 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving LLM's Attachment to External Knowledge In Dialogue Generation Tasks Through Entity Anonymization
Nov 14, 2025



Knowledge graph-based dialogue generation (KG-DG) is a challenging task requiring models to effectively incorporate external knowledge into conversational responses. While large language models (LLMs) have achieved impressive results across various NLP tasks, their ability to utilize external knowledge in KG-DG remains under-explored. We observe that LLMs often rely on internal knowledge, leading to detachment from provided knowledge graphs, even when they are given a flawlessly retrieved knowledge graph. First, we introduce LLM-KAT, an evaluation procedure for measuring knowledge attachment in generated responses. Second, we propose a simple yet effective entity anonymization technique to encourage LLMs to better leverage external knowledge. Experiments on the OpenDialKG dataset demonstrate that our approach improves LLMs' attachment on external knowledge.
Learning second-order TVD flux limiters using differentiable solvers
Mar 11, 2025



This paper presents a data-driven framework for learning optimal second-order total variation diminishing (TVD) flux limiters via differentiable simulations. In our fully differentiable finite volume solvers, the limiter functions are replaced by neural networks. By representing the limiter as a pointwise convex linear combination of the Minmod and Superbee limiters, we enforce both second-order accuracy and TVD constraints at all stages of training. Our approach leverages gradient-based optimization through automatic differentiation, allowing a direct backpropagation of errors from numerical solutions to the limiter parameters. We demonstrate the effectiveness of this method on various hyperbolic conservation laws, including the linear advection equation, the Burgers' equation, and the one-dimensional Euler equations. Remarkably, a limiter trained solely on linear advection exhibits strong generalizability, surpassing the accuracy of most classical flux limiters across a range of problems with shocks and discontinuities. The learned flux limiters can be readily integrated into existing computational fluid dynamics codes, and the proposed methodology also offers a flexible pathway to systematically develop and optimize flux limiters for complex flow problems.
A Decoding Algorithm for Length-Control Summarization Based on Directed Acyclic Transformers
Feb 06, 2025Length-control summarization aims to condense long texts into a short one within a certain length limit. Previous approaches often use autoregressive (AR) models and treat the length requirement as a soft constraint, which may not always be satisfied. In this study, we propose a novel length-control decoding algorithm based on the Directed Acyclic Transformer (DAT). Our approach allows for multiple plausible sequence fragments and predicts a \emph{path} to connect them. In addition, we propose a Sequence Maximum a Posteriori (SeqMAP) decoding algorithm that marginalizes different possible paths and finds the most probable summary satisfying the length budget. Our algorithm is based on beam search, which further facilitates a reranker for performance improvement. Experimental results on the Gigaword and DUC2004 datasets demonstrate our state-of-the-art performance for length-control summarization.
Multilingual Non-Autoregressive Machine Translation without Knowledge Distillation
Feb 06, 2025



