 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Graph Explanation to Operator Fusion
Dec 31, 2024



Layer fusion techniques are critical to improving the inference efficiency of deep neural networks (DNN) for deployment. Fusion aims to lower inference costs by reducing data transactions between an accelerator's on-chip buffer and DRAM. This is accomplished by grouped execution of multiple operations like convolution and activations together into single execution units - fusion groups. However, on-chip buffer capacity limits fusion group size and optimizing fusion on whole DNNs requires partitioning into multiple fusion groups. Finding the optimal groups is a complex problem where the presence of invalid solutions hampers traditional search algorithms and demands robust approaches. In this paper we incorporate Explainable AI, specifically Graph Explanation Techniques (GET), into layer fusion. Given an invalid fusion group, we identify the operations most responsible for group invalidity, then use this knowledge to recursively split the original fusion group via a greedy tree-based algorithm to minimize DRAM access. We pair our scheme with common algorithms and optimize DNNs on two types of layer fusion: Line-Buffer Depth First (LBDF) and Branch Requirement Reduction (BRR). Experiments demonstrate the efficacy of our scheme on several popular and classical convolutional neural networks like ResNets and MobileNets. Our scheme achieves over 20% DRAM Access reduction on EfficientNet-B3.
Qua$^2$SeDiMo: Quantifiable Quantization Sensitivity of Diffusion Models
Dec 19, 2024
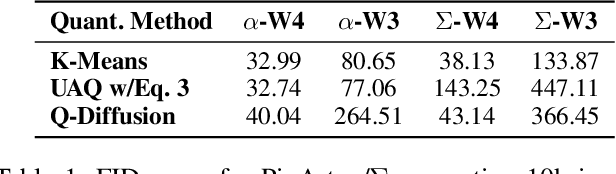

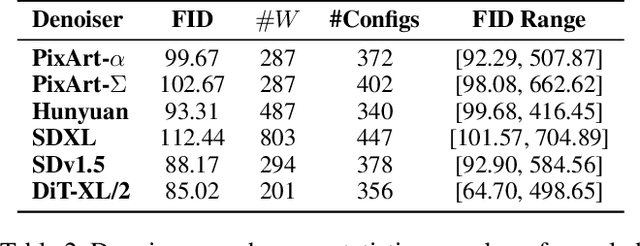
Diffusion Models (DM) have democratized AI image generation through an iterative denoising process. Quantization is a major technique to alleviate the inference cost and reduce the size of DM denoiser networks. However, as denoisers evolve from variants of convolutional U-Nets toward newer Transformer architectures, it is of growing importance to understand the quantization sensitivity of different weight layers, operations and architecture types to performance. In this work, we address this challenge with Qua$^2$SeDiMo, a mixed-precision Post-Training Quantization framework that generates explainable insights on the cost-effectiveness of various model weight quantization methods for different denoiser operation types and block structures. We leverage these insights to make high-quality mixed-precision quantization decisions for a myriad of diffusion models ranging from foundational U-Nets to state-of-the-art Transformers. As a result, Qua$^2$SeDiMo can construct 3.4-bit, 3.9-bit, 3.65-bit and 3.7-bit weight quantization on PixArt-${\alpha}$, PixArt-${\Sigma}$, Hunyuan-DiT and SDXL, respectively. We further pair our weight-quantization configurations with 6-bit activation quantization and outperform existing approaches in terms of quantitative metrics and generative image quality.
PixelMan: Consistent Object Editing with Diffusion Models via Pixel Manipulation and Generation
Dec 18, 2024



