 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning Based Encoder-Decoder Framework for Learning Stock Trading Rules
Jan 08, 2021
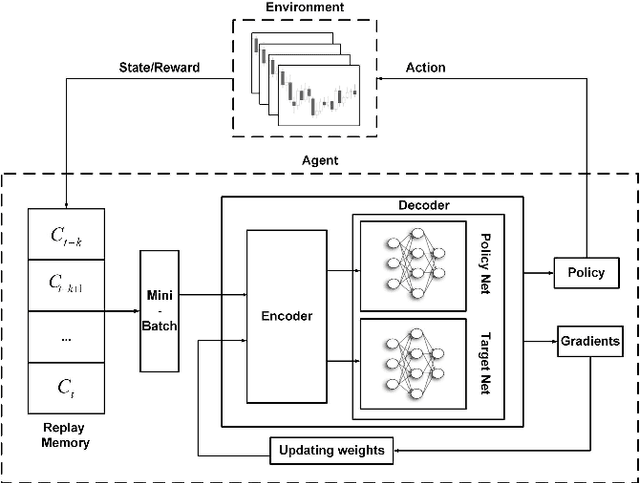
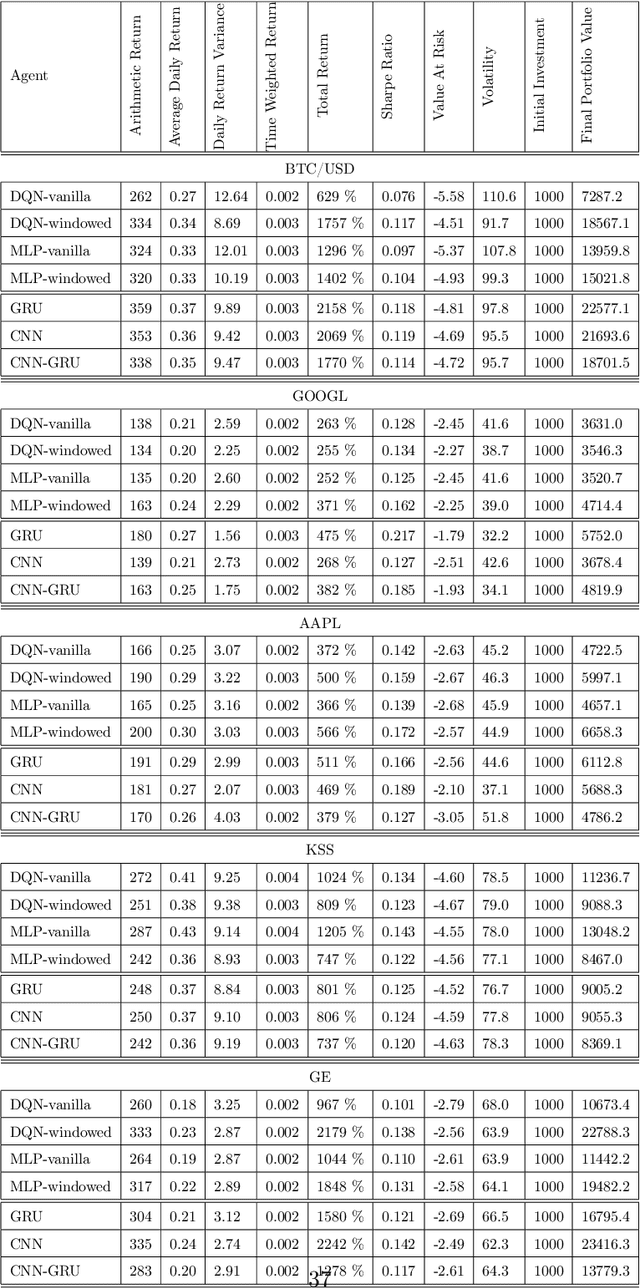
A wide variety of deep reinforcement learning (DRL) models have recently been proposed to learn profitable investment strategies. The rules learned by these models outperform the previous strategies specially in high frequency trading environments. However, it is shown that the quality of the extracted features from a long-term sequence of raw prices of the instruments greatly affects the performance of the trading rules learned by these models. Employing a neural encoder-decoder structure to extract informative features from complex input time-series has proved very effective in other popular tasks like neural machine translation and video captioning in which the models face a similar problem. The encoder-decoder framework extracts highly informative features from a long sequence of prices along with learning how to generate outputs based on the extracted features. In this paper, a novel end-to-end model based on the neural encoder-decoder framework combined with DRL is proposed to learn single instrument trading strategies from a long sequence of raw prices of the instrument. The proposed model consists of an encoder which is a neural structure responsible for learning informative features from the input sequence, and a decoder which is a DRL model responsible for learning profitable strategies based on the features extracted by the encoder. The parameters of the encoder and the decoder structures are learned jointly, which enables the encoder to extract features fitted to the task of the decoder DRL. In addition, the effects of different structures for the encoder and various forms of the input sequences on the performance of the learned strategies are investigated. Experimental results showed that the proposed model outperforms other state-of-the-art models in highly dynamic environments.
