 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentional Updates for Streaming Reinforcement Learning
Apr 21, 2026In gradient-based learning, a step size chosen in parameter units does not produce a predictable per-step change in function output. This often leads to instability in the streaming setting (i.e., batch size=1), where stochasticity is not averaged out and update magnitudes can momentarily become arbitrarily big or small. Instead, we propose intentional updates: first specify the intended outcome of an update and then solve for the step size that approximately achieves it. This strategy has precedent in online supervised linear regression via Normalized Least Mean Squares algorithm, which selects a step size to yield a specified change in the function output proportional to the current error. We extend this principle to streaming deep reinforcement learning by defining appropriate intended outcomes: Intentional TD aims for a fixed fractional reduction of the TD error, and Intentional Policy Gradient aims for a bounded per-step change in the policy, limiting local KL divergence. We propose practical algorithms combining eligibility traces and diagonal scaling. Empirically, these methods yield state-of-the-art streaming performance, frequently performing on par with batch and replay-buffer approaches.
A Deep Learning Framework for Thyroid Nodule Segmentation and Malignancy Classification from Ultrasound Images
Nov 14, 2025
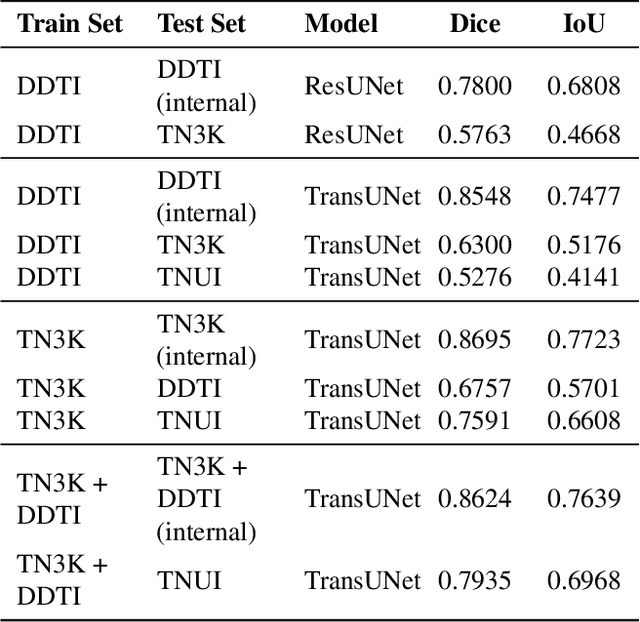
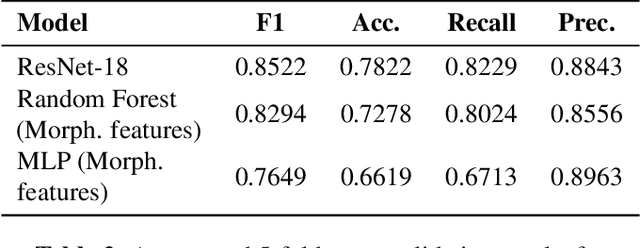
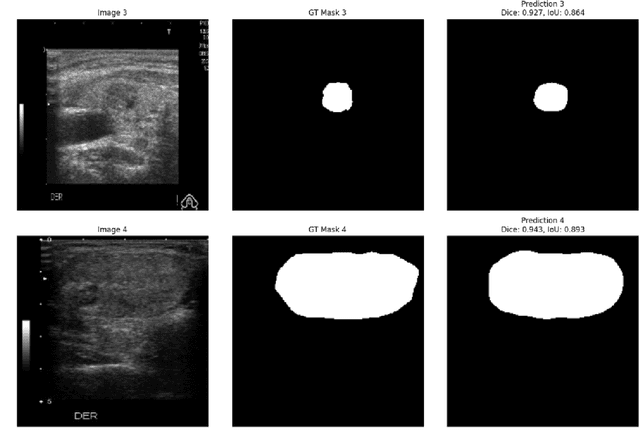
Ultrasound-based risk stratification of thyroid nodules is a critical clinical task, but it suffers from high inter-observer variability. While many deep learning (DL) models function as "black boxes," we propose a fully automated, two-stage framework for interpretable malignancy prediction. Our method achieves interpretability by forcing the model to focus only on clinically relevant regions. First, a TransUNet model automatically segments the thyroid nodule. The resulting mask is then used to create a region of interest around the nodule, and this localised image is fed directly into a ResNet-18 classifier. We evaluated our framework using 5-fold cross-validation on a clinical dataset of 349 images, where it achieved a high F1-score of 0.852 for predicting malignancy. To validate its performance, we compared it against a strong baseline using a Random Forest classifier with hand-crafted morphological features, which achieved an F1-score of 0.829. The superior performance of our DL framework suggests that the implicit visual features learned from the localised nodule are more predictive than explicit shape features alone. This is the first fully automated end-to-end pipeline for both detecting thyroid nodules on ultrasound images and predicting their malignancy.
