 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Consistency in Multimodal Large Language Models
Nov 14, 2024Recent developments in multimodal methodologies have marked the beginning of an exciting era for models adept at processing diverse data types, encompassing text, audio, and visual content. Models like GPT-4V, which merge computer vision with advanced language processing, exhibit extraordinary proficiency in handling intricate tasks that require a simultaneous understanding of both textual and visual information. Prior research efforts have meticulously evaluated the efficacy of these Vision Large Language Models (VLLMs) in various domains, including object detection, image captioning, and other related fields. However, existing analyses have often suffered from limitations, primarily centering on the isolated evaluation of each modality's performance while neglecting to explore their intricate cross-modal interactions. Specifically, the question of whether these models achieve the same level of accuracy when confronted with identical task instances across different modalities remains unanswered. In this study, we take the initiative to delve into the interaction and comparison among these modalities of interest by introducing a novel concept termed cross-modal consistency. Furthermore, we propose a quantitative evaluation framework founded on this concept. Our experimental findings, drawn from a curated collection of parallel vision-language datasets developed by us, unveil a pronounced inconsistency between the vision and language modalities within GPT-4V, despite its portrayal as a unified multimodal model. Our research yields insights into the appropriate utilization of such models and hints at potential avenues for enhancing their design.
UAlberta at SemEval-2023 Task 1: Context Augmentation and Translation for Multilingual Visual Word Sense Disambiguation
Jun 24, 2023



We describe the systems of the University of Alberta team for the SemEval-2023 Visual Word Sense Disambiguation (V-WSD) Task. We present a novel algorithm that leverages glosses retrieved from BabelNet, in combination with text and image encoders. Furthermore, we compare language-specific encoders against the application of English encoders to translated texts. As the contexts given in the task datasets are extremely short, we also experiment with augmenting these contexts with descriptions generated by a language model. This yields substantial improvements in accuracy. We describe and evaluate additional V-WSD methods which use image generation and text-conditioned image segmentation. Overall, the results of our official submission rank us 18 out of 56 teams. Some of our unofficial results are even better than the official ones. Our code is publicly available at https://github.com/UAlberta-NLP/v-wsd.
Visually-Grounded Descriptions Improve Zero-Shot Image Classification
Jun 23, 2023
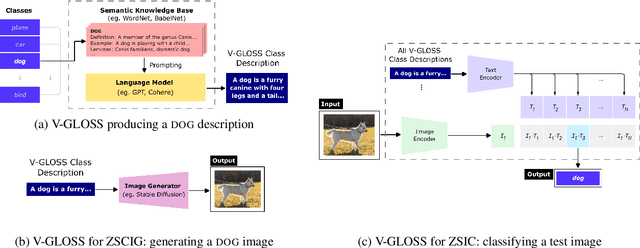

