 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Preference Optimization via Maximum Marginal Likelihood Estimation
Oct 27, 2025Aligning Large Language Models (LLMs) with human preferences is crucial, but standard methods like Reinforcement Learning from Human Feedback (RLHF) are often complex and unstable. In this work, we propose a new, simpler approach that recasts alignment through the lens of Maximum Marginal Likelihood (MML) estimation. Our new MML based Preference Optimization (MMPO) maximizes the marginal log-likelihood of a preferred text output, using the preference pair as samples for approximation, and forgoes the need for both an explicit reward model and entropy maximization. We theoretically demonstrate that MMPO implicitly performs preference optimization, producing a weighted gradient that naturally up-weights chosen responses over rejected ones. Across models ranging from 135M to 8B parameters, we empirically show that MMPO: 1) is more stable with respect to the hyperparameter $\beta$ compared to alternative baselines, and 2) achieves competitive or superior preference alignment while better preserving the base model's general language capabilities. Through a series of ablation experiments, we show that this improved performance is indeed attributable to MMPO's implicit preference optimization within the gradient updates.
RIFF: Learning to Rephrase Inputs for Few-shot Fine-tuning of Language Models
Mar 04, 2024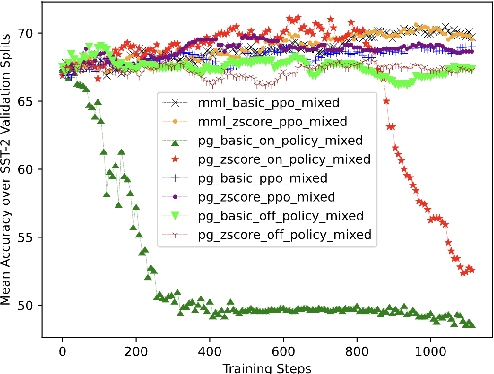
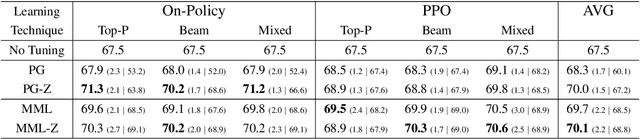

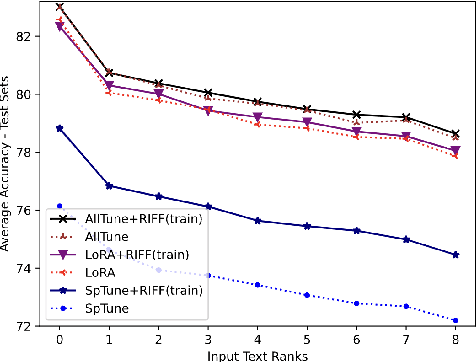
Pre-trained Language Models (PLMs) can be accurately fine-tuned for downstream text processing tasks. Recently, researchers have introduced several parameter-efficient fine-tuning methods that optimize input prompts or adjust a small number of model parameters (e.g LoRA). In this study, we explore the impact of altering the input text of the original task in conjunction with parameter-efficient fine-tuning methods. To most effectively rewrite the input text, we train a few-shot paraphrase model with a Maximum-Marginal Likelihood objective. Using six few-shot text classification datasets, we show that enriching data with paraphrases at train and test time enhances the performance beyond what can be achieved with parameter-efficient fine-tuning alone.
Weakly-Supervised Questions for Zero-Shot Relation Extraction
Jan 21, 2023Zero-Shot Relation Extraction (ZRE) is the task of Relation Extraction where the training and test sets have no shared relation types. This very challenging domain is a good test of a model's ability to generalize. Previous approaches to ZRE reframed relation extraction as Question Answering (QA), allowing for the use of pre-trained QA models. However, this method required manually creating gold question templates for each new relation. Here, we do away with these gold templates and instead learn a model that can generate questions for unseen relations. Our technique can successfully translate relation descriptions into relevant questions, which are then leveraged to generate the correct tail entity. On tail entity extraction, we outperform the previous state-of-the-art by more than 16 F1 points without using gold question templates. On the RE-QA dataset where no previous baseline for relation extraction exists, our proposed algorithm comes within 0.7 F1 points of a system that uses gold question templates. Our model also outperforms the state-of-the-art ZRE baselines on the FewRel and WikiZSL datasets, showing that QA models no longer need template questions to match the performance of models specifically tailored to the ZRE task. Our implementation is available at https://github.com/fyshelab/QA-ZRE.
Efficient Sequence Labeling with Actor-Critic Training
Sep 30, 2018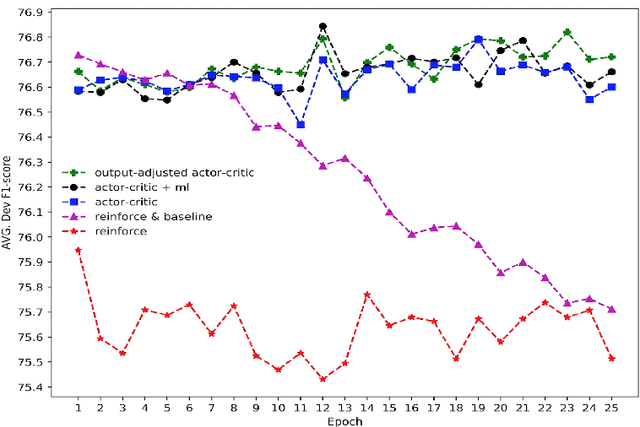