Deep Policy Gradient Methods Without Batch Updates, Target Networks, or Replay Buffers
Nov 22, 2024Modern deep policy gradient methods achieve effective performance on simulated robotic tasks, but they all require large replay buffers or expensive batch updates, or both, making them incompatible for real systems with resource-limited computers. We show that these methods fail catastrophically when limited to small replay buffers or during incremental learning, where updates only use the most recent sample without batch updates or a replay buffer. We propose a novel incremental deep policy gradient method -- Action Value Gradient (AVG) and a set of normalization and scaling techniques to address the challenges of instability in incremental learning. On robotic simulation benchmarks, we show that AVG is the only incremental method that learns effectively, often achieving final performance comparable to batch policy gradient methods. This advancement enabled us to show for the first time effective deep reinforcement learning with real robots using only incremental updates, employing a robotic manipulator and a mobile robot.
Streaming Deep Reinforcement Learning Finally Works
Oct 18, 2024Natural intelligence processes experience as a continuous stream, sensing, acting, and learning moment-by-moment in real time. Streaming learning, the modus operandi of classic reinforcement learning (RL) algorithms like Q-learning and TD, mimics natural learning by using the most recent sample without storing it. This approach is also ideal for resource-constrained, communication-limited, and privacy-sensitive applications. However, in deep RL, learners almost always use batch updates and replay buffers, making them computationally expensive and incompatible with streaming learning. Although the prevalence of batch deep RL is often attributed to its sample efficiency, a more critical reason for the absence of streaming deep RL is its frequent instability and failure to learn, which we refer to as stream barrier. This paper introduces the stream-x algorithms, the first class of deep RL algorithms to overcome stream barrier for both prediction and control and match sample efficiency of batch RL. Through experiments in Mujoco Gym, DM Control Suite, and Atari Games, we demonstrate stream barrier in existing algorithms and successful stable learning with our stream-x algorithms: stream Q, stream AC, and stream TD, achieving the best model-free performance in DM Control Dog environments. A set of common techniques underlies the stream-x algorithms, enabling their success with a single set of hyperparameters and allowing for easy extension to other algorithms, thereby reviving streaming RL.
Weight Clipping for Deep Continual and Reinforcement Learning
Jul 01, 2024



Many failures in deep continual and reinforcement learning are associated with increasing magnitudes of the weights, making them hard to change and potentially causing overfitting. While many methods address these learning failures, they often change the optimizer or the architecture, a complexity that hinders widespread adoption in various systems. In this paper, we focus on learning failures that are associated with increasing weight norm and we propose a simple technique that can be easily added on top of existing learning systems: clipping neural network weights to limit them to a specific range. We study the effectiveness of weight clipping in a series of supervised and reinforcement learning experiments. Our empirical results highlight the benefits of weight clipping for generalization, addressing loss of plasticity and policy collapse, and facilitating learning with a large replay ratio.
Revisiting Scalable Hessian Diagonal Approximations for Applications in Reinforcement Learning
Jun 05, 2024Second-order information is valuable for many applications but challenging to compute. Several works focus on computing or approximating Hessian diagonals, but even this simplification introduces significant additional costs compared to computing a gradient. In the absence of efficient exact computation schemes for Hessian diagonals, we revisit an early approximation scheme proposed by Becker and LeCun (1989, BL89), which has a cost similar to gradients and appears to have been overlooked by the community. We introduce HesScale, an improvement over BL89, which adds negligible extra computation. On small networks, we find that this improvement is of higher quality than all alternatives, even those with theoretical guarantees, such as unbiasedness, while being much cheaper to compute. We use this insight in reinforcement learning problems where small networks are used and demonstrate HesScale in second-order optimization and scaling the step-size parameter. In our experiments, HesScale optimizes faster than existing methods and improves stability through step-size scaling. These findings are promising for scaling second-order methods in larger models in the future.
