 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIO-P: Expanding Neural Performance Predictors Beyond Image Classification
Nov 30, 2022Evaluating neural network performance is critical to deep neural network design but a costly procedure. Neural predictors provide an efficient solution by treating architectures as samples and learning to estimate their performance on a given task. However, existing predictors are task-dependent, predominantly estimating neural network performance on image classification benchmarks. They are also search-space dependent; each predictor is designed to make predictions for a specific architecture search space with predefined topologies and set of operations. In this paper, we propose a novel All-in-One Predictor (AIO-P), which aims to pretrain neural predictors on architecture examples from multiple, separate computer vision (CV) task domains and multiple architecture spaces, and then transfer to unseen downstream CV tasks or neural architectures. We describe our proposed techniques for general graph representation, efficient predictor pretraining and knowledge infusion techniques, as well as methods to transfer to downstream tasks/spaces. Extensive experimental results show that AIO-P can achieve Mean Absolute Error (MAE) and Spearman's Rank Correlation (SRCC) below 1% and above 0.5, respectively, on a breadth of target downstream CV tasks with or without fine-tuning, outperforming a number of baselines. Moreover, AIO-P can directly transfer to new architectures not seen during training, accurately rank them and serve as an effective performance estimator when paired with an algorithm designed to preserve performance while reducing FLOPs.
A Character-Level Length-Control Algorithm for Non-Autoregressive Sentence Summarization
May 28, 2022
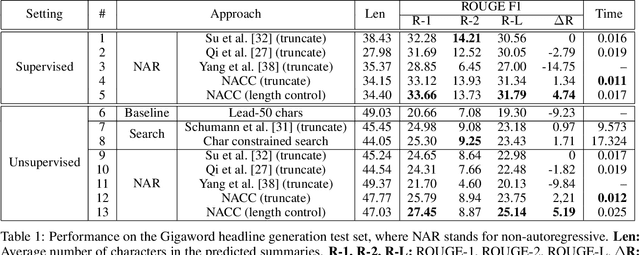
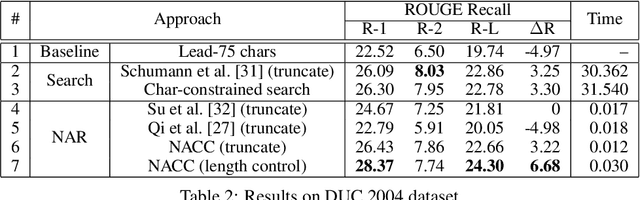

Sentence summarization aims at compressing a long sentence into a short one that keeps the main gist, and has extensive real-world applications such as headline generation. In previous work, researchers have developed various approaches to improve the ROUGE score, which is the main evaluation metric for summarization, whereas controlling the summary length has not drawn much attention. In our work, we address a new problem of explicit character-level length control for summarization, and propose a dynamic programming algorithm based on the Connectionist Temporal Classification (CTC) model. Results show that our approach not only achieves higher ROUGE scores but also yields more complete sentences.
Learning Non-Autoregressive Models from Search for Unsupervised Sentence Summarization
May 28, 2022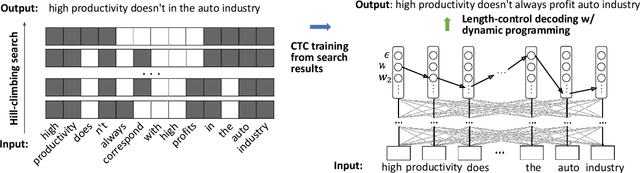
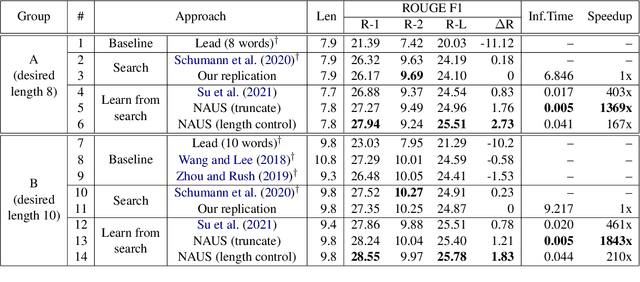

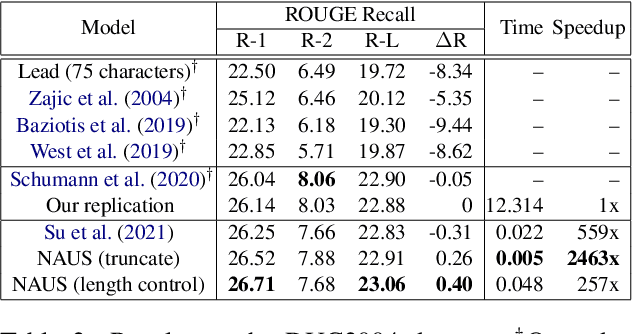
Text summarization aims to generate a short summary for an input text. In this work, we propose a Non-Autoregressive Unsupervised Summarization (NAUS) approach, which does not require parallel data for training. Our NAUS first performs edit-based search towards a heuristically defined score, and generates a summary as pseudo-groundtruth. Then, we train an encoder-only non-autoregressive Transformer based on the search result. We also propose a dynamic programming approach for length-control decoding, which is important for the summarization task. Experiments on two datasets show that NAUS achieves state-of-the-art performance for unsupervised summarization, yet largely improving inference efficiency. Further, our algorithm is able to perform explicit length-transfer summary generation.