Multilingual neural machine translation (MNMT) aims at using one single model for multiple translation directions. Recent work applies non-autoregressive Transformers to improve the efficiency of MNMT, but requires expensive knowledge distillation (KD) processes. To this end, we propose an M-DAT approach to non-autoregressive multilingual machine translation. Our system leverages the recent advance of the directed acyclic Transformer (DAT), which does not require KD. We further propose a pivot back-translation (PivotBT) approach to improve the generalization to unseen translation directions. Experiments show that our M-DAT achieves state-of-the-art performance in non-autoregressive MNMT.
OTTAWA: Optimal TransporT Adaptive Word Aligner for Hallucination and Omission Translation Errors Detection
Jun 04, 2024Recently, there has been considerable attention on detecting hallucinations and omissions in Machine Translation (MT) systems. The two dominant approaches to tackle this task involve analyzing the MT system's internal states or relying on the output of external tools, such as sentence similarity or MT quality estimators. In this work, we introduce OTTAWA, a novel Optimal Transport (OT)-based word aligner specifically designed to enhance the detection of hallucinations and omissions in MT systems. Our approach explicitly models the missing alignments by introducing a "null" vector, for which we propose a novel one-side constrained OT setting to allow an adaptive null alignment. Our approach yields competitive results compared to state-of-the-art methods across 18 language pairs on the HalOmi benchmark. In addition, it shows promising features, such as the ability to distinguish between both error types and perform word-level detection without accessing the MT system's internal states.
Enhancing Argument Summarization: Prioritizing Exhaustiveness in Key Point Generation and Introducing an Automatic Coverage Evaluation Metric
Apr 17, 2024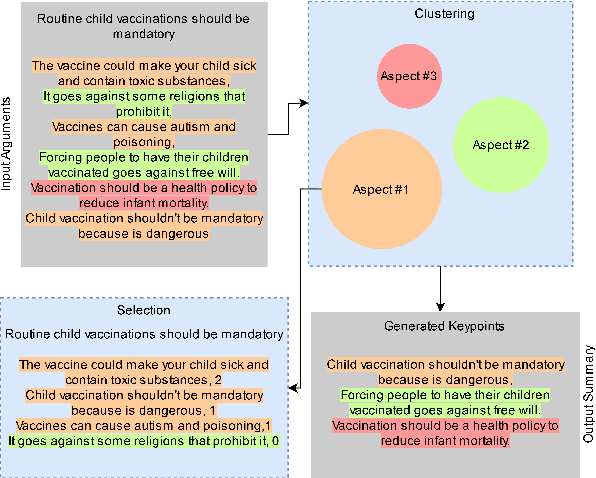
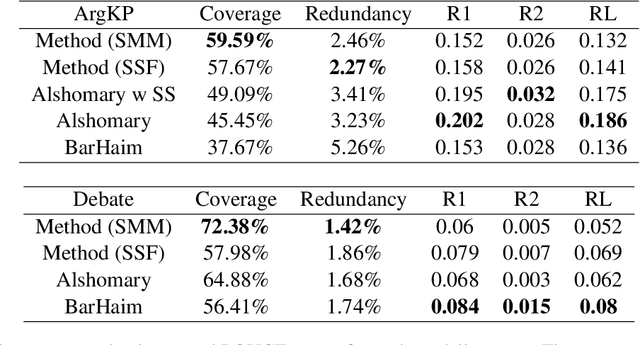
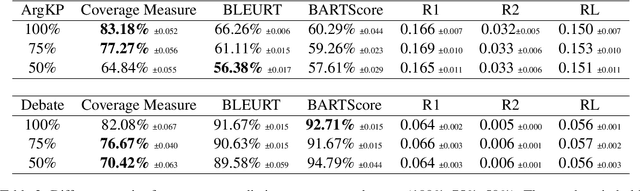

The proliferation of social media platforms has given rise to the amount of online debates and arguments. Consequently, the need for automatic summarization methods for such debates is imperative, however this area of summarization is rather understudied. The Key Point Analysis (KPA) task formulates argument summarization as representing the summary of a large collection of arguments in the form of concise sentences in bullet-style format, called key points. A sub-task of KPA, called Key Point Generation (KPG), focuses on generating these key points given the arguments. This paper introduces a novel extractive approach for key point generation, that outperforms previous state-of-the-art methods for the task. Our method utilizes an extractive clustering based approach that offers concise, high quality generated key points with higher coverage of reference summaries, and less redundant outputs. In addition, we show that the existing evaluation metrics for summarization such as ROUGE are incapable of differentiating between generated key points of different qualities. To this end, we propose a new evaluation metric for assessing the generated key points by their coverage. Our code can be accessed online.
EBBS: An Ensemble with Bi-Level Beam Search for Zero-Shot Machine Translation
Feb 29, 2024
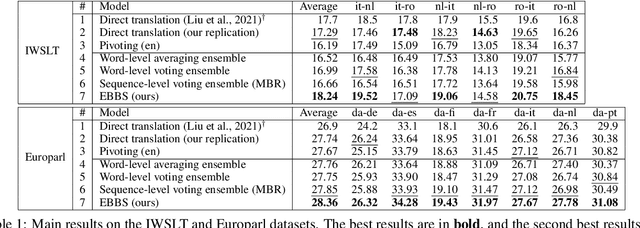

