 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-ttention: Ultra Sparse Visual Generation via Attention Statistical Reshape
May 28, 2025Diffusion Transformers (DiT) have become the de-facto model for generating high-quality visual content like videos and images. A huge bottleneck is the attention mechanism where complexity scales quadratically with resolution and video length. One logical way to lessen this burden is sparse attention, where only a subset of tokens or patches are included in the calculation. However, existing techniques fail to preserve visual quality at extremely high sparsity levels and might even incur non-negligible compute overheads. % To address this concern, we propose Re-ttention, which implements very high sparse attention for visual generation models by leveraging the temporal redundancy of Diffusion Models to overcome the probabilistic normalization shift within the attention mechanism. Specifically, Re-ttention reshapes attention scores based on the prior softmax distribution history in order to preserve the visual quality of the full quadratic attention at very high sparsity levels. % Experimental results on T2V/T2I models such as CogVideoX and the PixArt DiTs demonstrate that Re-ttention requires as few as 3.1\% of the tokens during inference, outperforming contemporary methods like FastDiTAttn, Sparse VideoGen and MInference. Further, we measure latency to show that our method can attain over 45\% end-to-end % and over 92\% self-attention latency reduction on an H100 GPU at negligible overhead cost. Code available online here: \href{https://github.com/cccrrrccc/Re-ttention}{https://github.com/cccrrrccc/Re-ttention}
FP4DiT: Towards Effective Floating Point Quantization for Diffusion Transformers
Mar 19, 2025Diffusion Models (DM) have revolutionized the text-to-image visual generation process. However, the large computational cost and model footprint of DMs hinders practical deployment, especially on edge devices. Post-training quantization (PTQ) is a lightweight method to alleviate these burdens without the need for training or fine-tuning. While recent DM PTQ methods achieve W4A8 on integer-based PTQ, two key limitations remain: First, while most existing DM PTQ methods evaluate on classical DMs like Stable Diffusion XL, 1.5 or earlier, which use convolutional U-Nets, newer Diffusion Transformer (DiT) models like the PixArt series, Hunyuan and others adopt fundamentally different transformer backbones to achieve superior image synthesis. Second, integer (INT) quantization is prevailing in DM PTQ but doesn't align well with the network weight and activation distribution, while Floating-Point Quantization (FPQ) is still under-investigated, yet it holds the potential to better align the weight and activation distributions in low-bit settings for DiT. In response, we introduce FP4DiT, a PTQ method that leverages FPQ to achieve W4A6 quantization. Specifically, we extend and generalize the Adaptive Rounding PTQ technique to adequately calibrate weight quantization for FPQ and demonstrate that DiT activations depend on input patch data, necessitating robust online activation quantization techniques. Experimental results demonstrate that FP4DiT outperforms integer-based PTQ at W4A6 and W4A8 precision and generates convincing visual content on PixArt-$\alpha$, PixArt-$\Sigma$ and Hunyuan in terms of several T2I metrics such as HPSv2 and CLIP.
Applying Graph Explanation to Operator Fusion
Dec 31, 2024



Layer fusion techniques are critical to improving the inference efficiency of deep neural networks (DNN) for deployment. Fusion aims to lower inference costs by reducing data transactions between an accelerator's on-chip buffer and DRAM. This is accomplished by grouped execution of multiple operations like convolution and activations together into single execution units - fusion groups. However, on-chip buffer capacity limits fusion group size and optimizing fusion on whole DNNs requires partitioning into multiple fusion groups. Finding the optimal groups is a complex problem where the presence of invalid solutions hampers traditional search algorithms and demands robust approaches. In this paper we incorporate Explainable AI, specifically Graph Explanation Techniques (GET), into layer fusion. Given an invalid fusion group, we identify the operations most responsible for group invalidity, then use this knowledge to recursively split the original fusion group via a greedy tree-based algorithm to minimize DRAM access. We pair our scheme with common algorithms and optimize DNNs on two types of layer fusion: Line-Buffer Depth First (LBDF) and Branch Requirement Reduction (BRR). Experiments demonstrate the efficacy of our scheme on several popular and classical convolutional neural networks like ResNets and MobileNets. Our scheme achieves over 20% DRAM Access reduction on EfficientNet-B3.
Qua$^2$SeDiMo: Quantifiable Quantization Sensitivity of Diffusion Models
Dec 19, 2024
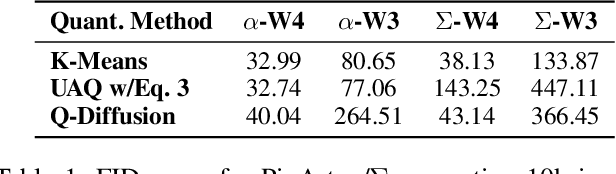

