 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised and Unsupervised Sense Annotation via Translations
Jun 11, 2021


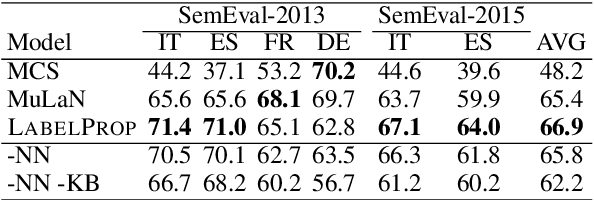
Acquisition of multilingual training data continues to be a challenge in word sense disambiguation (WSD). To address this problem, unsupervised approaches have been developed in recent years that automatically generate sense annotations suitable for training supervised WSD systems. We present three new methods to creating sense-annotated corpora, which leverage translations, parallel corpora, lexical resources, and contextual and synset embeddings. Our semi-supervised method applies machine translation to transfer existing sense annotations to other languages. Our two unsupervised methods use a knowledge-based WSD system to annotate a parallel corpus, and refine the resulting sense annotations by identifying lexical translations. We obtain state-of-the-art results on standard WSD benchmarks.