Addressing Loss of Plasticity and Catastrophic Forgetting in Continual Learning
Mar 31, 2024Deep representation learning methods struggle with continual learning, suffering from both catastrophic forgetting of useful units and loss of plasticity, often due to rigid and unuseful units. While many methods address these two issues separately, only a few currently deal with both simultaneously. In this paper, we introduce Utility-based Perturbed Gradient Descent (UPGD) as a novel approach for the continual learning of representations. UPGD combines gradient updates with perturbations, where it applies smaller modifications to more useful units, protecting them from forgetting, and larger modifications to less useful units, rejuvenating their plasticity. We use a challenging streaming learning setup where continual learning problems have hundreds of non-stationarities and unknown task boundaries. We show that many existing methods suffer from at least one of the issues, predominantly manifested by their decreasing accuracy over tasks. On the other hand, UPGD continues to improve performance and surpasses or is competitive with all methods in all problems. Finally, in extended reinforcement learning experiments with PPO, we show that while Adam exhibits a performance drop after initial learning, UPGD avoids it by addressing both continual learning issues.
Terahertz Multiple Access: A Deep Reinforcement Learning Controlled Multihop IRS Topology
Mar 16, 2023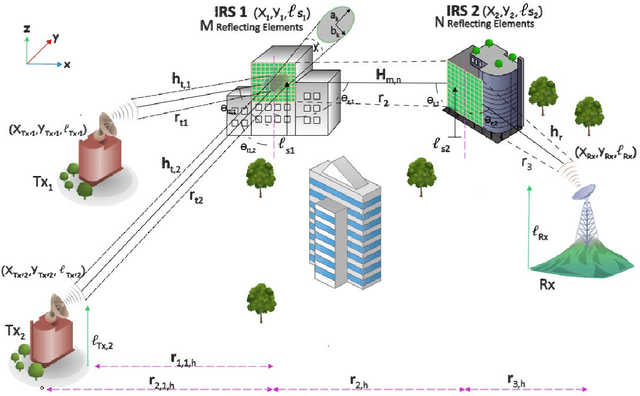
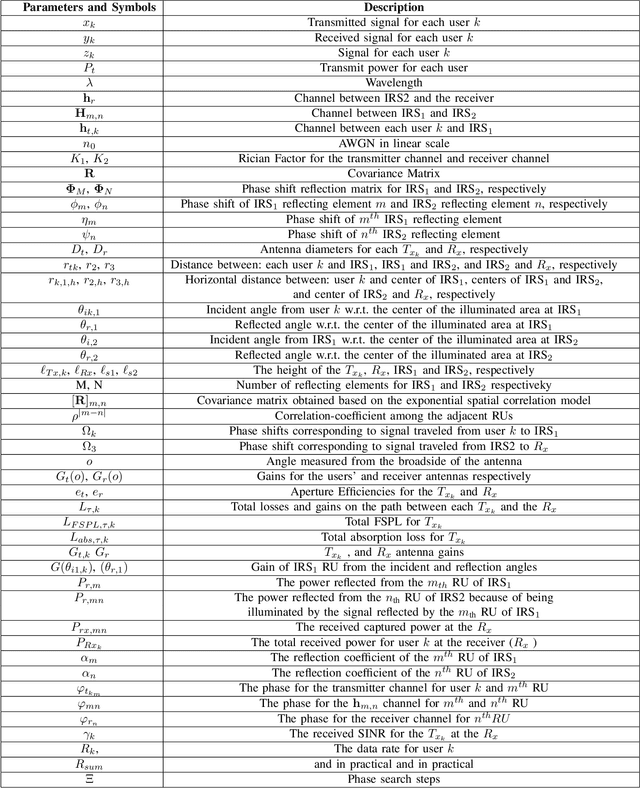
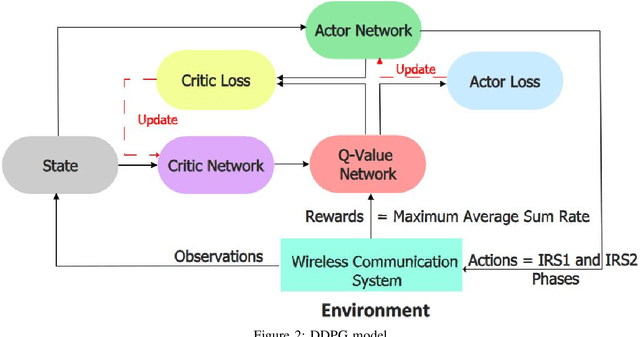
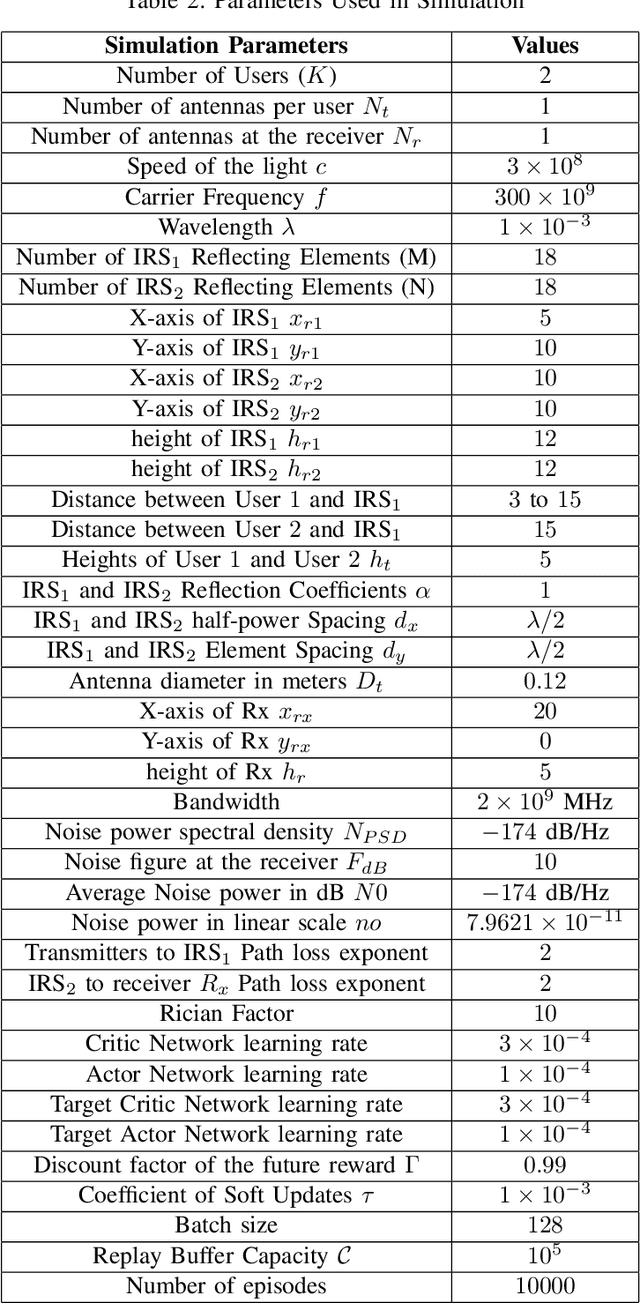
We investigate THz communication uplink multiple access using cascaded intelligent reflecting surfaces (IRSs) assuming correlated channels. Two independent objectives to be achieved via adjusting the phases of the cascaded IRSs: 1) maximizing the received rate of a desired user under interference from the second user and 2) maximizing the sum rate of