Recent research explores the potential of Diffusion Models (DMs) for consistent object editing, which aims to modify object position, size, and composition, etc., while preserving the consistency of objects and background without changing their texture and attributes. Current inference-time methods often rely on DDIM inversion, which inherently compromises efficiency and the achievable consistency of edited images. Recent methods also utilize energy guidance which iteratively updates the predicted noise and can drive the latents away from the original image, resulting in distortions. In this paper, we propose PixelMan, an inversion-free and training-free method for achieving consistent object editing via Pixel Manipulation and generation, where we directly create a duplicate copy of the source object at target location in the pixel space, and introduce an efficient sampling approach to iteratively harmonize the manipulated object into the target location and inpaint its original location, while ensuring image consistency by anchoring the edited image to be generated to the pixel-manipulated image as well as by introducing various consistency-preserving optimization techniques during inference. Experimental evaluations based on benchmark datasets as well as extensive visual comparisons show that in as few as 16 inference steps, PixelMan outperforms a range of state-of-the-art training-based and training-free methods (usually requiring 50 steps) on multiple consistent object editing tasks.
Learning Truncated Causal History Model for Video Restoration
Oct 15, 2024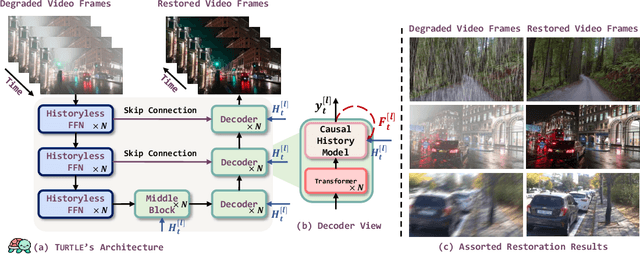
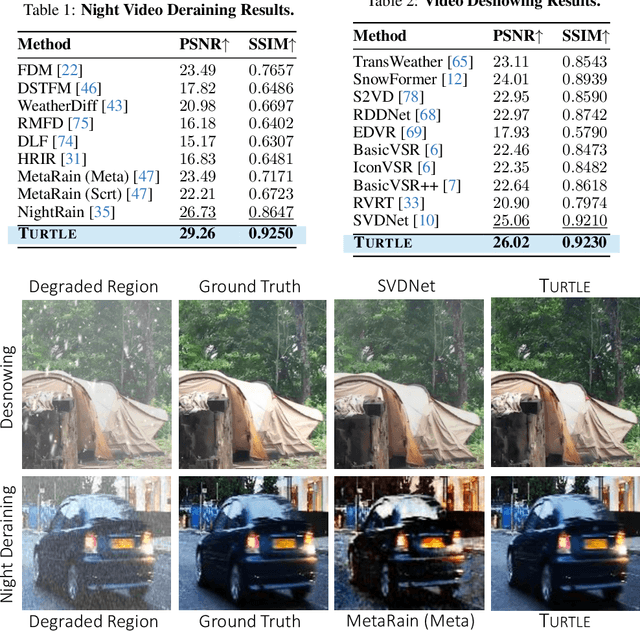
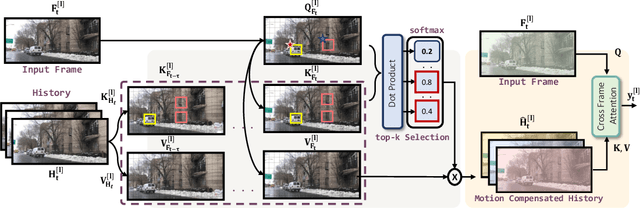

One key challenge to video restoration is to model the transition dynamics of video frames governed by motion. In this work, we propose TURTLE to learn the truncated causal history model for efficient and high-performing video restoration. Unlike traditional methods that process a range of contextual frames in parallel, TURTLE enhances efficiency by storing and summarizing a truncated history of the input frame latent representation into an evolving historical state. This is achieved through a sophisticated similarity-based retrieval mechanism that implicitly accounts for inter-frame motion and alignment. The causal design in TURTLE enables recurrence in inference through state-memorized historical features while allowing parallel training by sampling truncated video clips. We report new state-of-the-art results on a multitude of video restoration benchmark tasks, including video desnowing, nighttime video deraining, video raindrops and rain streak removal, video super-resolution, real-world and synthetic video deblurring, and blind video denoising while reducing the computational cost compared to existing best contextual methods on all these tasks.
FRAP: Faithful and Realistic Text-to-Image Generation with Adaptive Prompt Weighting
Aug 21, 2024