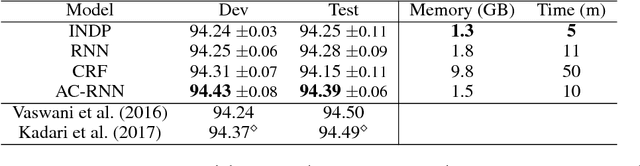
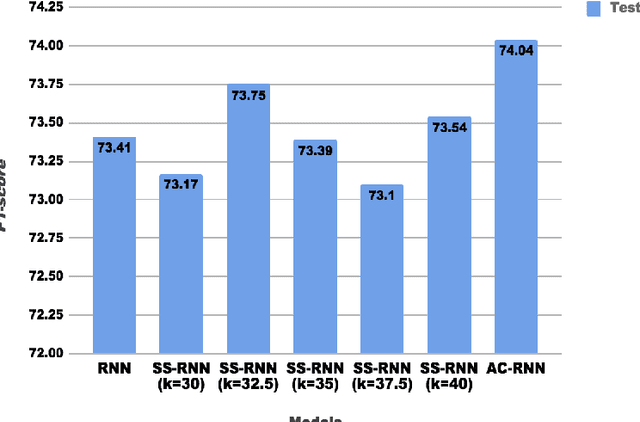
Neural approaches to sequence labeling often use a Conditional Random Field (CRF) to model their output dependencies, while Recurrent Neural Networks (RNN) are used for the same purpose in other tasks. We set out to establish RNNs as an attractive alternative to CRFs for sequence labeling. To do so, we address one of the RNN's most prominent shortcomings, the fact that it is not exposed to its own errors with the maximum-likelihood training. We frame the prediction of the output sequence as a sequential decision-making process, where we train the network with an adjusted actor-critic algorithm (AC-RNN). We comprehensively compare this strategy with maximum-likelihood training for both RNNs and CRFs on three structured-output tasks. The proposed AC-RNN efficiently matches the performance of the CRF on NER and CCG tagging, and outperforms it on Machine Transliteration. We also show that our training strategy is significantly better than other techniques for addressing RNN's exposure bias, such as Scheduled Sampling, and Self-Critical policy training.
String Transduction with Target Language Models and Insertion Handling
Sep 19, 2018
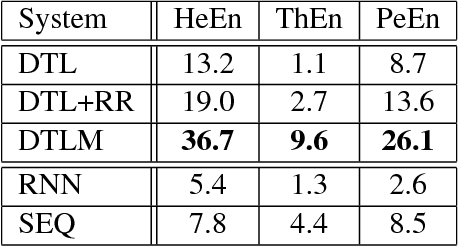
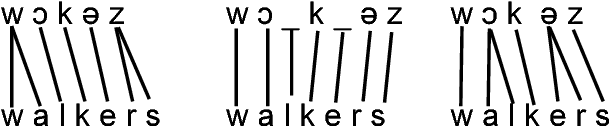

Many character-level tasks can be framed as sequence-to-sequence transduction, where the target is a word from a natural language. We show that leveraging target language models derived from unannotated target corpora, combined with a precise alignment of the training data, yields state-of-the art results on cognate projection, inflection generation, and phoneme-to-grapheme conversion.