Language-vision models like CLIP have made significant progress in zero-shot vision tasks, such as zero-shot image classification (ZSIC). However, generating specific and expressive class descriptions remains a major challenge. Existing approaches suffer from granularity and label ambiguity issues. To tackle these challenges, we propose V-GLOSS: Visual Glosses, a novel method leveraging modern language models and semantic knowledge bases to produce visually-grounded class descriptions. We demonstrate V-GLOSS's effectiveness by achieving state-of-the-art results on benchmark ZSIC datasets including ImageNet and STL-10. In addition, we introduce a silver dataset with class descriptions generated by V-GLOSS, and show its usefulness for vision tasks. We make available our code and dataset.
Don't Trust GPT When Your Question Is Not In English
May 24, 2023Large Language Models (LLMs) have demonstrated exceptional natural language understanding abilities and have excelled in a variety of natural language processing (NLP)tasks in recent years. Despite the fact that most LLMs are trained predominantly in English, multiple studies have demonstrated their comparative performance in many other languages. However, fundamental questions persist regarding how LLMs acquire their multi-lingual abilities and how performance varies across different languages. These inquiries are crucial for the study of LLMs since users and researchers often come from diverse language backgrounds, potentially influencing their utilization and interpretation of LLMs' results. In this work, we propose a systematic way of qualifying the performance disparities of LLMs under multilingual settings. We investigate the phenomenon of across-language generalizations in LLMs, wherein insufficient multi-lingual training data leads to advanced multi-lingual capabilities. To accomplish this, we employ a novel back-translation-based prompting method. The results show that GPT exhibits highly translating-like behaviour in multilingual settings.
UAlberta at SemEval 2022 Task 2: Leveraging Glosses and Translations for Multilingual Idiomaticity Detection
May 27, 2022
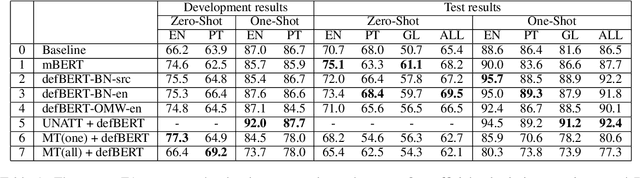
We describe the University of Alberta systems for the SemEval-2022 Task 2 on multilingual idiomaticity detection. Working under the assumption that idiomatic expressions are noncompositional, our first method integrates information on the meanings of the individual words of an expression into a binary classifier. Further hypothesizing that literal and idiomatic expressions translate differently, our second method translates an expression in context, and uses a lexical knowledge base to determine if the translation is literal. Our approaches are grounded in linguistic phenomena, and leverage existing sources of lexical knowledge. Our results offer support for both approaches, particularly the former.
WiC = TSV = WSD: On the Equivalence of Three Semantic Tasks
Jul 29, 2021
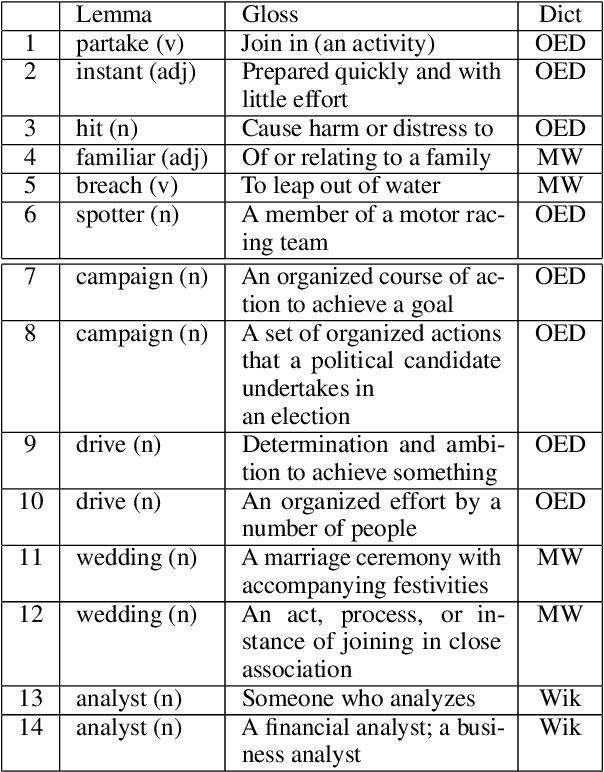
The WiC task has attracted considerable attention in the NLP community, as demonstrated by the popularity of the recent MCL-WiC SemEval task. WSD systems and lexical resources have been used for the WiC task, as well as for WiC dataset construction. TSV is another task related to both WiC and WSD. We aim to establish the exact relationship between WiC, TSV, and WSD. We demonstrate that these semantic classification problems can be pairwise reduced to each other, and so they are theoretically equivalent. We analyze the existing WiC datasets to validate this equivalence hypothesis. We conclude that our understanding of semantic tasks can be increased through the applications of tools from theoretical computer science. Our findings also suggests that more efficient and simpler methods for one of these tasks could be successfully applied in the other two.
Semi-Supervised and Unsupervised Sense Annotation via Translations
Jun 11, 2021