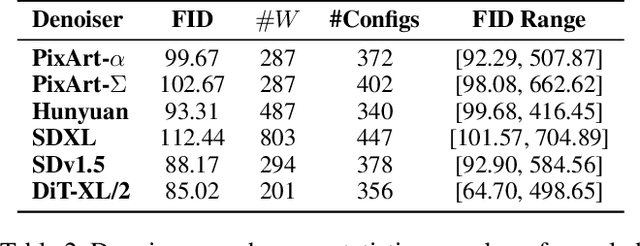
Diffusion Models (DM) have democratized AI image generation through an iterative denoising process. Quantization is a major technique to alleviate the inference cost and reduce the size of DM denoiser networks. However, as denoisers evolve from variants of convolutional U-Nets toward newer Transformer architectures, it is of growing importance to understand the quantization sensitivity of different weight layers, operations and architecture types to performance. In this work, we address this challenge with Qua$^2$SeDiMo, a mixed-precision Post-Training Quantization framework that generates explainable insights on the cost-effectiveness of various model weight quantization methods for different denoiser operation types and block structures. We leverage these insights to make high-quality mixed-precision quantization decisions for a myriad of diffusion models ranging from foundational U-Nets to state-of-the-art Transformers. As a result, Qua$^2$SeDiMo can construct 3.4-bit, 3.9-bit, 3.65-bit and 3.7-bit weight quantization on PixArt-${\alpha}$, PixArt-${\Sigma}$, Hunyuan-DiT and SDXL, respectively. We further pair our weight-quantization configurations with 6-bit activation quantization and outperform existing approaches in terms of quantitative metrics and generative image quality.
EiG-Search: Generating Edge-Induced Subgraphs for GNN Explanation in Linear Time
May 02, 2024Understanding and explaining the predictions of Graph Neural Networks (GNNs), is crucial for enhancing their safety and trustworthiness. Subgraph-level explanations are gaining attention for their intuitive appeal. However, most existing subgraph-level explainers face efficiency challenges in explaining GNNs due to complex search processes. The key challenge is to find a balance between intuitiveness and efficiency while ensuring transparency. Additionally, these explainers usually induce subgraphs by nodes, which may introduce less-intuitive disconnected nodes in the subgraph-level explanations or omit many important subgraph structures. In this paper, we reveal that inducing subgraph explanations by edges is more comprehensive than other subgraph inducing techniques. We also emphasize the need of determining the subgraph explanation size for each data instance, as different data instances may involve different important substructures. Building upon these considerations, we introduce a training-free approach, named EiG-Search. We employ an efficient linear-time search algorithm over the edge-induced subgraphs, where the edges are ranked by an enhanced gradient-based importance. We conduct extensive experiments on a total of seven datasets, demonstrating its superior performance and efficiency both quantitatively and qualitatively over the leading baselines.
* 19 pages
Building Optimal Neural Architectures using Interpretable Knowledge
Mar 20, 2024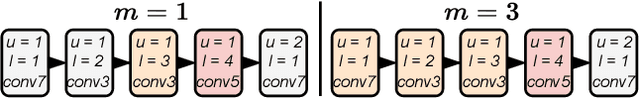

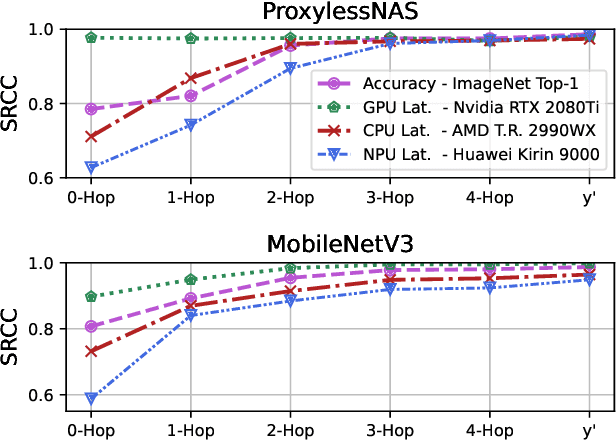

Neural Architecture Search is a costly practice. The fact that a search space can span a vast number of design choices with each architecture evaluation taking nontrivial overhead makes it hard for an algorithm to sufficiently explore candidate networks. In this paper, we propose AutoBuild, a scheme which learns to align the latent embeddings of operations and architecture modules with the ground-truth performance of the architectures they appear in. By doing so, AutoBuild is capable of assigning interpretable importance scores to architecture modules, such as individual operation features and larger macro operation sequences such that high-performance neural networks can be constructed without any need for search. Through experiments performed on state-of-the-art image classification, segmentation, and Stable Diffusion models, we show that by mining a relatively small set of evaluated architectures, AutoBuild can learn to build high-quality architectures directly or help to reduce search space to focus on relevant areas, finding better architectures that outperform both the original labeled ones and ones found by search baselines. Code available at https://github.com/Ascend-Research/AutoBuild
GOAt: Explaining Graph Neural Networks via Graph Output Attribution
Jan 26, 2024Understanding the decision-making process of Graph Neural Networks (GNNs) is crucial to their interpretability. Most existing methods for explaining GNNs typically rely on training auxiliary models, resulting in the explanations remain black-boxed. This paper introduces Graph Output Attribution (GOAt), a novel method to attribute graph outputs to input graph features, creating GNN explanations that are faithful, discriminative, as well as stable across similar samples. By expanding the GNN as a sum of scalar products involving node features, edge features and activation patterns, we propose an efficient analytical method to compute contribution of each node or edge feature to each scalar product and aggregate the contributions from all scalar products in the expansion form to derive the importance of each node and edge. Through extensive experiments on synthetic and real-world data, we show that our method not only outperforms various state-ofthe-art GNN explainers in terms of the commonly used fidelity metric, but also exhibits stronger discriminability, and stability by a remarkable margin.
A General-Purpose Transferable Predictor for Neural Architecture Search
Feb 21, 2023



