 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Scalable Hessian Diagonal Approximations for Applications in Reinforcement Learning
Jun 05, 2024Second-order information is valuable for many applications but challenging to compute. Several works focus on computing or approximating Hessian diagonals, but even this simplification introduces significant additional costs compared to computing a gradient. In the absence of efficient exact computation schemes for Hessian diagonals, we revisit an early approximation scheme proposed by Becker and LeCun (1989, BL89), which has a cost similar to gradients and appears to have been overlooked by the community. We introduce HesScale, an improvement over BL89, which adds negligible extra computation. On small networks, we find that this improvement is of higher quality than all alternatives, even those with theoretical guarantees, such as unbiasedness, while being much cheaper to compute. We use this insight in reinforcement learning problems where small networks are used and demonstrate HesScale in second-order optimization and scaling the step-size parameter. In our experiments, HesScale optimizes faster than existing methods and improves stability through step-size scaling. These findings are promising for scaling second-order methods in larger models in the future.
Reducing the Cost of Cycle-Time Tuning for Real-World Policy Optimization
May 09, 2023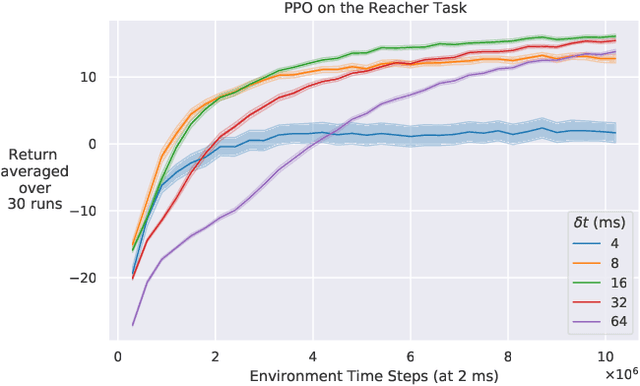
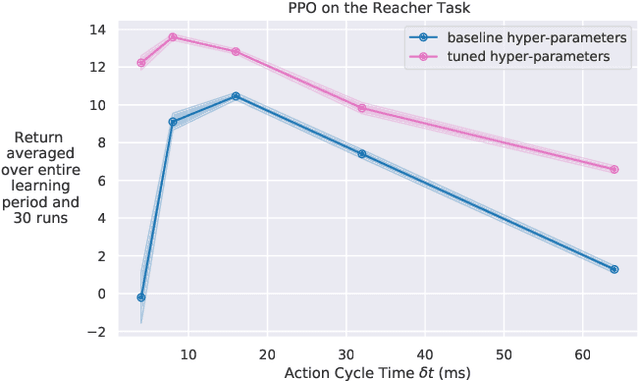
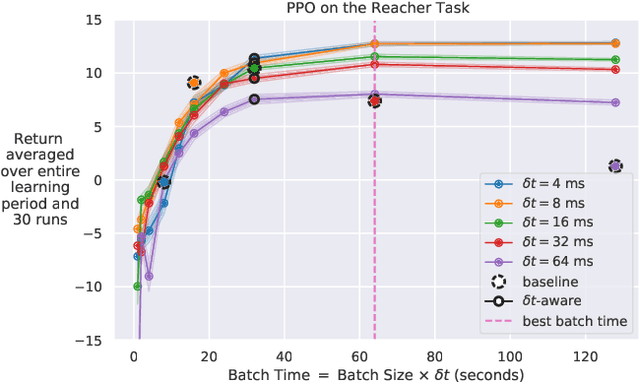
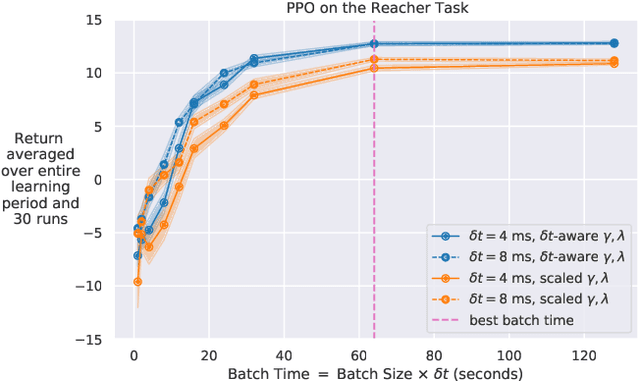
Continuous-time reinforcement learning tasks commonly use discrete steps of fixed cycle times for actions. As practitioners need to choose the action-cycle time for a given task, a significant concern is whether the hyper-parameters of the learning algorithm need to be re-tuned for each choice of the cycle time, which is prohibitive for real-world robotics. In this work, we investigate the widely-used baseline hyper-parameter values of two policy gradient algorithms -- PPO and SAC -- across different cycle times. Using a benchmark task where the baseline hyper-parameters of both algorithms were shown to work well, we reveal that when a cycle time different than the task default is chosen, PPO with baseline hyper-parameters fails to learn. Moreover, both PPO and SAC with their baseline hyper-parameters perform substantially worse than their tuned values for each cycle time. We propose novel approaches for setting these hyper-parameters based on the cycle time. In our experiments on simulated and real-world robotic tasks, the proposed approaches performed at least as well as the baseline hyper-parameters, with significantly better performance for most choices of the cycle time, and did not result in learning failure for any cycle time. Hyper-parameter tuning still remains a significant barrier for real-world robotics, as our approaches require some initial tuning on a new task, even though it is negligible compared to an extensive tuning for each cycle time. Our approach requires no additional tuning after the cycle time is changed for a given task and is a step toward avoiding extensive and costly hyper-parameter tuning for real-world policy optimization.