 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixelMan: Consistent Object Editing with Diffusion Models via Pixel Manipulation and Generation
Dec 18, 2024



Recent research explores the potential of Diffusion Models (DMs) for consistent object editing, which aims to modify object position, size, and composition, etc., while preserving the consistency of objects and background without changing their texture and attributes. Current inference-time methods often rely on DDIM inversion, which inherently compromises efficiency and the achievable consistency of edited images. Recent methods also utilize energy guidance which iteratively updates the predicted noise and can drive the latents away from the original image, resulting in distortions. In this paper, we propose PixelMan, an inversion-free and training-free method for achieving consistent object editing via Pixel Manipulation and generation, where we directly create a duplicate copy of the source object at target location in the pixel space, and introduce an efficient sampling approach to iteratively harmonize the manipulated object into the target location and inpaint its original location, while ensuring image consistency by anchoring the edited image to be generated to the pixel-manipulated image as well as by introducing various consistency-preserving optimization techniques during inference. Experimental evaluations based on benchmark datasets as well as extensive visual comparisons show that in as few as 16 inference steps, PixelMan outperforms a range of state-of-the-art training-based and training-free methods (usually requiring 50 steps) on multiple consistent object editing tasks.
Achieving Complex Image Edits via Function Aggregation with Diffusion Models
Aug 16, 2024
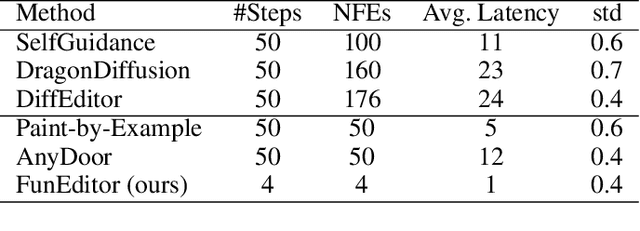
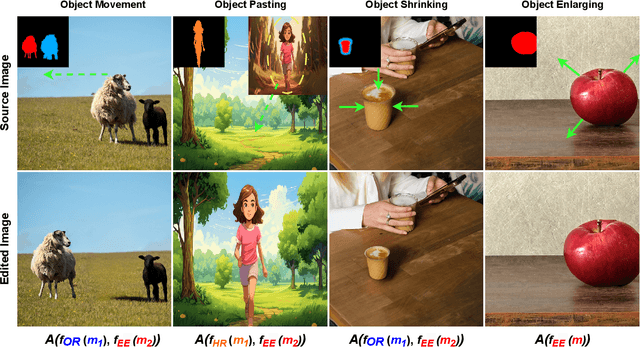

Diffusion models have demonstrated strong performance in generative tasks, making them ideal candidates for image editing. Recent studies highlight their ability to apply desired edits effectively by following textual instructions, yet two key challenges persist. First, these models struggle to apply multiple edits simultaneously, resulting in computational inefficiencies due to their reliance on sequential processing. Second, relying on textual prompts to determine the editing region can lead to unintended alterations in other parts of the image. In this work, we introduce FunEditor, an efficient diffusion model designed to learn atomic editing functions and perform complex edits by aggregating simpler functions. This approach enables complex editing tasks, such as object movement, by aggregating multiple functions and applying them simultaneously to specific areas. FunEditor is 5 to 24 times faster inference than existing methods on complex tasks like object movement. Our experiments demonstrate that FunEditor significantly outperforms recent baselines, including both inference-time optimization methods and fine-tuned models, across various metrics, such as image quality assessment (IQA) and object-background consistency.
Performance Prediction for Multi-hop Questions
Aug 12, 2023



We study the problem of Query Performance Prediction (QPP) for open-domain multi-hop Question Answering (QA), where the task is to estimate the difficulty of evaluating a multi-hop question over a corpus. Despite the extensive research on predicting the performance of ad-hoc and QA retrieval models, there has been a lack of study on the estimation of the difficulty of multi-hop questions. The problem is challenging due to the multi-step nature of the retrieval process, potential dependency of the steps and the reasoning involved. To tackle this challenge, we propose multHP, a novel pre-retrieval method for predicting the performance of open-domain multi-hop questions. Our extensive evaluation on the largest multi-hop QA dataset using several modern QA systems shows that the proposed model is a strong predictor of the performance, outperforming traditional single-hop QPP models. Additionally, we demonstrate that our approach can be effectively used to optimize the parameters of QA systems, such as the number of documents to be retrieved, resulting in improved overall retrieval performance.