 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Representation Learning for Language Modeling
Paper and Code
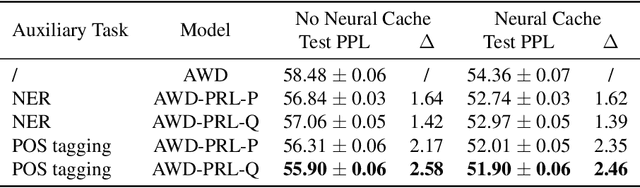
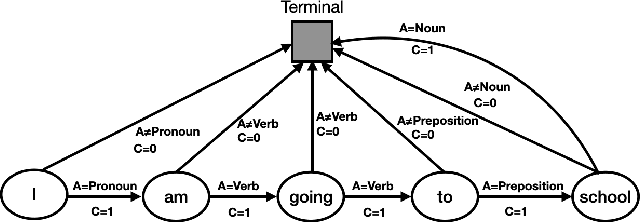
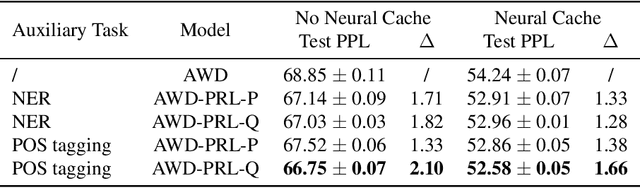
To effectively perform the task of next-word prediction, long short-term memory networks (LSTMs) must keep track of many types of information. Some information is directly related to the next word's identity, but some is more secondary (e.g. discourse-level features or features of downstream words). Correlates of secondary information appear in LSTM representations even though they are not part of an \emph{explicitly} supervised prediction task. In contrast, in reinforcement learning (RL), techniques that explicitly supervise representations to predict secondary information have been shown to be beneficial. Inspired by that success, we propose Predictive Representation Learning (PRL), which explicitly constrains LSTMs to encode specific predictions, like those that might need to be learned implicitly. We show that PRL 1) significantly improves two strong language modeling methods, 2) converges more quickly, and 3) performs better when data is limited. Our work shows that explicitly encoding a simple predictive task facilitates the search for a more effective language model.