 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Hardware Fault Tolerance in Machines with Reinforcement Learning Policy Gradient Algorithms
Jul 21, 2024



Industry is rapidly moving towards fully autonomous and interconnected systems that can detect and adapt to changing conditions, including machine hardware faults. Traditional methods for adding hardware fault tolerance to machines involve duplicating components and algorithmically reconfiguring a machine's processes when a fault occurs. However, the growing interest in reinforcement learning-based robotic control offers a new perspective on achieving hardware fault tolerance. However, limited research has explored the potential of these approaches for hardware fault tolerance in machines. This paper investigates the potential of two state-of-the-art reinforcement learning algorithms, Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC), to enhance hardware fault tolerance into machines. We assess the performance of these algorithms in two OpenAI Gym simulated environments, Ant-v2 and FetchReach-v1. Robot models in these environments are subjected to six simulated hardware faults. Additionally, we conduct an ablation study to determine the optimal method for transferring an agent's knowledge, acquired through learning in a normal (pre-fault) environment, to a (post-)fault environment in a continual learning setting. Our results demonstrate that reinforcement learning-based approaches can enhance hardware fault tolerance in simulated machines, with adaptation occurring within minutes. Specifically, PPO exhibits the fastest adaptation when retaining the knowledge within its models, while SAC performs best when discarding all acquired knowledge. Overall, this study highlights the potential of reinforcement learning-based approaches, such as PPO and SAC, for hardware fault tolerance in machines. These findings pave the way for the development of robust and adaptive machines capable of effectively operating in real-world scenarios.