Understanding and modelling the performance of neural architectures is key to Neural Architecture Search (NAS). Performance predictors have seen widespread use in low-cost NAS and achieve high ranking correlations between predicted and ground truth performance in several NAS benchmarks. However, existing predictors are often designed based on network encodings specific to a predefined search space and are therefore not generalizable to other search spaces or new architecture families. In this paper, we propose a general-purpose neural predictor for NAS that can transfer across search spaces, by representing any given candidate Convolutional Neural Network (CNN) with a Computation Graph (CG) that consists of primitive operators. We further combine our CG network representation with Contrastive Learning (CL) and propose a graph representation learning procedure that leverages the structural information of unlabeled architectures from multiple families to train CG embeddings for our performance predictor. Experimental results on NAS-Bench-101, 201 and 301 demonstrate the efficacy of our scheme as we achieve strong positive Spearman Rank Correlation Coefficient (SRCC) on every search space, outperforming several Zero-Cost Proxies, including Synflow and Jacov, which are also generalizable predictors across search spaces. Moreover, when using our proposed general-purpose predictor in an evolutionary neural architecture search algorithm, we can find high-performance architectures on NAS-Bench-101 and find a MobileNetV3 architecture that attains 79.2% top-1 accuracy on ImageNet.
GENNAPE: Towards Generalized Neural Architecture Performance Estimators
Nov 30, 2022



Predicting neural architecture performance is a challenging task and is crucial to neural architecture design and search. Existing approaches either rely on neural performance predictors which are limited to modeling architectures in a predefined design space involving specific sets of operators and connection rules, and cannot generalize to unseen architectures, or resort to zero-cost proxies which are not always accurate. In this paper, we propose GENNAPE, a Generalized Neural Architecture Performance Estimator, which is pretrained on open neural architecture benchmarks, and aims to generalize to completely unseen architectures through combined innovations in network representation, contrastive pretraining, and fuzzy clustering-based predictor ensemble. Specifically, GENNAPE represents a given neural network as a Computation Graph (CG) of atomic operations which can model an arbitrary architecture. It first learns a graph encoder via Contrastive Learning to encourage network separation by topological features, and then trains multiple predictor heads, which are soft-aggregated according to the fuzzy membership of a neural network. Experiments show that GENNAPE pretrained on NAS-Bench-101 can achieve superior transferability to 5 different public neural network benchmarks, including NAS-Bench-201, NAS-Bench-301, MobileNet and ResNet families under no or minimum fine-tuning. We further introduce 3 challenging newly labelled neural network benchmarks: HiAML, Inception and Two-Path, which can concentrate in narrow accuracy ranges. Extensive experiments show that GENNAPE can correctly discern high-performance architectures in these families. Finally, when paired with a search algorithm, GENNAPE can find architectures that improve accuracy while reducing FLOPs on three families.
AIO-P: Expanding Neural Performance Predictors Beyond Image Classification
Nov 30, 2022Evaluating neural network performance is critical to deep neural network design but a costly procedure. Neural predictors provide an efficient solution by treating architectures as samples and learning to estimate their performance on a given task. However, existing predictors are task-dependent, predominantly estimating neural network performance on image classification benchmarks. They are also search-space dependent; each predictor is designed to make predictions for a specific architecture search space with predefined topologies and set of operations. In this paper, we propose a novel All-in-One Predictor (AIO-P), which aims to pretrain neural predictors on architecture examples from multiple, separate computer vision (CV) task domains and multiple architecture spaces, and then transfer to unseen downstream CV tasks or neural architectures. We describe our proposed techniques for general graph representation, efficient predictor pretraining and knowledge infusion techniques, as well as methods to transfer to downstream tasks/spaces. Extensive experimental results show that AIO-P can achieve Mean Absolute Error (MAE) and Spearman's Rank Correlation (SRCC) below 1% and above 0.5, respectively, on a breadth of target downstream CV tasks with or without fine-tuning, outperforming a number of baselines. Moreover, AIO-P can directly transfer to new architectures not seen during training, accurately rank them and serve as an effective performance estimator when paired with an algorithm designed to preserve performance while reducing FLOPs.