 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Complex Image Edits via Function Aggregation with Diffusion Models
Paper and Code
Aug 16, 2024
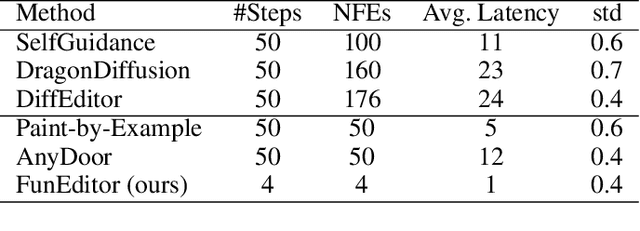
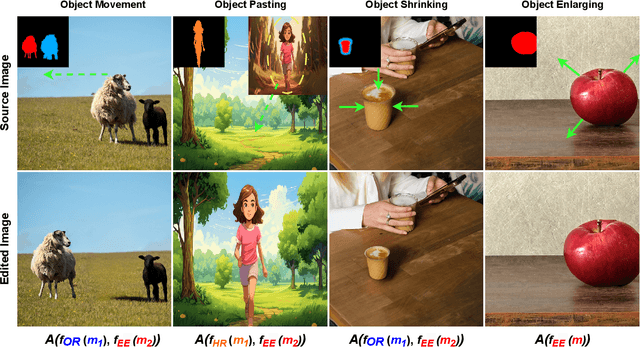

Diffusion models have demonstrated strong performance in generative tasks, making them ideal candidates for image editing. Recent studies highlight their ability to apply desired edits effectively by following textual instructions, yet two key challenges persist. First, these models struggle to apply multiple edits simultaneously, resulting in computational inefficiencies due to their reliance on sequential processing. Second, relying on textual prompts to determine the editing region can lead to unintended alterations in other parts of the image. In this work, we introduce FunEditor, an efficient diffusion model designed to learn atomic editing functions and perform complex edits by aggregating simpler functions. This approach enables complex editing tasks, such as object movement, by aggregating multiple functions and applying them simultaneously to specific areas. FunEditor is 5 to 24 times faster inference than existing methods on complex tasks like object movement. Our experiments demonstrate that FunEditor significantly outperforms recent baselines, including both inference-time optimization methods and fine-tuned models, across various metrics, such as image quality assessment (IQA) and object-background consistency.