 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Complex Image Edits via Function Aggregation with Diffusion Models
Aug 16, 2024
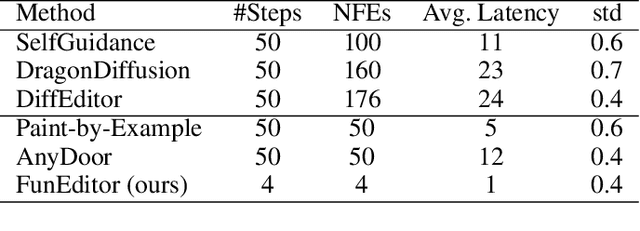
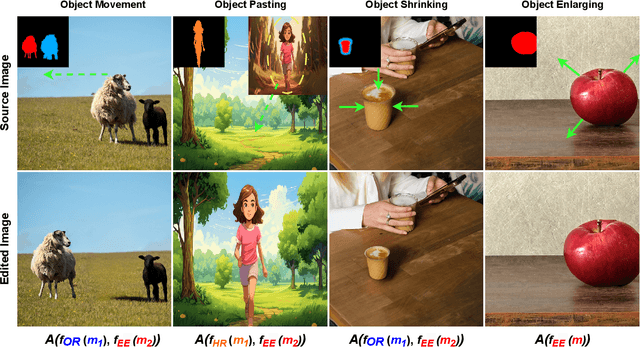

Diffusion models have demonstrated strong performance in generative tasks, making them ideal candidates for image editing. Recent studies highlight their ability to apply desired edits effectively by following textual instructions, yet two key challenges persist. First, these models struggle to apply multiple edits simultaneously, resulting in computational inefficiencies due to their reliance on sequential processing. Second, relying on textual prompts to determine the editing region can lead to unintended alterations in other parts of the image. In this work, we introduce FunEditor, an efficient diffusion model designed to learn atomic editing functions and perform complex edits by aggregating simpler functions. This approach enables complex editing tasks, such as object movement, by aggregating multiple functions and applying them simultaneously to specific areas. FunEditor is 5 to 24 times faster inference than existing methods on complex tasks like object movement. Our experiments demonstrate that FunEditor significantly outperforms recent baselines, including both inference-time optimization methods and fine-tuned models, across various metrics, such as image quality assessment (IQA) and object-background consistency.
Building Optimal Neural Architectures using Interpretable Knowledge
Mar 20, 2024

