 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperDialseg: A Large-scale Dataset for Supervised Dialogue Segmentation
May 15, 2023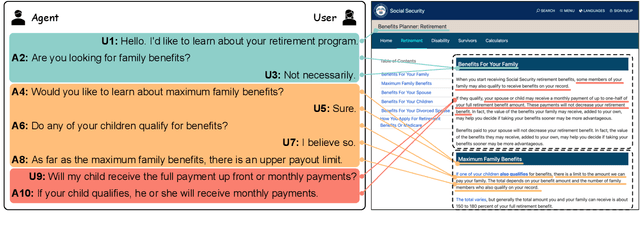
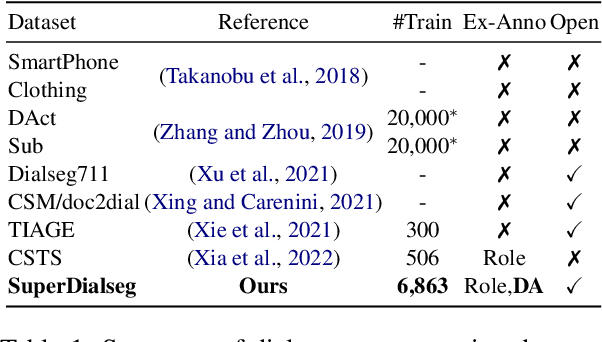
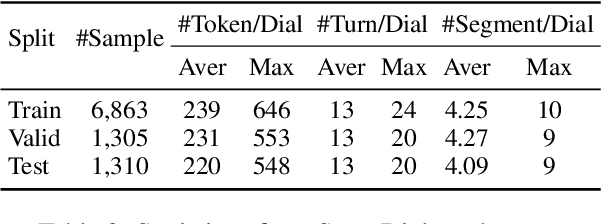
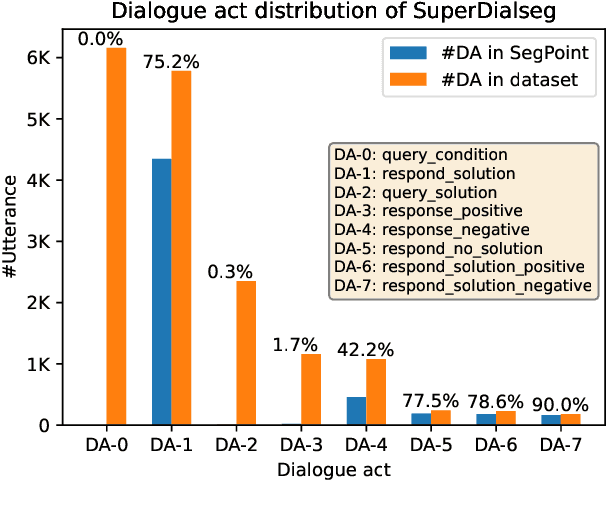
Dialogue segmentation is a crucial task for dialogue systems allowing a better understanding of conversational texts. Despite recent progress in unsupervised dialogue segmentation methods, their performances are limited by the lack of explicit supervised signals for training. Furthermore, the precise definition of segmentation points in conversations still remains as a challenging problem, increasing the difficulty of collecting manual annotations. In this paper, we provide a feasible definition of dialogue segmentation points with the help of document-grounded dialogues and release a large-scale supervised dataset called SuperDialseg, containing 9K dialogues based on two prevalent document-grounded dialogue corpora, and also inherit their useful dialogue-related annotations. Moreover, we propose two models to exploit the dialogue characteristics, achieving state-of-the-art performance on SuperDialseg and showing good generalization ability on the out-of-domain datasets. Additionally, we provide a benchmark including 20 models across four categories for the dialogue segmentation task with several proper evaluation metrics. Based on the analysis of the empirical studies, we also provide some insights for the task of dialogue segmentation. We believe our work is an important step forward in the field of dialogue segmentation.
Simulated Annealing for Emotional Dialogue Systems
Sep 22, 2021



Explicitly modeling emotions in dialogue generation has important applications, such as building empathetic personal companions. In this study, we consider the task of expressing a specific emotion for dialogue generation. Previous approaches take the emotion as an input signal, which may be ignored during inference. We instead propose a search-based emotional dialogue system by simulated annealing (SA). Specifically, we first define a scoring function that combines contextual coherence and emotional correctness. Then, SA iteratively edits a general response and searches for a sentence with a higher score, enforcing the presence of the desired emotion. We evaluate our system on the NLPCC2017 dataset. Our proposed method shows 12% improvements in emotion accuracy compared with the previous state-of-the-art method, without hurting the generation quality (measured by BLEU).