both users. The resulting optimization problems are non-convex. For the first objective, we devise a sub-optimal analytical solution by maximizing the received power of the desired user, however, this results in an over determined system. Approximate solutions using pseudo-inverse and block-based approaches are attempted. For the second objective, a loose upperbound is derived and an exhaustive search solution is utilized. We then use deep reinforcement learning (DRL) to solve both objectives. Results reveal the suitability of DRL for such complex configurations. For the first objective, the DRL-based solution is superior to the sub-optimal mathematical methods, while for the second objective, it produces sum rates almost close to the exhaustive search. Further, the results reveal that as the correlation-coefficient increases, the sum rate of DRL increases, since it benefits from the presence of correlation in the channel to improve statistical learning.
Utility-based Perturbed Gradient Descent: An Optimizer for Continual Learning
Feb 07, 2023Modern representation learning methods may fail to adapt quickly under non-stationarity since they suffer from the problem of catastrophic forgetting and decaying plasticity. Such problems prevent learners from fast adaptation to changes since they result in increasing numbers of saturated features and forgetting useful features when presented with new experiences. Hence, these methods are rendered ineffective for continual learning. This paper proposes Utility-based Perturbed Gradient Descent (UPGD), an online representation-learning algorithm well-suited for continual learning agents with no knowledge about task boundaries. UPGD protects useful weights or features from forgetting and perturbs less useful ones based on their utilities. Our empirical results show that UPGD alleviates catastrophic forgetting and decaying plasticity, enabling modern representation learning methods to work in the continual learning setting.
