 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiFloat4 Format for Language Model Pre-training on Ascend NPUs
Apr 09, 2026Large foundation models have become central to modern machine learning, with performance scaling predictably with model size and data. However, training and deploying such models incur substantial computational and memory costs, motivating the development of low-precision training techniques. Recent work has demonstrated that 4-bit floating-point (FP4) formats--such as MXFP4 and NVFP4--can be successfully applied to linear GEMM operations in large language models (LLMs), achieving up to 4x improvements in compute throughput and memory efficiency compared to higher-precision baselines. In this work, we investigate the recently proposed HiFloat4 FP4 format for Huawei Ascend NPUs and systematically compare it with MXFP4 in large-scale training settings. All experiments are conducted on Ascend NPU clusters, with linear and expert GEMM operations performed entirely in FP4 precision. We evaluate both dense architectures (e.g., Pangu and LLaMA-style models) and mixture-of-experts (MoE) models, where both standard linear layers and expert-specific GEMMs operate in FP4. Furthermore, we explore stabilization techniques tailored to FP4 training that significantly reduce numerical degradation, maintaining relative error within 1% of full-precision baselines while preserving the efficiency benefits of 4-bit computation. Our results provide a comprehensive empirical study of FP4 training on NPUs and highlight the practical trade-offs between FP4 formats in large-scale dense and MoE models.
WINFlowNets: Warm-up Integrated Networks Training of Generative Flow Networks for Robotics and Machine Fault Adaptation
Mar 18, 2026Generative Flow Networks for continuous scenarios (CFlowNets) have shown promise in solving sequential decision-making tasks by learning stochastic policies using a flow and a retrieval network. Despite their demonstrated efficiency compared to state-of-the-art Reinforcement Learning (RL) algorithms, their practical application in robotic control tasks is constrained by the reliance on pre-training the retrieval network. This dependency poses challenges in dynamic robotic environments, where pre-training data may not be readily available or representative of the current environment. This paper introduces WINFlowNets, a novel CFlowNets framework that enables the co-training of flow and retrieval networks. WINFlowNets begins with a warm-up phase for the retrieval network to bootstrap its policy, followed by a shared training architecture and a shared replay buffer for co-training both networks. Experiments in simulated robotic environments demonstrate that WINFlowNets surpasses CFlowNets and state-of-the-art RL algorithms in terms of average reward and training stability. Furthermore, WINFlowNets exhibits strong adaptive capability in fault environments, making it suitable for tasks that demand quick adaptation with limited sample data. These findings highlight WINFlowNets' potential for deployment in dynamic and malfunction-prone robotic systems, where traditional pre-training or sample inefficient data collection may be impractical.
The Evolving Landscape of LLM- and VLM-Integrated Reinforcement Learning
Feb 21, 2025



Reinforcement learning (RL) has shown impressive results in sequential decision-making tasks. Meanwhile, Large Language Models (LLMs) and Vision-Language Models (VLMs) have emerged, exhibiting impressive capabilities in multimodal understanding and reasoning. These advances have led to a surge of research integrating LLMs and VLMs into RL. In this survey, we review representative works in which LLMs and VLMs are used to overcome key challenges in RL, such as lack of prior knowledge, long-horizon planning, and reward design. We present a taxonomy that categorizes these LLM/VLM-assisted RL approaches into three roles: agent, planner, and reward. We conclude by exploring open problems, including grounding, bias mitigation, improved representations, and action advice. By consolidating existing research and identifying future directions, this survey establishes a framework for integrating LLMs and VLMs into RL, advancing approaches that unify natural language and visual understanding with sequential decision-making.
TLXML: Task-Level Explanation of Meta-Learning via Influence Functions
Jan 24, 2025



The scheme of adaptation via meta-learning is seen as an ingredient for solving the problem of data shortage or distribution shift in real-world applications, but it also brings the new risk of inappropriate updates of the model in the user environment, which increases the demand for explainability. Among the various types of XAI methods, establishing a method of explanation based on past experience in meta-learning requires special consideration due to its bi-level structure of training, which has been left unexplored. In this work, we propose influence functions for explaining meta-learning that measure the sensitivities of training tasks to adaptation and inference. We also argue that the approximation of the Hessian using the Gauss-Newton matrix resolves computational barriers peculiar to meta-learning. We demonstrate the adequacy of the method through experiments on task distinction and task distribution distinction using image classification tasks with MAML and Prototypical Network.
A Study of the Efficacy of Generative Flow Networks for Robotics and Machine Fault-Adaptation
Jan 06, 2025