A Reinforcement Learning Based Encoder-Decoder Framework for Learning Stock Trading Rules
Jan 08, 2021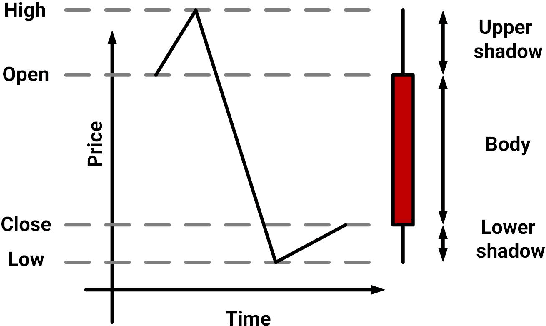
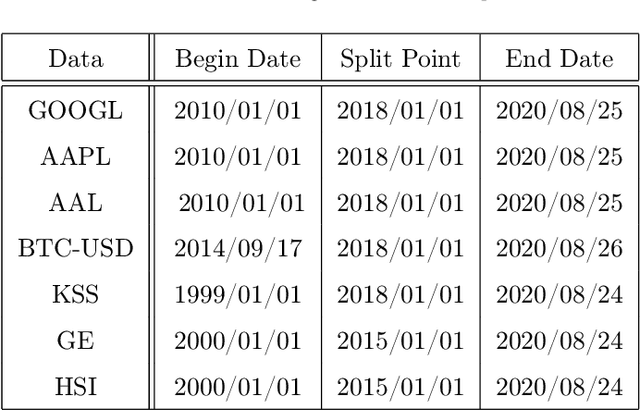
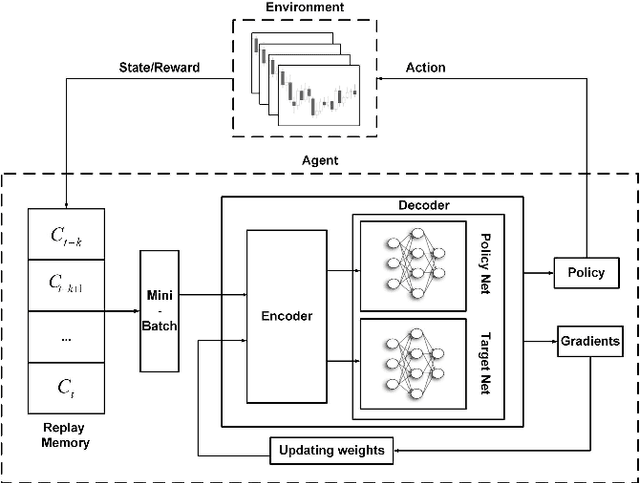
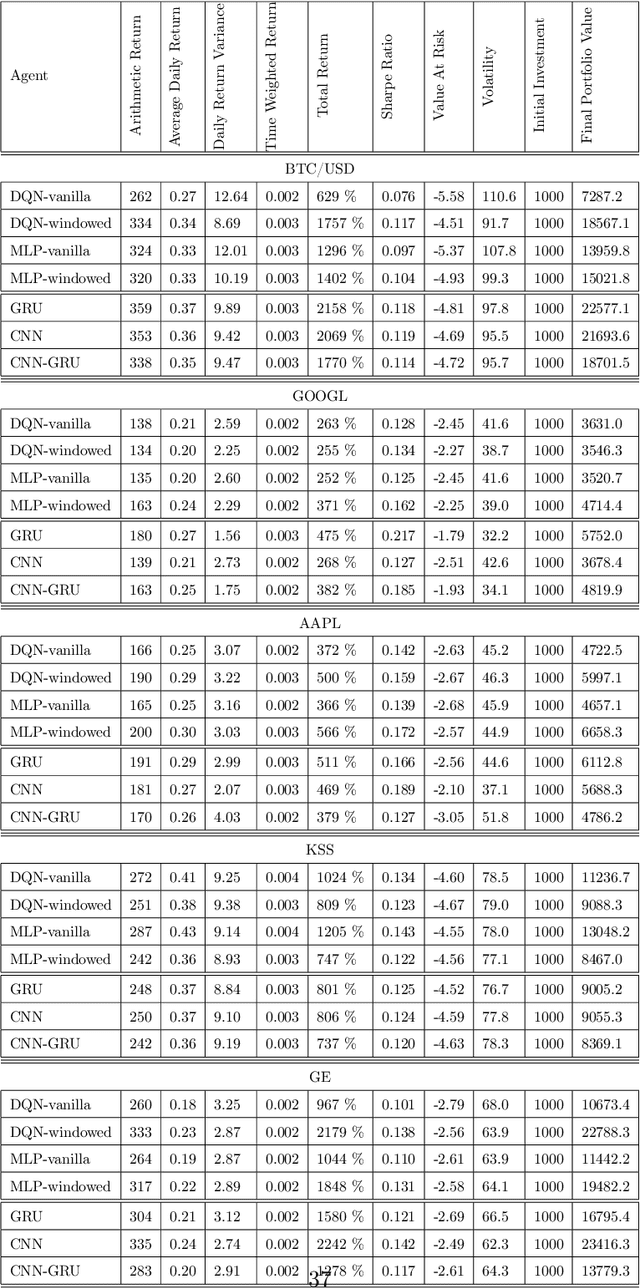
A wide variety of deep reinforcement learning (DRL) models have recently been proposed to learn profitable investment strategies. The rules learned by these models outperform the previous strategies specially in high frequency trading environments. However, it is shown that the quality of the extracted features from a long-term sequence of raw prices of the instruments greatly affects the performance of the trading rules learned by these models. Employing a neural encoder-decoder structure to extract informative features from complex input time-series has proved very effective in other popular tasks like neural machine translation and video captioning in which the models face a similar problem. The encoder-decoder framework extracts highly informative features from a long sequence of prices along with learning how to generate outputs based on the extracted features. In this paper, a novel end-to-end model based on the neural encoder-decoder framework combined with DRL is proposed to learn single instrument trading strategies from a long sequence of raw prices of the instrument. The proposed model consists of an encoder which is a neural structure responsible for learning informative features from the input sequence, and a decoder which is a DRL model responsible for learning profitable strategies based on the features extracted by the encoder. The parameters of the encoder and the decoder structures are learned jointly, which enables the encoder to extract features fitted to the task of the decoder DRL. In addition, the effects of different structures for the encoder and various forms of the input sequences on the performance of the learned strategies are investigated. Experimental results showed that the proposed model outperforms other state-of-the-art models in highly dynamic environments.