Text-to-image (T2I) diffusion models have demonstrated impressive capabilities in generating high-quality images given a text prompt. However, ensuring the prompt-image alignment remains a considerable challenge, i.e., generating images that faithfully align with the prompt's semantics. Recent works attempt to improve the faithfulness by optimizing the latent code, which potentially could cause the latent code to go out-of-distribution and thus produce unrealistic images. In this paper, we propose FRAP, a simple, yet effective approach based on adaptively adjusting the per-token prompt weights to improve prompt-image alignment and authenticity of the generated images. We design an online algorithm to adaptively update each token's weight coefficient, which is achieved by minimizing a unified objective function that encourages object presence and the binding of object-modifier pairs. Through extensive evaluations, we show FRAP generates images with significantly higher prompt-image alignment to prompts from complex datasets, while having a lower average latency compared to recent latent code optimization methods, e.g., 4 seconds faster than D&B on the COCO-Subject dataset. Furthermore, through visual comparisons and evaluation on the CLIP-IQA-Real metric, we show that FRAP not only improves prompt-image alignment but also generates more authentic images with realistic appearances. We also explore combining FRAP with prompt rewriting LLM to recover their degraded prompt-image alignment, where we observe improvements in both prompt-image alignment and image quality.
Achieving Complex Image Edits via Function Aggregation with Diffusion Models
Aug 16, 2024
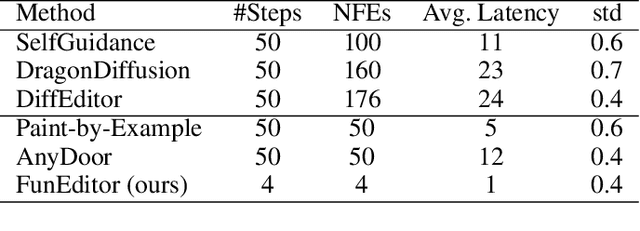
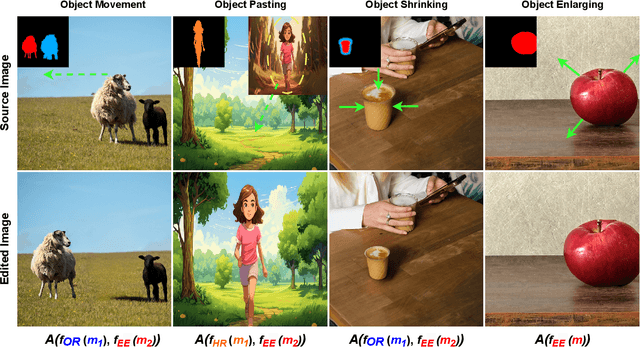

Diffusion models have demonstrated strong performance in generative tasks, making them ideal candidates for image editing. Recent studies highlight their ability to apply desired edits effectively by following textual instructions, yet two key challenges persist. First, these models struggle to apply multiple edits simultaneously, resulting in computational inefficiencies due to their reliance on sequential processing. Second, relying on textual prompts to determine the editing region can lead to unintended alterations in other parts of the image. In this work, we introduce FunEditor, an efficient diffusion model designed to learn atomic editing functions and perform complex edits by aggregating simpler functions. This approach enables complex editing tasks, such as object movement, by aggregating multiple functions and applying them simultaneously to specific areas. FunEditor is 5 to 24 times faster inference than existing methods on complex tasks like object movement. Our experiments demonstrate that FunEditor significantly outperforms recent baselines, including both inference-time optimization methods and fine-tuned models, across various metrics, such as image quality assessment (IQA) and object-background consistency.
Incorporating Explanations into Human-Machine Interfaces for Trust and Situation Awareness in Autonomous Vehicles
Apr 10, 2024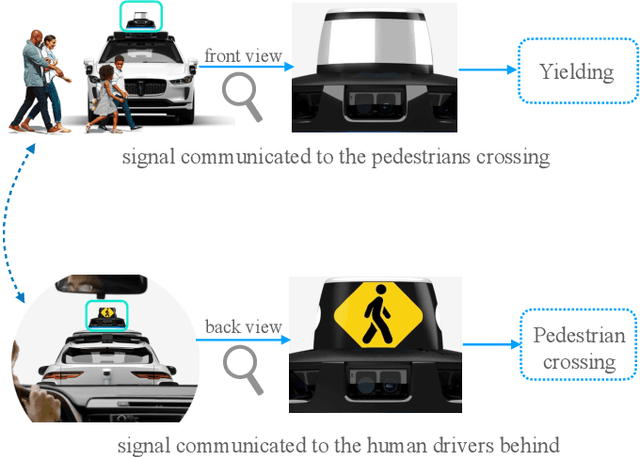
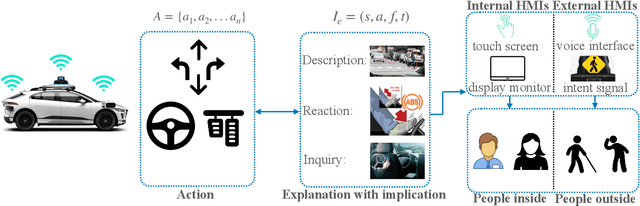