Advancements in robotics have opened possibilities to automate tasks in various fields such as manufacturing, emergency response and healthcare. However, a significant challenge that prevents robots from operating in real-world environments effectively is out-of-distribution (OOD) situations, wherein robots encounter unforseen situations. One major OOD situations is when robots encounter faults, making fault adaptation essential for real-world operation for robots. Current state-of-the-art reinforcement learning algorithms show promising results but suffer from sample inefficiency, leading to low adaptation speed due to their limited ability to generalize to OOD situations. Our research is a step towards adding hardware fault tolerance and fast fault adaptability to machines. In this research, our primary focus is to investigate the efficacy of generative flow networks in robotic environments, particularly in the domain of machine fault adaptation. We simulated a robotic environment called Reacher in our experiments. We modify this environment to introduce four distinct fault environments that replicate real-world machines/robot malfunctions. The empirical evaluation of this research indicates that continuous generative flow networks (CFlowNets) indeed have the capability to add adaptive behaviors in machines under adversarial conditions. Furthermore, the comparative analysis of CFlowNets with reinforcement learning algorithms also provides some key insights into the performance in terms of adaptation speed and sample efficiency. Additionally, a separate study investigates the implications of transferring knowledge from pre-fault task to post-fault environments. Our experiments confirm that CFlowNets has the potential to be deployed in a real-world machine and it can demonstrate adaptability in case of malfunctions to maintain functionality.
Enhancing Hardware Fault Tolerance in Machines with Reinforcement Learning Policy Gradient Algorithms
Jul 21, 2024



Industry is rapidly moving towards fully autonomous and interconnected systems that can detect and adapt to changing conditions, including machine hardware faults. Traditional methods for adding hardware fault tolerance to machines involve duplicating components and algorithmically reconfiguring a machine's processes when a fault occurs. However, the growing interest in reinforcement learning-based robotic control offers a new perspective on achieving hardware fault tolerance. However, limited research has explored the potential of these approaches for hardware fault tolerance in machines. This paper investigates the potential of two state-of-the-art reinforcement learning algorithms, Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC), to enhance hardware fault tolerance into machines. We assess the performance of these algorithms in two OpenAI Gym simulated environments, Ant-v2 and FetchReach-v1. Robot models in these environments are subjected to six simulated hardware faults. Additionally, we conduct an ablation study to determine the optimal method for transferring an agent's knowledge, acquired through learning in a normal (pre-fault) environment, to a (post-)fault environment in a continual learning setting. Our results demonstrate that reinforcement learning-based approaches can enhance hardware fault tolerance in simulated machines, with adaptation occurring within minutes. Specifically, PPO exhibits the fastest adaptation when retaining the knowledge within its models, while SAC performs best when discarding all acquired knowledge. Overall, this study highlights the potential of reinforcement learning-based approaches, such as PPO and SAC, for hardware fault tolerance in machines. These findings pave the way for the development of robust and adaptive machines capable of effectively operating in real-world scenarios.
Grey-box Bayesian Optimization for Sensor Placement in Assisted Living Environments
Sep 11, 2023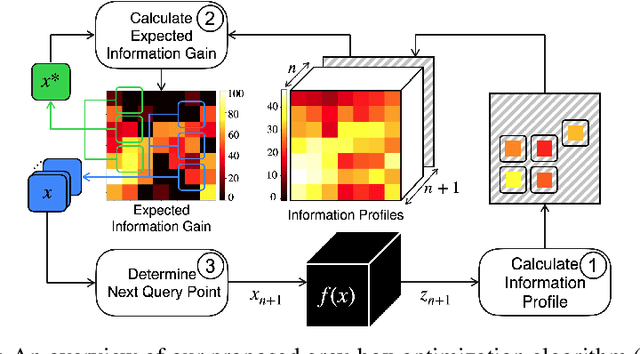

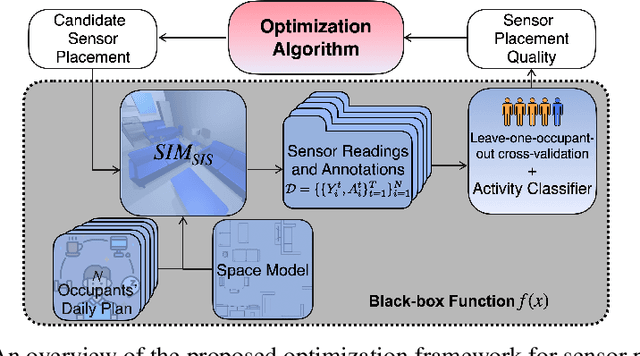
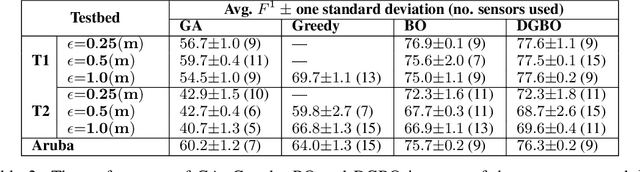
Optimizing the configuration and placement of sensors is crucial for reliable fall detection, indoor localization, and activity recognition in assisted living spaces. We propose a novel, sample-efficient approach to find a high-quality sensor placement in an arbitrary indoor space based on grey-box Bayesian optimization and simulation-based evaluation. Our key technical contribution lies in capturing domain-specific knowledge about the spatial distribution of activities and incorporating it into the iterative selection of query points in Bayesian optimization. Considering two simulated indoor environments and a real-world dataset containing human activities and sensor triggers, we show that our proposed method performs better compared to state-of-the-art black-box optimization techniques in identifying high-quality sensor placements, leading to accurate activity recognition in terms of F1-score, while also requiring a significantly lower (51.3% on average) number of expensive function queries.