. Thus, we systematically analyze the LIF neuron. We start by deriving simple integration equations to which even a gradient can be assigned. Additionally, we prove that a Long-Short-Term-Memory unit can be tuned to show similar spiking properties. Additionally, LIF units are applied to an image classification task, trained with backpropagation. With this study we want to contribute to the current efforts to enhance Machine Intelligence by integrating principles from biology.
Sparsity through evolutionary pruning prevents neuronal networks from overfitting
Nov 07, 2019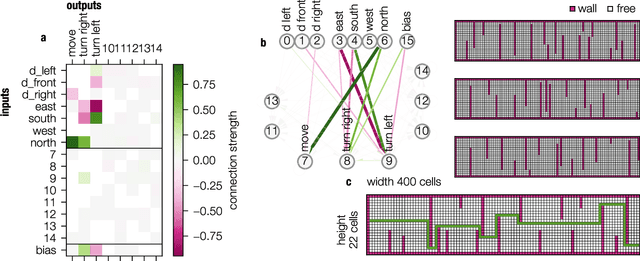
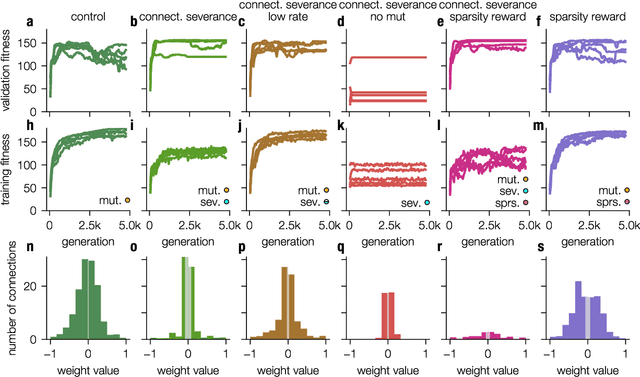
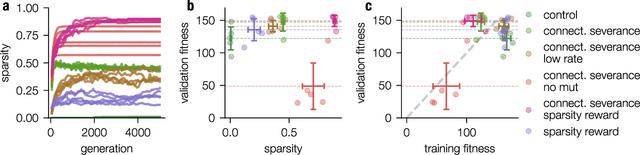
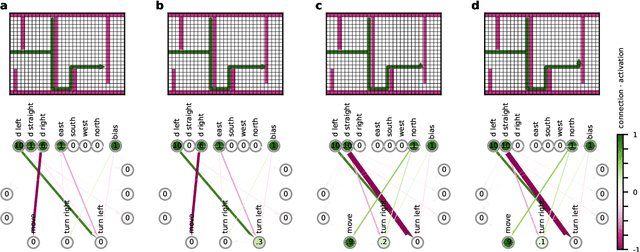
Modern Machine learning techniques take advantage of the exponentially rising calculation power in new generation processor units. Thus, the number of parameters which are trained to resolve complex tasks was highly increased over the last decades. However, still the networks fail - in contrast to our brain - to develop general intelligence in the sense of being able to solve several complex tasks with only one network architecture. This could be the case because the brain is not a randomly initialized neural network, which has to be trained by simply investing a lot of calculation power, but has from birth some fixed hierarchical structure. To make progress in decoding the structural basis of biological neural networks we here chose a bottom-up approach, where we evolutionarily trained small neural networks in performing a maze task. This simple maze task requires dynamical decision making with delayed rewards. We were able to show that during the evolutionary optimization random severance of connections lead to better generalization performance of the networks compared to fully connected networks. We conclude that sparsity is a central property of neural networks and should be considered for modern Machine learning approaches.