Learning Financial Asset-Specific Trading Rules via Deep Reinforcement Learning
Oct 27, 2020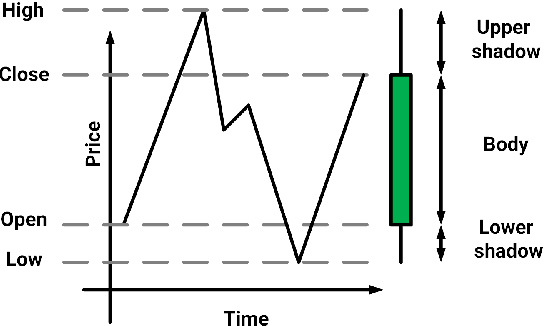
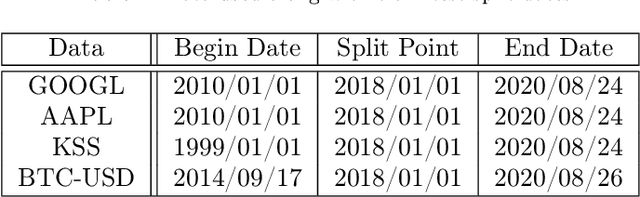
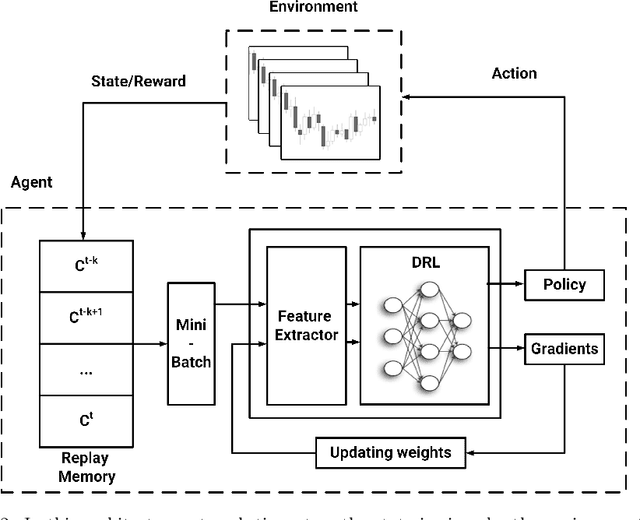
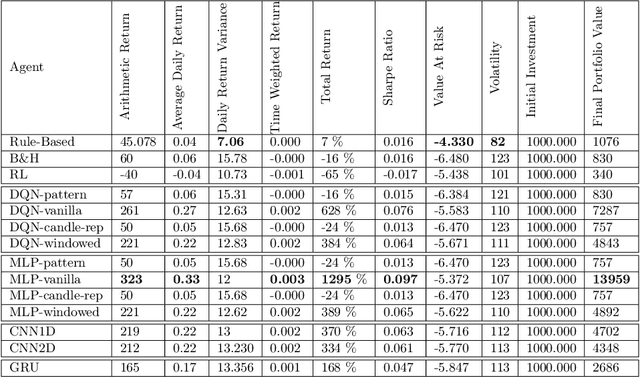
Generating asset-specific trading signals based on the financial conditions of the assets is one of the challenging problems in automated trading. Various asset trading rules are proposed experimentally based on different technical analysis techniques. However, these kind of trading strategies are profitable, extracting new asset-specific trading rules from vast historical data to increase total return and decrease the risk of portfolios is difficult for human experts. Recently, various deep reinforcement learning (DRL) methods are employed to learn the new trading rules for each asset. In this paper, a novel DRL model with various feature extraction modules is proposed. The effect of different input representations on the performance of the models is investigated and the performance of DRL-based models in different markets and asset situations is studied. The proposed model in this work outperformed the other state-of-the-art models in learning single asset-specific trading rules and obtained a total return of almost 262% in two years on a specific asset while the best state-of-the-art model get 78% on the same asset in the same time period.
A Deep Decoder Structure Based on WordEmbedding Regression for An Encoder-Decoder Based Model for Image Captioning
Jun 26, 2019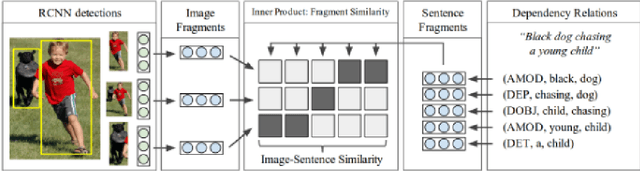
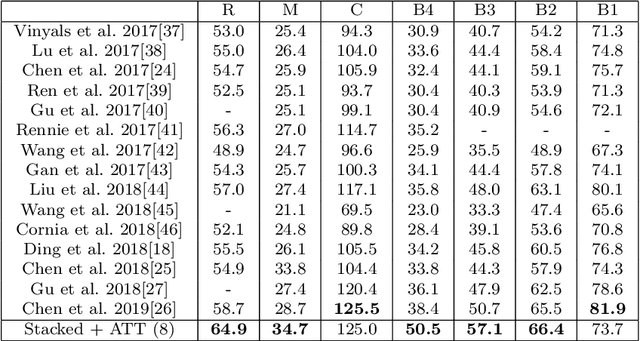

Generating textual descriptions for images has been an attractive problem for the computer vision and natural language processing researchers in recent years. Dozens of models based on deep learning have been proposed to solve this problem. The existing approaches are based on neural encoder-decoder structures equipped with the attention mechanism. These methods strive to train decoders to minimize the log likelihood of the next word in a sentence given the previous ones, which results in the sparsity of the output space. In this work, we propose a new approach to train decoders to regress the word embedding of the next word with respect to the previous ones instead of minimizing the log likelihood. The proposed method is able to learn and extract long-term information and can generate longer fine-grained captions without introducing any external memory cell. Furthermore, decoders trained by the proposed technique can take the importance of the generated words into consideration while generating captions. In addition, a novel semantic attention mechanism is proposed that guides attention points through the image, taking the meaning of the previously generated word into account. We evaluate the proposed approach with the MS-COCO dataset. The proposed model outperformed the state of the art models especially in generating longer captions. It achieved a CIDEr score equal to 125.0 and a BLEU-4 score equal to 50.5, while the best scores of the state of the art models are 117.1 and 48.0, respectively.