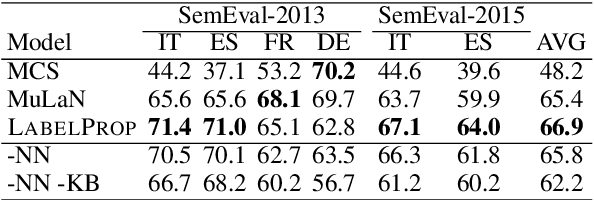
Acquisition of multilingual training data continues to be a challenge in word sense disambiguation (WSD). To address this problem, unsupervised approaches have been developed in recent years that automatically generate sense annotations suitable for training supervised WSD systems. We present three new methods to creating sense-annotated corpora, which leverage translations, parallel corpora, lexical resources, and contextual and synset embeddings. Our semi-supervised method applies machine translation to transfer existing sense annotations to other languages. Our two unsupervised methods use a knowledge-based WSD system to annotate a parallel corpus, and refine the resulting sense annotations by identifying lexical translations. We obtain state-of-the-art results on standard WSD benchmarks.
One Sense Per Translation
Jun 10, 2021
The idea of using lexical translations to define sense inventories has a long history in lexical semantics. We propose a theoretical framework which allows us to answer the question of why this apparently reasonable idea failed to produce useful results. We formally prove several propositions on how the translations of a word relate to its senses, as well as on the relationship between synonymy and polysemy. We empirically validate our theoretical findings on BabelNet, and demonstrate how they could be used to perform unsupervised word sense disambiguation of a substantial fraction of the lexicon.
Synonymy = Translational Equivalence
Apr 28, 2020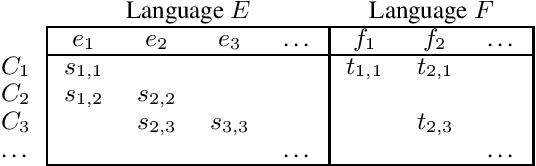


Synonymy and translational equivalence are the relations of sameness of meaning within and across languages. As the principal relations in wordnets and multi-wordnets, they are vital to computational lexical semantics, yet the field suffers from the absence of a common formal framework to define their properties and mutual relationship. This paper proposes a unifying treatment of these two relations, which is validated by experiments on existing resources. The theory establishes a solid foundation for critically re-evaluating prior work in cross-lingual semantics, and facilitating the creation, verification, and amelioration of lexical resources.
One Homonym per Translation
Apr 17, 2019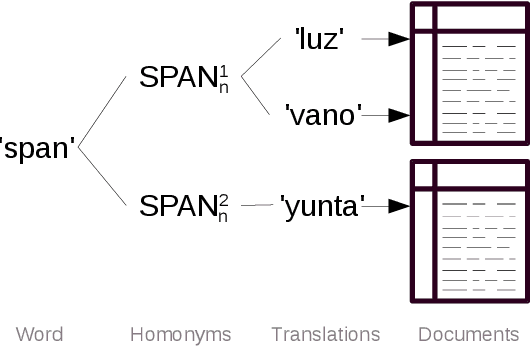


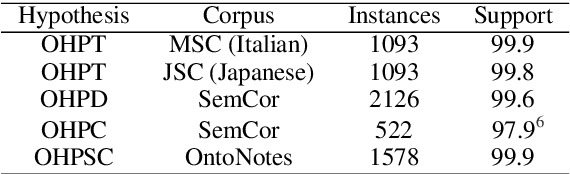
The study of homonymy is vital to resolving fundamental problems in lexical semantics. In this paper, we propose four hypotheses that characterize the unique behavior of homonyms in the context of translations, discourses, collocations, and sense clusters. We present a new annotated homonym resource that allows us to test our hypotheses on existing WSD resources. The results of the experiments provide strong empirical evidence for the hypotheses. This study represents a step towards a computational method for distinguishing between homonymy and polysemy, and constructing a definitive inventory of coarse-grained senses.