Learning Financial Asset-Specific Trading Rules via Deep Reinforcement Learning
Oct 27, 2020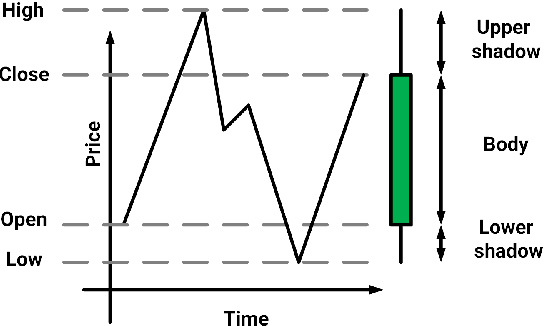
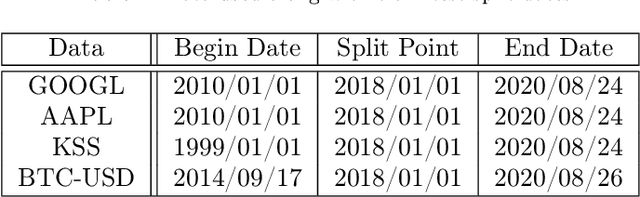
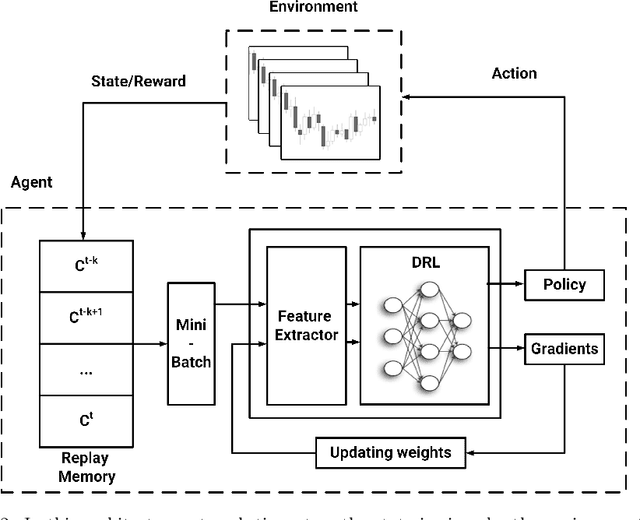
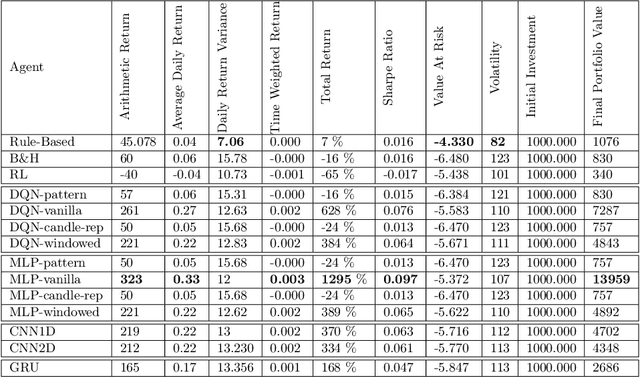
Generating asset-specific trading signals based on the financial conditions of the assets is one of the challenging problems in automated trading. Various asset trading rules are proposed experimentally based on different technical analysis techniques. However, these kind of trading strategies are profitable, extracting new asset-specific trading rules from vast historical data to increase total return and decrease the risk of portfolios is difficult for human experts. Recently, various deep reinforcement learning (DRL) methods are employed to learn the new trading rules for each asset. In this paper, a novel DRL model with various feature extraction modules is proposed. The effect of different input representations on the performance of the models is investigated and the performance of DRL-based models in different markets and asset situations is studied. The proposed model in this work outperformed the other state-of-the-art models in learning single asset-specific trading rules and obtained a total return of almost 262% in two years on a specific asset while the best state-of-the-art model get 78% on the same asset in the same time period.