 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Tokens to Numbers: Continuous Number Modeling for SVG Generation
Feb 02, 2026For certain image generation tasks, vector graphics such as Scalable Vector Graphics (SVGs) offer clear benefits such as increased flexibility, size efficiency, and editing ease, but remain less explored than raster-based approaches. A core challenge is that the numerical, geometric parameters, which make up a large proportion of SVGs, are inefficiently encoded as long sequences of tokens. This slows training, reduces accuracy, and hurts generalization. To address these problems, we propose Continuous Number Modeling (CNM), an approach that directly models numbers as first-class, continuous values rather than discrete tokens. This formulation restores the mathematical elegance of the representation by aligning the model's inputs with the data's continuous nature, removing discretization artifacts introduced by token-based encoding. We then train a multimodal transformer on 2 million raster-to-SVG samples, followed by fine-tuning via reinforcement learning using perceptual feedback to further improve visual quality. Our approach improves training speed by over 30% while maintaining higher perceptual fidelity compared to alternative approaches. This work establishes CNM as a practical and efficient approach for high-quality vector generation, with potential for broader applications. We make our code available http://github.com/mikeogezi/CNM.
SpaRE: Enhancing Spatial Reasoning in Vision-Language Models with Synthetic Data
Apr 29, 2025
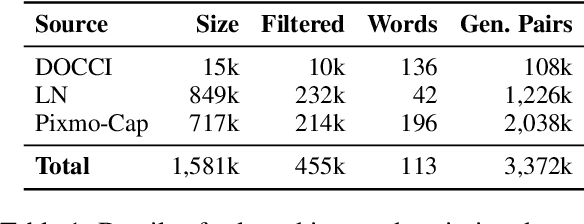
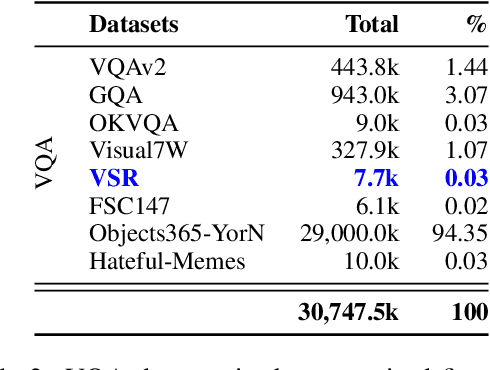

Vision-language models (VLMs) work well in tasks ranging from image captioning to visual question answering (VQA), yet they struggle with spatial reasoning, a key skill for understanding our physical world that humans excel at. We find that spatial relations are generally rare in widely used VL datasets, with only a few being well represented, while most form a long tail of underrepresented relations. This gap leaves VLMs ill-equipped to handle diverse spatial relationships. To bridge it, we construct a synthetic VQA dataset focused on spatial reasoning generated from hyper-detailed image descriptions in Localized Narratives, DOCCI, and PixMo-Cap. Our dataset consists of 455k samples containing 3.4 million QA pairs. Trained on this dataset, our Spatial-Reasoning Enhanced (SpaRE) VLMs show strong improvements on spatial reasoning benchmarks, achieving up to a 49% performance gain on the What's Up benchmark, while maintaining strong results on general tasks. Our work narrows the gap between human and VLM spatial reasoning and makes VLMs more capable in real-world tasks such as robotics and navigation.
Optimizing Negative Prompts for Enhanced Aesthetics and Fidelity in Text-To-Image Generation
Mar 12, 2024In text-to-image generation, using negative prompts, which describe undesirable image characteristics, can significantly boost image quality. However, producing good negative prompts is manual and tedious. To address this, we propose NegOpt, a novel method for optimizing negative prompt generation toward enhanced image generation, using supervised fine-tuning and reinforcement learning. Our combined approach results in a substantial increase of 25% in Inception Score compared to other approaches and surpasses ground-truth negative prompts from the test set. Furthermore, with NegOpt we can preferentially optimize the metrics most important to us. Finally, we construct Negative Prompts DB, a dataset of negative prompts.
UAlberta at SemEval-2023 Task 1: Context Augmentation and Translation for Multilingual Visual Word Sense Disambiguation
Jun 24, 2023



We describe the systems of the University of Alberta team for the SemEval-2023 Visual Word Sense Disambiguation (V-WSD) Task. We present a novel algorithm that leverages glosses retrieved from BabelNet, in combination with text and image encoders. Furthermore, we compare language-specific encoders against the application of English encoders to translated texts. As the contexts given in the task datasets are extremely short, we also experiment with augmenting these contexts with descriptions generated by a language model. This yields substantial improvements in accuracy. We describe and evaluate additional V-WSD methods which use image generation and text-conditioned image segmentation. Overall, the results of our official submission rank us 18 out of 56 teams. Some of our unofficial results are even better than the official ones. Our code is publicly available at https://github.com/UAlberta-NLP/v-wsd.
Visually-Grounded Descriptions Improve Zero-Shot Image Classification
Jun 23, 2023
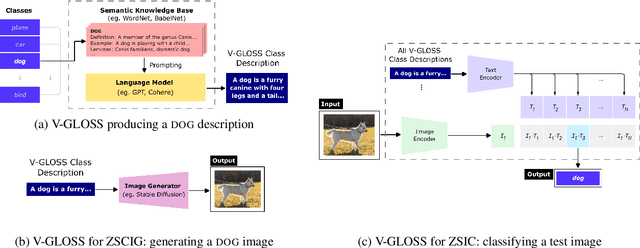

Language-vision models like CLIP have made significant progress in zero-shot vision tasks, such as zero-shot image classification (ZSIC). However, generating specific and expressive class descriptions remains a major challenge. Existing approaches suffer from granularity and label ambiguity issues. To tackle these challenges, we propose V-GLOSS: Visual Glosses, a novel method leveraging modern language models and semantic knowledge bases to produce visually-grounded class descriptions. We demonstrate V-GLOSS's effectiveness by achieving state-of-the-art results on benchmark ZSIC datasets including ImageNet and STL-10. In addition, we introduce a silver dataset with class descriptions generated by V-GLOSS, and show its usefulness for vision tasks. We make available our code and dataset.