Hybrid-Layers Neural Network Architectures for Modeling the Self-Interference in Full-Duplex Systems
Oct 18, 2021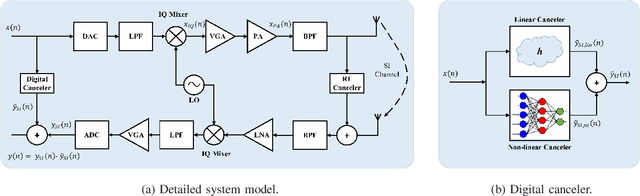
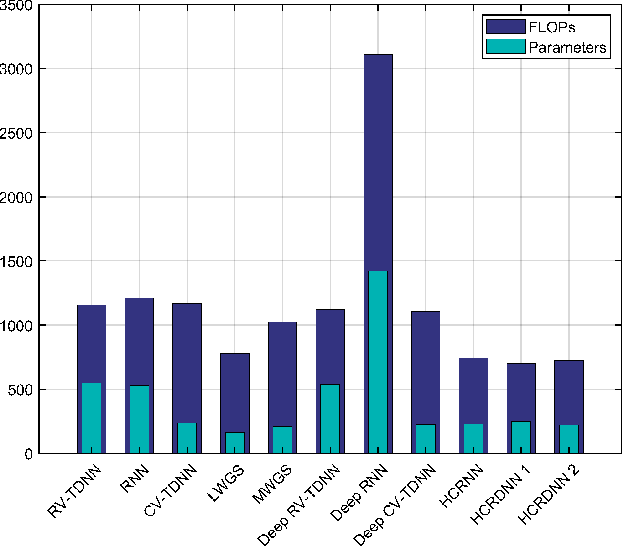
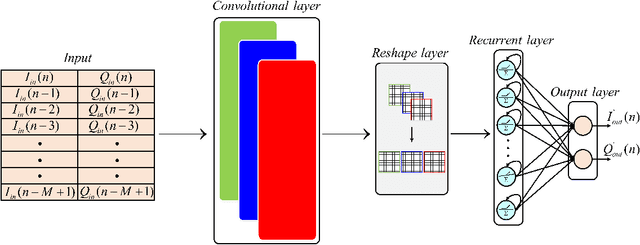
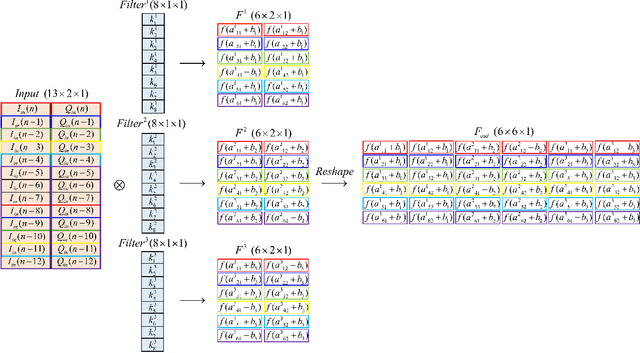
Full-duplex (FD) systems have been introduced to provide high data rates for beyond fifth-generation wireless networks through simultaneous transmission of information over the same frequency resources. However, the operation of FD systems is practically limited by the self-interference (SI), and efficient SI cancelers are sought to make the FD systems realizable. Typically, polynomial-based cancelers are employed to mitigate the SI; nevertheless, they suffer from high complexity. This article proposes two novel hybrid-layers neural network (NN) architectures to cancel the SI with low complexity. The first architecture is referred to as hybrid-convolutional recurrent NN (HCRNN), whereas the second is termed as hybrid-convolutional recurrent dense NN (HCRDNN). In contrast to the state-of-the-art NNs that employ dense or recurrent layers for SI modeling, the proposed NNs exploit, in a novel manner, a combination of different hidden layers (e.g., convolutional, recurrent, and/or dense) in order to model the SI with lower computational complexity than the polynomial and the state-of-the-art NN-based cancelers. The key idea behind using hybrid layers is to build an NN model, which makes use of the characteristics of the different layers employed in its architecture. More specifically, in the HCRNN, a convolutional layer is employed to extract the input data features using a reduced network scale. Moreover, a recurrent layer is then applied to assist in learning the temporal behavior of the input signal from the localized feature map of the convolutional layer. In the HCRDNN, an additional dense layer is exploited to add another degree of freedom for adapting the NN settings in order to achieve the best compromise between the cancellation performance and computational complexity. Complexity analysis and numerical simulations are provided to prove the superiority of the proposed architectures.