 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Execute Graph Algorithms Exactly with Graph Neural Networks
Jan 30, 2026Understanding what graph neural networks can learn, especially their ability to learn to execute algorithms, remains a central theoretical challenge. In this work, we prove exact learnability results for graph algorithms under bounded-degree and finite-precision constraints. Our approach follows a two-step process. First, we train an ensemble of multi-layer perceptrons (MLPs) to execute the local instructions of a single node. Second, during inference, we use the trained MLP ensemble as the update function within a graph neural network (GNN). Leveraging Neural Tangent Kernel (NTK) theory, we show that local instructions can be learned from a small training set, enabling the complete graph algorithm to be executed during inference without error and with high probability. To illustrate the learning power of our setting, we establish a rigorous learnability result for the LOCAL model of distributed computation. We further demonstrate positive learnability results for widely studied algorithms such as message flooding, breadth-first and depth-first search, and Bellman-Ford.
Applying Graph Explanation to Operator Fusion
Dec 31, 2024



Layer fusion techniques are critical to improving the inference efficiency of deep neural networks (DNN) for deployment. Fusion aims to lower inference costs by reducing data transactions between an accelerator's on-chip buffer and DRAM. This is accomplished by grouped execution of multiple operations like convolution and activations together into single execution units - fusion groups. However, on-chip buffer capacity limits fusion group size and optimizing fusion on whole DNNs requires partitioning into multiple fusion groups. Finding the optimal groups is a complex problem where the presence of invalid solutions hampers traditional search algorithms and demands robust approaches. In this paper we incorporate Explainable AI, specifically Graph Explanation Techniques (GET), into layer fusion. Given an invalid fusion group, we identify the operations most responsible for group invalidity, then use this knowledge to recursively split the original fusion group via a greedy tree-based algorithm to minimize DRAM access. We pair our scheme with common algorithms and optimize DNNs on two types of layer fusion: Line-Buffer Depth First (LBDF) and Branch Requirement Reduction (BRR). Experiments demonstrate the efficacy of our scheme on several popular and classical convolutional neural networks like ResNets and MobileNets. Our scheme achieves over 20% DRAM Access reduction on EfficientNet-B3.
LVLM-COUNT: Enhancing the Counting Ability of Large Vision-Language Models
Dec 01, 2024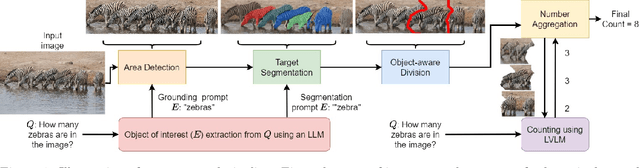
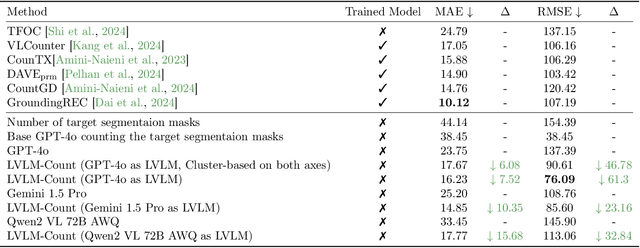
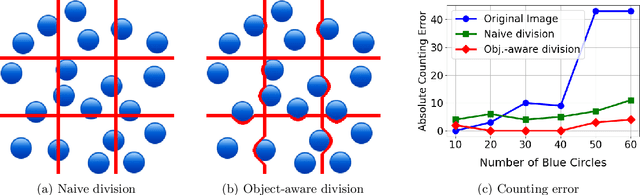
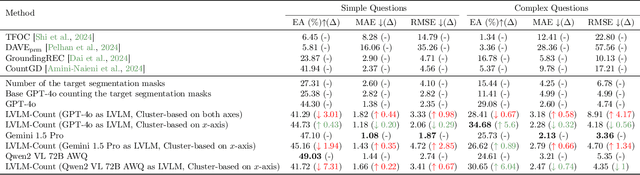
Counting is a fundamental skill for various visual tasks in real-life applications, requiring both object recognition and robust counting capabilities. Despite their advanced visual perception, large vision-language models (LVLMs) struggle with counting tasks, especially when the number of objects exceeds those commonly encountered during training. We enhance LVLMs' counting abilities using a divide-and-conquer approach, breaking counting problems into sub-counting tasks. Unlike prior methods, which do not generalize well to counting datasets on which they have not been trained, our method performs well on new datasets without any additional training or fine-tuning. We demonstrate that our approach enhances counting capabilities across various datasets and benchmarks.
Reparameterization through Spatial Gradient Scaling
Mar 07, 2023Reparameterization aims to improve the generalization of deep neural networks by transforming convolutional layers into equivalent multi-branched structures during training. However, there exists a gap in understanding how reparameterization may change and benefit the learning process of neural networks. In this paper, we present a novel spatial gradient scaling method to redistribute learning focus among weights in convolutional networks. We prove that spatial gradient scaling achieves the same learning dynamics as a branched reparameterization yet without introducing structural changes into the network. We further propose an analytical approach that dynamically learns scalings for each convolutional layer based on the spatial characteristics of its input feature map gauged by mutual information. Experiments on CIFAR-10, CIFAR-100, and ImageNet show that without searching for reparameterized structures, our proposed scaling method outperforms the state-of-the-art reparameterization strategies at a lower computational cost.