Autonomous vehicles often make complex decisions via machine learning-based predictive models applied to collected sensor data. While this combination of methods provides a foundation for real-time actions, self-driving behavior primarily remains opaque to end users. In this sense, explainability of real-time decisions is a crucial and natural requirement for building trust in autonomous vehicles. Moreover, as autonomous vehicles still cause serious traffic accidents for various reasons, timely conveyance of upcoming hazards to road users can help improve scene understanding and prevent potential risks. Hence, there is also a need to supply autonomous vehicles with user-friendly interfaces for effective human-machine teaming. Motivated by this problem, we study the role of explainable AI and human-machine interface jointly in building trust in vehicle autonomy. We first present a broad context of the explanatory human-machine systems with the "3W1H" (what, whom, when, how) approach. Based on these findings, we present a situation awareness framework for calibrating users' trust in self-driving behavior. Finally, we perform an experiment on our framework, conduct a user study on it, and validate the empirical findings with hypothesis testing.
Building Optimal Neural Architectures using Interpretable Knowledge
Mar 20, 2024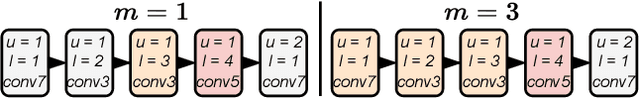

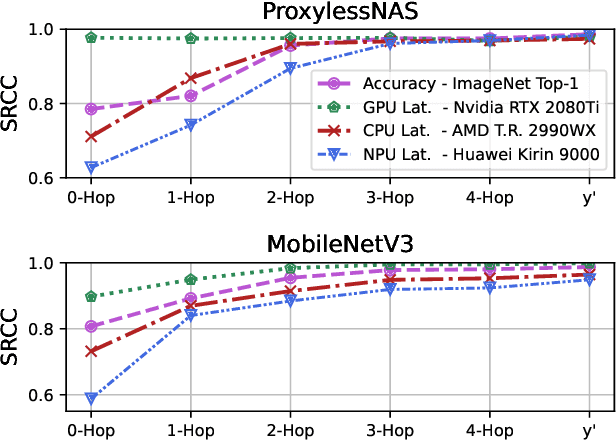

Neural Architecture Search is a costly practice. The fact that a search space can span a vast number of design choices with each architecture evaluation taking nontrivial overhead makes it hard for an algorithm to sufficiently explore candidate networks. In this paper, we propose AutoBuild, a scheme which learns to align the latent embeddings of operations and architecture modules with the ground-truth performance of the architectures they appear in. By doing so, AutoBuild is capable of assigning interpretable importance scores to architecture modules, such as individual operation features and larger macro operation sequences such that high-performance neural networks can be constructed without any need for search. Through experiments performed on state-of-the-art image classification, segmentation, and Stable Diffusion models, we show that by mining a relatively small set of evaluated architectures, AutoBuild can learn to build high-quality architectures directly or help to reduce search space to focus on relevant areas, finding better architectures that outperform both the original labeled ones and ones found by search baselines. Code available at https://github.com/Ascend-Research/AutoBuild
Safety Implications of Explainable Artificial Intelligence in End-to-End Autonomous Driving
Mar 18, 2024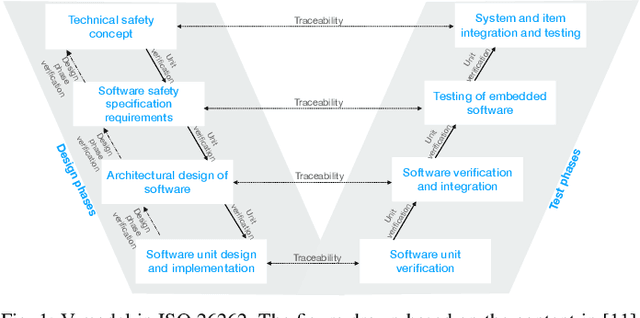