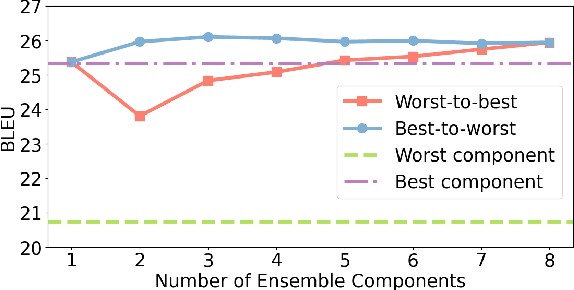
The ability of zero-shot translation emerges when we train a multilingual model with certain translation directions; the model can then directly translate in unseen directions. Alternatively, zero-shot translation can be accomplished by pivoting through a third language (e.g., English). In our work, we observe that both direct and pivot translations are noisy and achieve less satisfactory performance. We propose EBBS, an ensemble method with a novel bi-level beam search algorithm, where each ensemble component explores its own prediction step by step at the lower level but they are synchronized by a "soft voting" mechanism at the upper level. Results on two popular multilingual translation datasets show that EBBS consistently outperforms direct and pivot translations as well as existing ensemble techniques. Further, we can distill the ensemble's knowledge back to the multilingual model to improve inference efficiency; profoundly, our EBBS-based distillation does not sacrifice, or even improves, the translation quality.
Learning Non-Autoregressive Models from Search for Unsupervised Sentence Summarization
May 28, 2022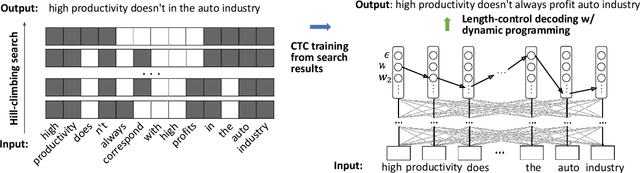
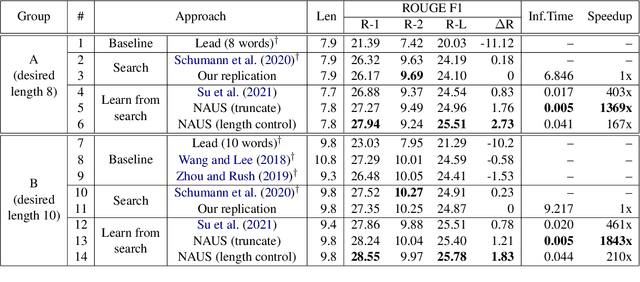

