 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Hardware Fault Tolerance in Machines with Reinforcement Learning Policy Gradient Algorithms
Jul 21, 2024



Industry is rapidly moving towards fully autonomous and interconnected systems that can detect and adapt to changing conditions, including machine hardware faults. Traditional methods for adding hardware fault tolerance to machines involve duplicating components and algorithmically reconfiguring a machine's processes when a fault occurs. However, the growing interest in reinforcement learning-based robotic control offers a new perspective on achieving hardware fault tolerance. However, limited research has explored the potential of these approaches for hardware fault tolerance in machines. This paper investigates the potential of two state-of-the-art reinforcement learning algorithms, Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC), to enhance hardware fault tolerance into machines. We assess the performance of these algorithms in two OpenAI Gym simulated environments, Ant-v2 and FetchReach-v1. Robot models in these environments are subjected to six simulated hardware faults. Additionally, we conduct an ablation study to determine the optimal method for transferring an agent's knowledge, acquired through learning in a normal (pre-fault) environment, to a (post-)fault environment in a continual learning setting. Our results demonstrate that reinforcement learning-based approaches can enhance hardware fault tolerance in simulated machines, with adaptation occurring within minutes. Specifically, PPO exhibits the fastest adaptation when retaining the knowledge within its models, while SAC performs best when discarding all acquired knowledge. Overall, this study highlights the potential of reinforcement learning-based approaches, such as PPO and SAC, for hardware fault tolerance in machines. These findings pave the way for the development of robust and adaptive machines capable of effectively operating in real-world scenarios.
Simulated Annealing for Emotional Dialogue Systems
Sep 22, 2021



Explicitly modeling emotions in dialogue generation has important applications, such as building empathetic personal companions. In this study, we consider the task of expressing a specific emotion for dialogue generation. Previous approaches take the emotion as an input signal, which may be ignored during inference. We instead propose a search-based emotional dialogue system by simulated annealing (SA). Specifically, we first define a scoring function that combines contextual coherence and emotional correctness. Then, SA iteratively edits a general response and searches for a sentence with a higher score, enforcing the presence of the desired emotion. We evaluate our system on the NLPCC2017 dataset. Our proposed method shows 12% improvements in emotion accuracy compared with the previous state-of-the-art method, without hurting the generation quality (measured by BLEU).
A Globally Normalized Neural Model for Semantic Parsing
Jun 07, 2021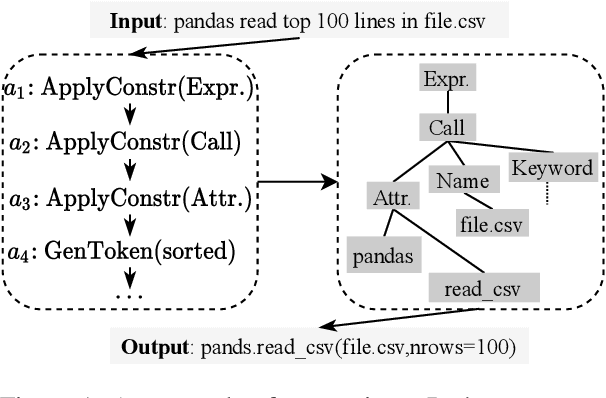
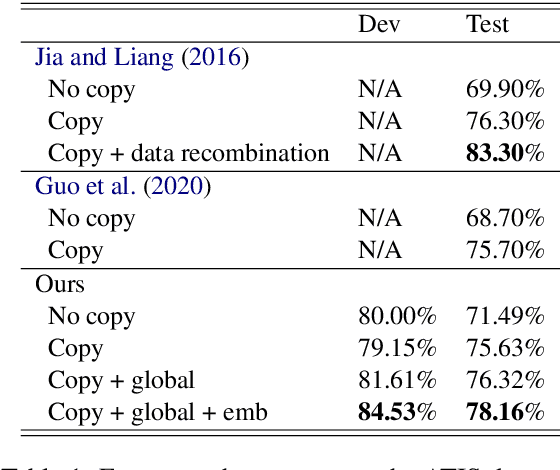
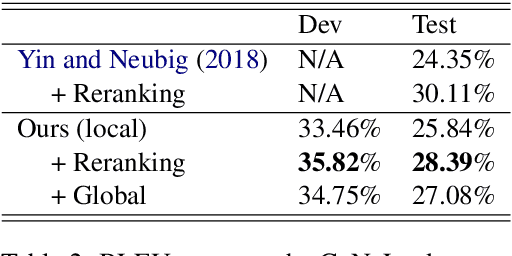

In this paper, we propose a globally normalized model for context-free grammar (CFG)-based semantic parsing. Instead of predicting a probability, our model predicts a real-valued score at each step and does not suffer from the label bias problem. Experiments show that our approach outperforms locally normalized models on small datasets, but it does not yield improvement on a large dataset.
On Generality and Knowledge Transferability in Cross-Domain Duplicate Question Detection for Heterogeneous Community Question Answering
Nov 15, 2018

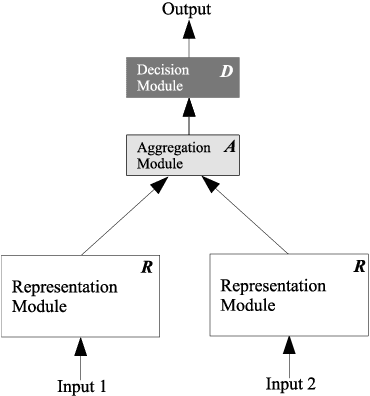
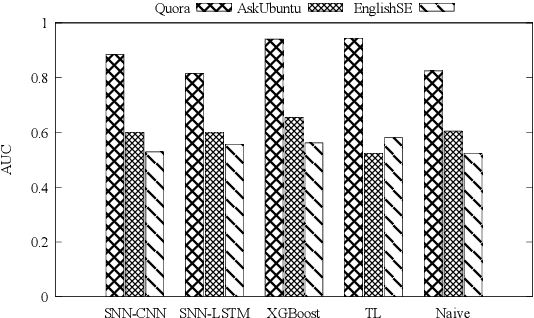
Duplicate question detection is an ongoing challenge in community question answering because semantically equivalent questions can have significantly different words and structures. In addition, the identification of duplicate questions can reduce the resources required for retrieval, when the same questions are not repeated. This study compares the performance of deep neural networks and gradient tree boosting, and explores the possibility of domain adaptation with transfer learning to improve the under-performing target domains for the text-pair duplicates classification task, using three heterogeneous datasets: general-purpose Quora, technical Ask Ubuntu, and academic English Stack Exchange. Ultimately, our study exposes the alternative hypothesis that the meaning of a "duplicate" is not inherently general-purpose, but rather is dependent on the domain of learning, hence reducing the chance of transfer learning through adapting to the domain.