The end-to-end learning pipeline is gradually creating a paradigm shift in the ongoing development of highly autonomous vehicles, largely due to advances in deep learning, the availability of large-scale training datasets, and improvements in integrated sensor devices. However, a lack of interpretability in real-time decisions with contemporary learning methods impedes user trust and attenuates the widespread deployment and commercialization of such vehicles. Moreover, the issue is exacerbated when these cars are involved in or cause traffic accidents. Such drawback raises serious safety concerns from societal and legal perspectives. Consequently, explainability in end-to-end autonomous driving is essential to enable the safety of vehicular automation. However, the safety and explainability aspects of autonomous driving have generally been investigated disjointly by researchers in today's state of the art. In this paper, we aim to bridge the gaps between these topics and seek to answer the following research question: When and how can explanations improve safety of autonomous driving? In this regard, we first revisit established safety and state-of-the-art explainability techniques in autonomous driving. Furthermore, we present three critical case studies and show the pivotal role of explanations in enhancing self-driving safety. Finally, we describe our empirical investigation and reveal potential value, limitations, and caveats with practical explainable AI methods on their role of assuring safety and transparency for vehicle autonomy.
CascadedGaze: Efficiency in Global Context Extraction for Image Restoration
Jan 26, 2024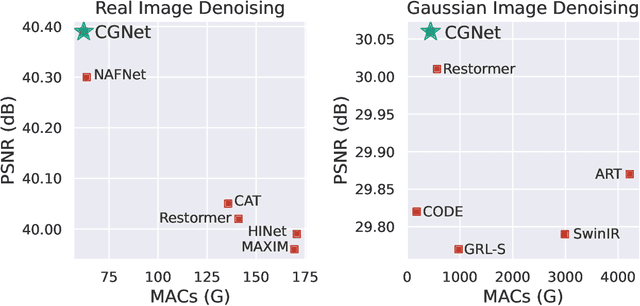
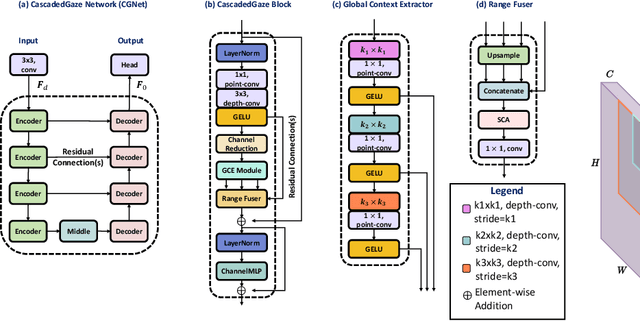
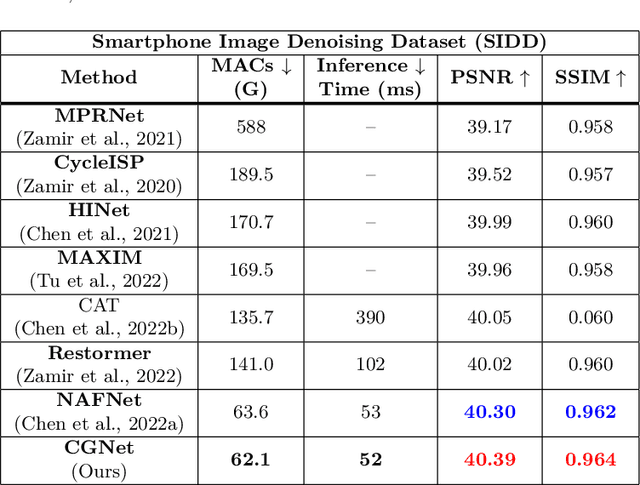
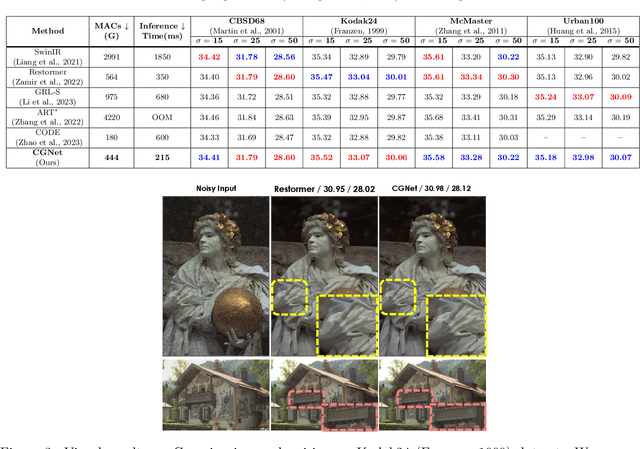
Image restoration tasks traditionally rely on convolutional neural networks. However, given the local nature of the convolutional operator, they struggle to capture global information. The promise of attention mechanisms in Transformers is to circumvent this problem, but it comes at the cost of intensive computational overhead. Many recent studies in image restoration have focused on solving the challenge of balancing performance and computational cost via Transformer variants. In this paper, we present CascadedGaze Network (CGNet), an encoder-decoder architecture that employs Global Context Extractor (GCE), a novel and efficient way to capture global information for image restoration. The GCE module leverages small kernels across convolutional layers to learn global dependencies, without requiring self-attention. Extensive experimental results show that our approach outperforms a range of state-of-the-art methods on denoising benchmark datasets including both real image denoising and synthetic image denoising, as well as on image deblurring task, while being more computationally efficient.