 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Evolving Landscape of LLM- and VLM-Integrated Reinforcement Learning
Feb 21, 2025



Reinforcement learning (RL) has shown impressive results in sequential decision-making tasks. Meanwhile, Large Language Models (LLMs) and Vision-Language Models (VLMs) have emerged, exhibiting impressive capabilities in multimodal understanding and reasoning. These advances have led to a surge of research integrating LLMs and VLMs into RL. In this survey, we review representative works in which LLMs and VLMs are used to overcome key challenges in RL, such as lack of prior knowledge, long-horizon planning, and reward design. We present a taxonomy that categorizes these LLM/VLM-assisted RL approaches into three roles: agent, planner, and reward. We conclude by exploring open problems, including grounding, bias mitigation, improved representations, and action advice. By consolidating existing research and identifying future directions, this survey establishes a framework for integrating LLMs and VLMs into RL, advancing approaches that unify natural language and visual understanding with sequential decision-making.
Can You Improve My Code? Optimizing Programs with Local Search
Jul 10, 2023
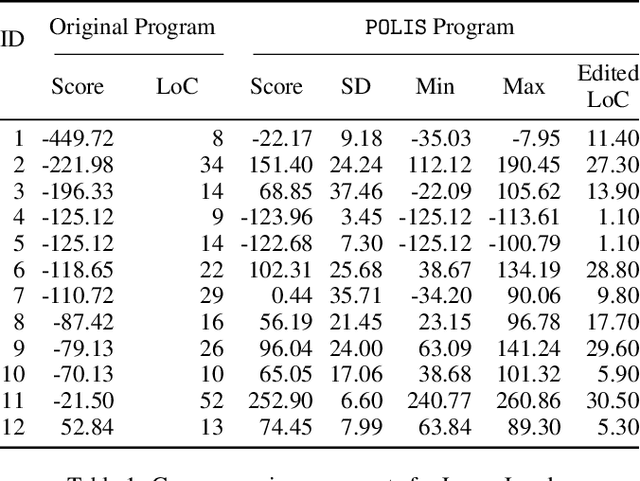

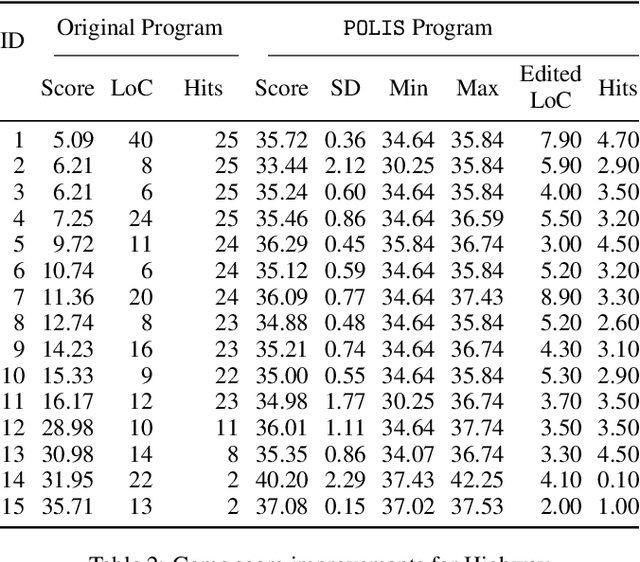
This paper introduces a local search method for improving an existing program with respect to a measurable objective. Program Optimization with Locally Improving Search (POLIS) exploits the structure of a program, defined by its lines. POLIS improves a single line of the program while keeping the remaining lines fixed, using existing brute-force synthesis algorithms, and continues iterating until it is unable to improve the program's performance. POLIS was evaluated with a 27-person user study, where participants wrote programs attempting to maximize the score of two single-agent games: Lunar Lander and Highway. POLIS was able to substantially improve the participants' programs with respect to the game scores. A proof-of-concept demonstration on existing Stack Overflow code measures applicability in real-world problems. These results suggest that POLIS could be used as a helpful programming assistant for programming problems with measurable objectives.