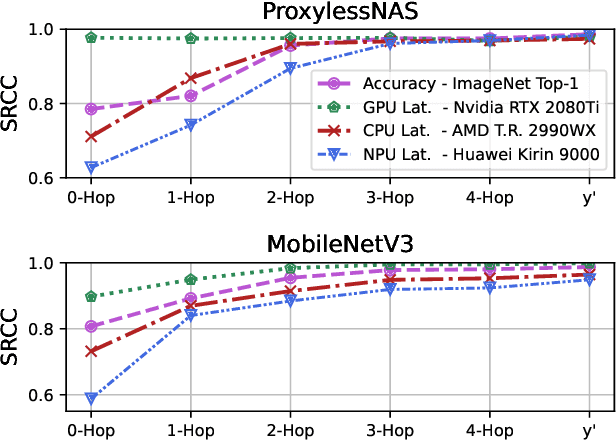

Neural Architecture Search is a costly practice. The fact that a search space can span a vast number of design choices with each architecture evaluation taking nontrivial overhead makes it hard for an algorithm to sufficiently explore candidate networks. In this paper, we propose AutoBuild, a scheme which learns to align the latent embeddings of operations and architecture modules with the ground-truth performance of the architectures they appear in. By doing so, AutoBuild is capable of assigning interpretable importance scores to architecture modules, such as individual operation features and larger macro operation sequences such that high-performance neural networks can be constructed without any need for search. Through experiments performed on state-of-the-art image classification, segmentation, and Stable Diffusion models, we show that by mining a relatively small set of evaluated architectures, AutoBuild can learn to build high-quality architectures directly or help to reduce search space to focus on relevant areas, finding better architectures that outperform both the original labeled ones and ones found by search baselines. Code available at https://github.com/Ascend-Research/AutoBuild
CascadedGaze: Efficiency in Global Context Extraction for Image Restoration
Jan 26, 2024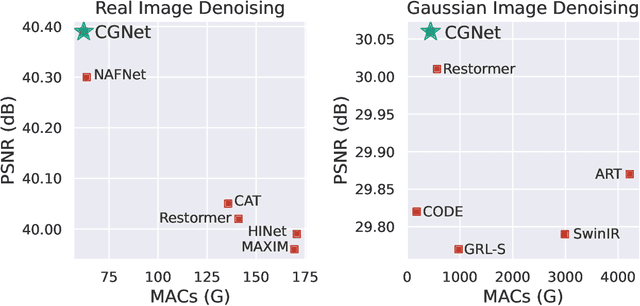
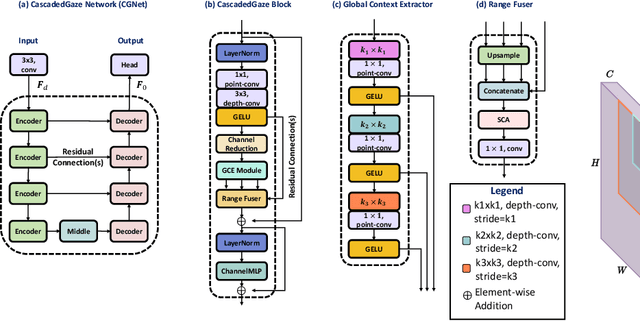
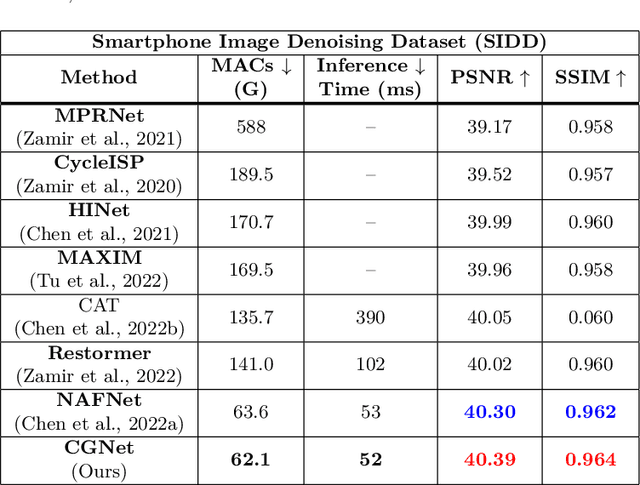
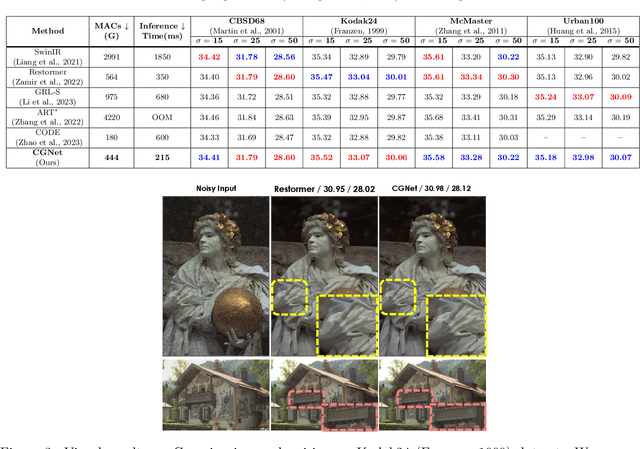
Image restoration tasks traditionally rely on convolutional neural networks. However, given the local nature of the convolutional operator, they struggle to capture global information. The promise of attention mechanisms in Transformers is to circumvent this problem, but it comes at the cost of intensive computational overhead. Many recent studies in image restoration have focused on solving the challenge of balancing performance and computational cost via Transformer variants. In this paper, we present CascadedGaze Network (CGNet), an encoder-decoder architecture that employs Global Context Extractor (GCE), a novel and efficient way to capture global information for image restoration. The GCE module leverages small kernels across convolutional layers to learn global dependencies, without requiring self-attention. Extensive experimental results show that our approach outperforms a range of state-of-the-art methods on denoising benchmark datasets including both real image denoising and synthetic image denoising, as well as on image deblurring task, while being more computationally efficient.