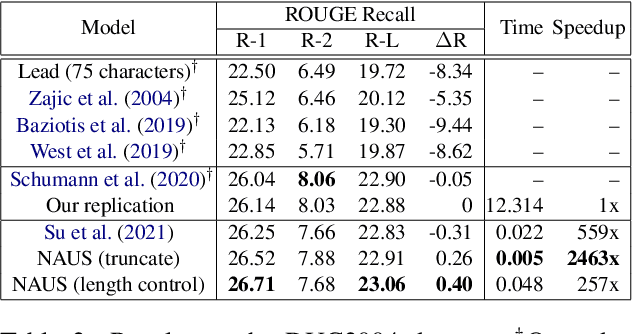
Text summarization aims to generate a short summary for an input text. In this work, we propose a Non-Autoregressive Unsupervised Summarization (NAUS) approach, which does not require parallel data for training. Our NAUS first performs edit-based search towards a heuristically defined score, and generates a summary as pseudo-groundtruth. Then, we train an encoder-only non-autoregressive Transformer based on the search result. We also propose a dynamic programming approach for length-control decoding, which is important for the summarization task. Experiments on two datasets show that NAUS achieves state-of-the-art performance for unsupervised summarization, yet largely improving inference efficiency. Further, our algorithm is able to perform explicit length-transfer summary generation.
Non-Autoregressive Translation with Layer-Wise Prediction and Deep Supervision
Oct 14, 2021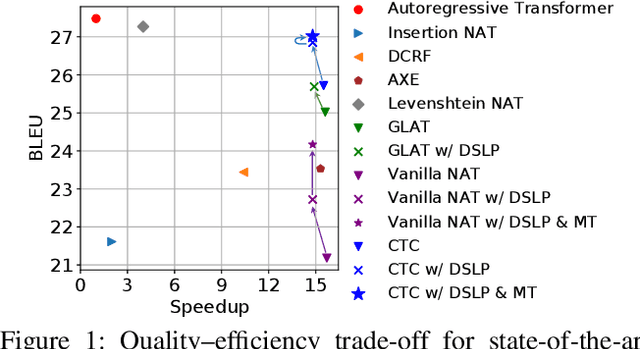
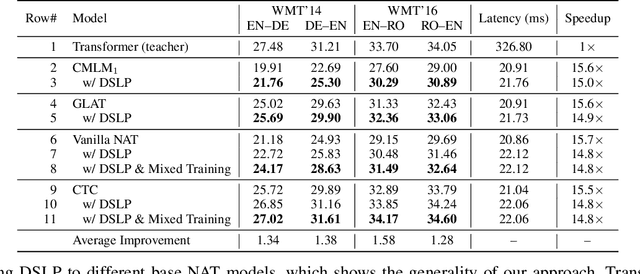
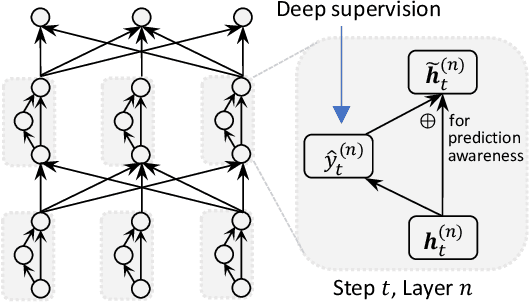
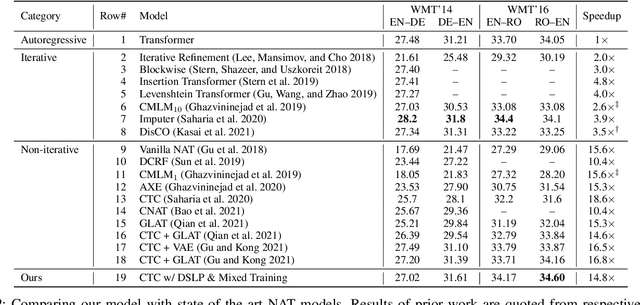
How do we perform efficient inference while retaining high translation quality? Existing neural machine translation models, such as Transformer, achieve high performance, but they decode words one by one, which is inefficient. Recent non-autoregressive translation models speed up the inference, but their quality is still inferior. In this work, we propose DSLP, a highly efficient and high-performance model for machine translation. The key insight is to train a non-autoregressive Transformer with Deep Supervision and feed additional Layer-wise Predictions. We conducted extensive experiments on four translation tasks (both directions of WMT'14 EN-DE and WMT'16 EN-RO). Results show that our approach consistently improves the BLEU scores compared with respective base models. Specifically, our best variant outperforms the autoregressive model on three translation tasks, while being 14.8 times more efficient in inference.
Simulated Annealing for Emotional Dialogue Systems
Sep 22, 2021



Explicitly modeling emotions in dialogue generation has important applications, such as building empathetic personal companions. In this study, we consider the task of expressing a specific emotion for dialogue generation. Previous approaches take the emotion as an input signal, which may be ignored during inference. We instead propose a search-based emotional dialogue system by simulated annealing (SA). Specifically, we first define a scoring function that combines contextual coherence and emotional correctness. Then, SA iteratively edits a general response and searches for a sentence with a higher score, enforcing the presence of the desired emotion. We evaluate our system on the NLPCC2017 dataset. Our proposed method shows 12% improvements in emotion accuracy compared with the previous state-of-the-art method, without hurting the generation quality (measured by BLEU).